InterPReT: Interactive Policy Restructuring and Training Enable Effective Imitation Learning from Laypersons
作者: Feiyu Gavin Zhu, Jean Oh, Reid Simmons
分类: cs.AI
发布日期: 2026-02-04
备注: Proceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction
💡 一句话要点
InterPReT:交互式策略重构与训练,助力非专业人士进行有效的模仿学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 交互式学习 策略重构 用户交互 非专业人士
📋 核心要点
- 现有模仿学习方法依赖于专业人士的大规模演示和对训练过程的密切监控,这对于非专业人士来说具有挑战性。
- InterPReT通过交互式地重构策略结构和训练策略参数,使用户能够通过指令和演示来训练AI智能体。
- 用户研究表明,InterPReT在非专业人士的指导下,能够产生更鲁棒的策略,且不影响系统可用性,优于通用模仿学习基线。
📝 摘要(中文)
本文提出了一种交互式策略重构与训练(InterPReT)方法,旨在降低非专业人士训练AI智能体的门槛。该方法允许用户通过指令持续更新策略结构,并优化策略参数以拟合用户演示。这使得终端用户能够交互式地提供指令和演示,监控智能体的性能,并审查智能体的决策策略。在一项关于教AI智能体在赛车游戏中驾驶的用户研究(N=34)中,结果表明,与通用的模仿学习基线相比,当非专业人士负责提供演示和决定何时停止训练时,InterPReT能够产生更鲁棒的策略,且不影响系统的可用性。这表明该方法更适合没有太多机器学习技术背景的终端用户训练可靠的策略。
🔬 方法详解
问题定义:论文旨在解决非专业人士难以使用模仿学习训练AI智能体的问题。现有方法通常需要大量的专家演示数据和对训练过程的精细控制,这对于缺乏技术背景的普通用户来说是巨大的挑战。因此,如何设计一种易于使用、能够有效利用非专业人士提供的少量演示数据,并允许用户通过交互方式指导训练过程的模仿学习方法是本研究的核心问题。
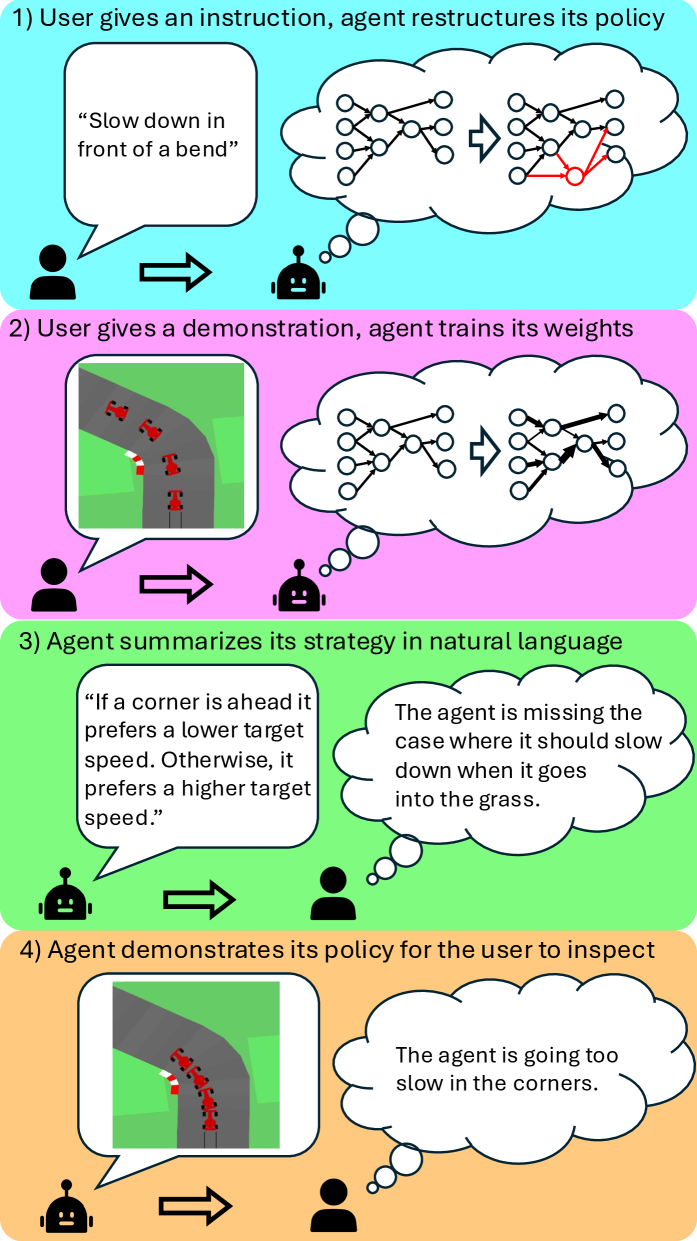
核心思路:论文的核心思路是引入交互式的策略重构和训练机制。通过允许用户提供指令来调整策略的结构,并结合用户提供的演示数据进行参数优化,使得智能体能够更好地理解用户的意图并学习到期望的行为。这种交互式的方式降低了对演示数据质量和数量的要求,同时也允许用户在训练过程中进行干预和指导,从而提高训练的效率和效果。
技术框架:InterPReT方法包含以下几个主要模块:1) 策略结构表示:采用一种可重构的策略结构,例如决策树或神经网络,允许用户通过指令修改其结构。2) 用户交互接口:提供友好的用户界面,允许用户提供指令、演示数据,并监控智能体的行为。3) 策略优化模块:根据用户提供的演示数据和指令,优化策略的参数,例如使用监督学习或强化学习算法。4) 策略评估模块:评估策略的性能,并向用户提供反馈,以便用户进行进一步的指导。整个流程是一个迭代的过程,用户不断提供指令和演示,智能体不断学习和改进,直到达到期望的性能。
关键创新:InterPReT的关键创新在于将策略重构和训练过程与用户交互紧密结合。传统的模仿学习方法通常将策略结构固定,或者需要专业的知识来进行调整。而InterPReT允许用户通过简单的指令来修改策略结构,从而更好地适应用户的意图。这种交互式的策略重构方式降低了对专业知识的要求,使得非专业人士也能够参与到策略的设计和优化过程中。
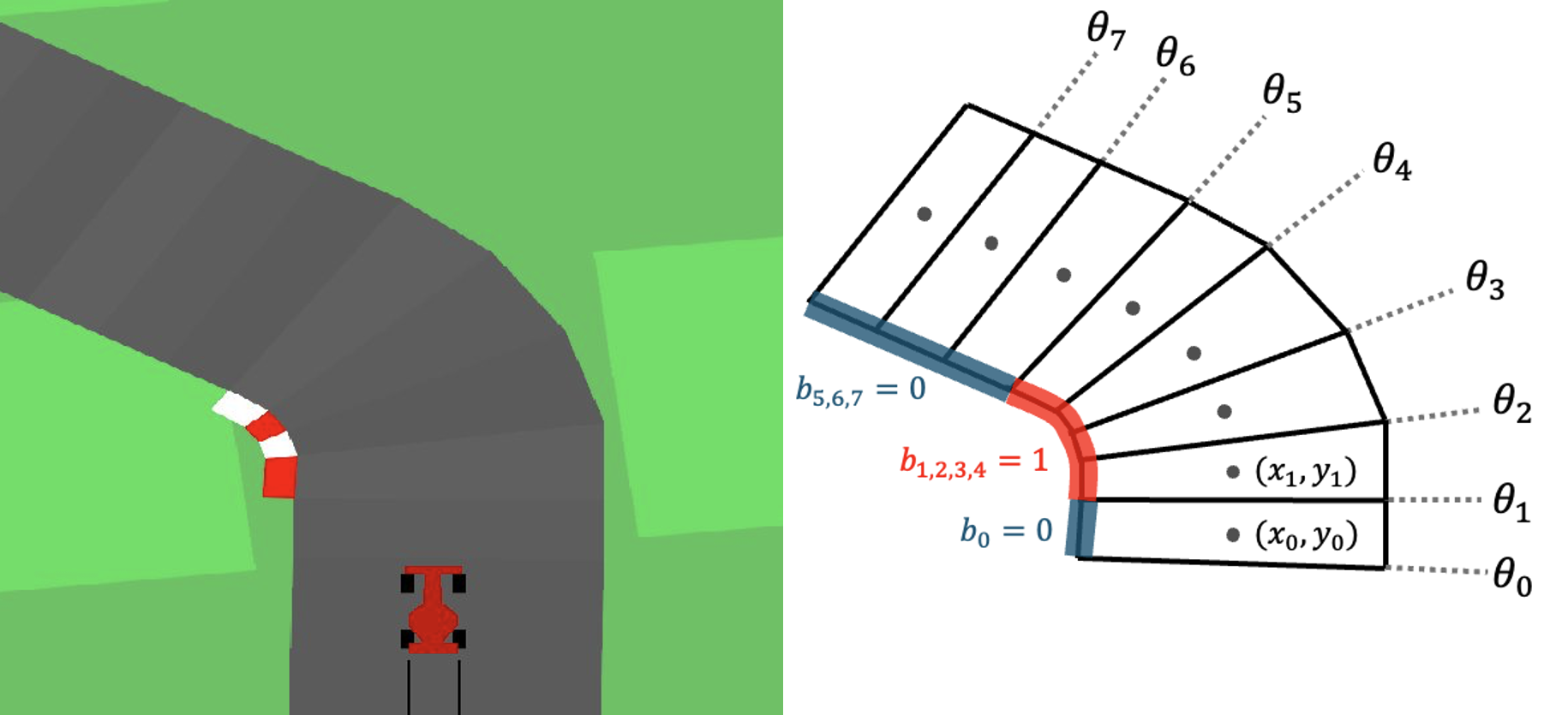
关键设计:论文中关键的设计包括:1) 策略结构的表示方式:选择合适的策略结构,例如决策树或神经网络,需要考虑其可解释性和可重构性。2) 用户指令的定义:定义一套简单易懂的指令,允许用户修改策略的结构,例如添加、删除或修改节点。3) 策略优化算法的选择:选择合适的优化算法,例如监督学习或强化学习,需要考虑其收敛速度和泛化能力。4) 用户反馈机制的设计:设计有效的用户反馈机制,例如可视化策略的决策过程,或者提供策略性能的评估指标。
🖼️ 关键图片
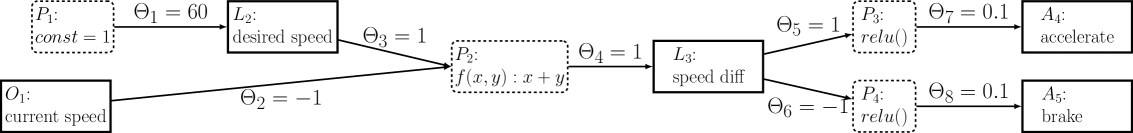
📊 实验亮点
用户研究表明,与通用的模仿学习基线相比,InterPReT在非专业人士的指导下,能够产生更鲁棒的策略,且不影响系统可用性。具体来说,在赛车游戏中,使用InterPReT训练的AI智能体能够更好地适应不同的赛道和驾驶条件,并且在面对意外情况时能够做出更合理的决策。此外,用户对InterPReT的易用性和可解释性也给予了积极评价。
🎯 应用场景
InterPReT方法具有广泛的应用前景,例如:机器人技能学习、自动驾驶策略训练、游戏AI设计等。该方法可以降低AI训练的门槛,使得非专业人士也能够参与到AI系统的开发和应用中。未来,该方法可以应用于更多领域,例如:教育、医疗、金融等,帮助人们更好地利用AI技术解决实际问题。
📄 摘要(原文)
Imitation learning has shown success in many tasks by learning from expert demonstrations. However, most existing work relies on large-scale demonstrations from technical professionals and close monitoring of the training process. These are challenging for a layperson when they want to teach the agent new skills. To lower the barrier of teaching AI agents, we propose Interactive Policy Restructuring and Training (InterPReT), which takes user instructions to continually update the policy structure and optimize its parameters to fit user demonstrations. This enables end-users to interactively give instructions and demonstrations, monitor the agent's performance, and review the agent's decision-making strategies. A user study (N=34) on teaching an AI agent to drive in a racing game confirms that our approach yields more robust policies without impairing system usability, compared to a generic imitation learning baseline, when a layperson is responsible for both giving demonstrations and determining when to stop. This shows that our method is more suitable for end-users without much technical background in machine learning to train a dependable policy