Adaptive Evidence Weighting for Audio-Spatiotemporal Fusion
作者: Oscar Ovanger, Levi Harris, Timothy H. Keitt
分类: cs.SD, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出FINCH框架以解决生物声学分类中的证据融合问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 生物声学分类 多源证据融合 自适应学习 时空上下文 机器学习
📋 核心要点
- 现有的生物声学分类方法在处理多源证据时,往往无法有效评估不同证据源的可靠性,导致性能不稳定。
- 本文提出的FINCH框架通过自适应学习每个样本的证据权重,能够动态调整上下文信息的影响,从而提高分类精度。
- FINCH在CBI数据集上实现了最先进的性能,并在BirdSet的多个子集上表现出竞争力或改进,展示了其有效性。
📝 摘要(中文)
许多机器学习系统能够访问多个证据源以进行同一预测目标的推断,但这些证据源在不同输入下的可靠性和信息量常常存在差异。在生物声学分类中,物种身份可以通过声学信号和时空上下文(如位置和季节)进行推断。本文提出了FINCH(独立条件假设下的融合),一种自适应的对数线性证据融合框架,结合了预训练的音频分类器和结构化的时空预测器。FINCH通过学习每个样本的门控函数,估计上下文信息的可靠性。实验结果表明,FINCH在多个基准测试中均优于固定权重融合和仅音频基线,提升了鲁棒性和错误权衡,尤其在上下文信息较弱时表现尤为突出。
🔬 方法详解
问题定义:本文旨在解决生物声学分类中多源证据融合的可靠性评估问题。现有方法通常依赖固定权重,无法适应不同输入的证据质量,导致分类性能不稳定。
核心思路:FINCH框架通过学习每个样本的门控函数,动态评估上下文信息的可靠性和信息量,从而实现自适应的证据融合。这种设计使得模型能够在上下文信息较弱时,仍然保持较好的分类性能。
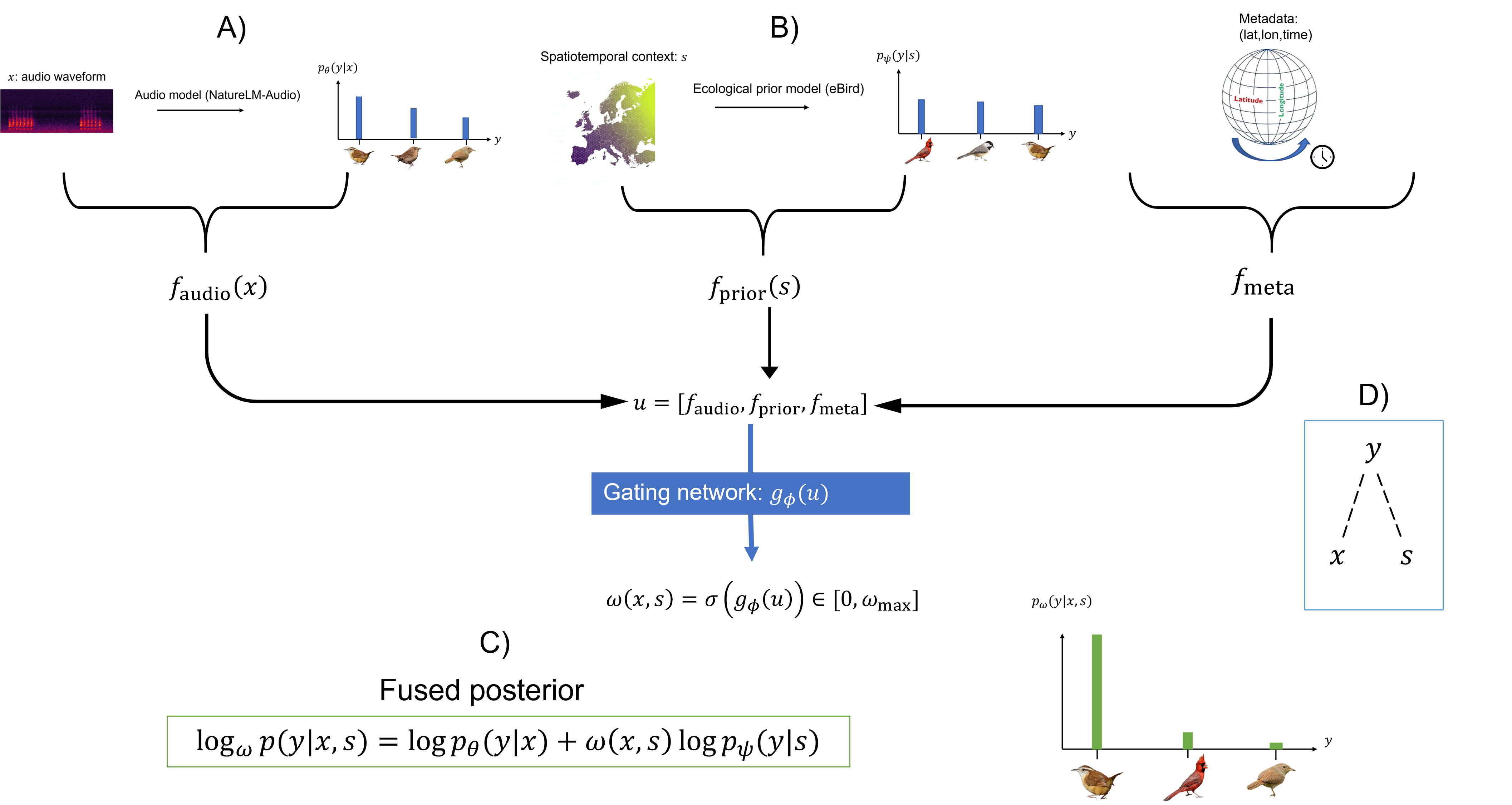
技术框架:FINCH的整体架构包括两个主要模块:预训练的音频分类器和结构化的时空预测器。通过门控函数,模型能够在融合过程中动态调整各证据源的权重。
关键创新:FINCH的主要创新在于其自适应的证据融合机制,能够根据输入的特征动态调整上下文信息的影响,与传统的固定权重融合方法有本质区别。
关键设计:在模型设计中,FINCH使用了对数线性模型来实现证据融合,并通过统计不确定性和信息量来训练门控函数,确保模型在不同场景下的鲁棒性。
🖼️ 关键图片

📊 实验亮点
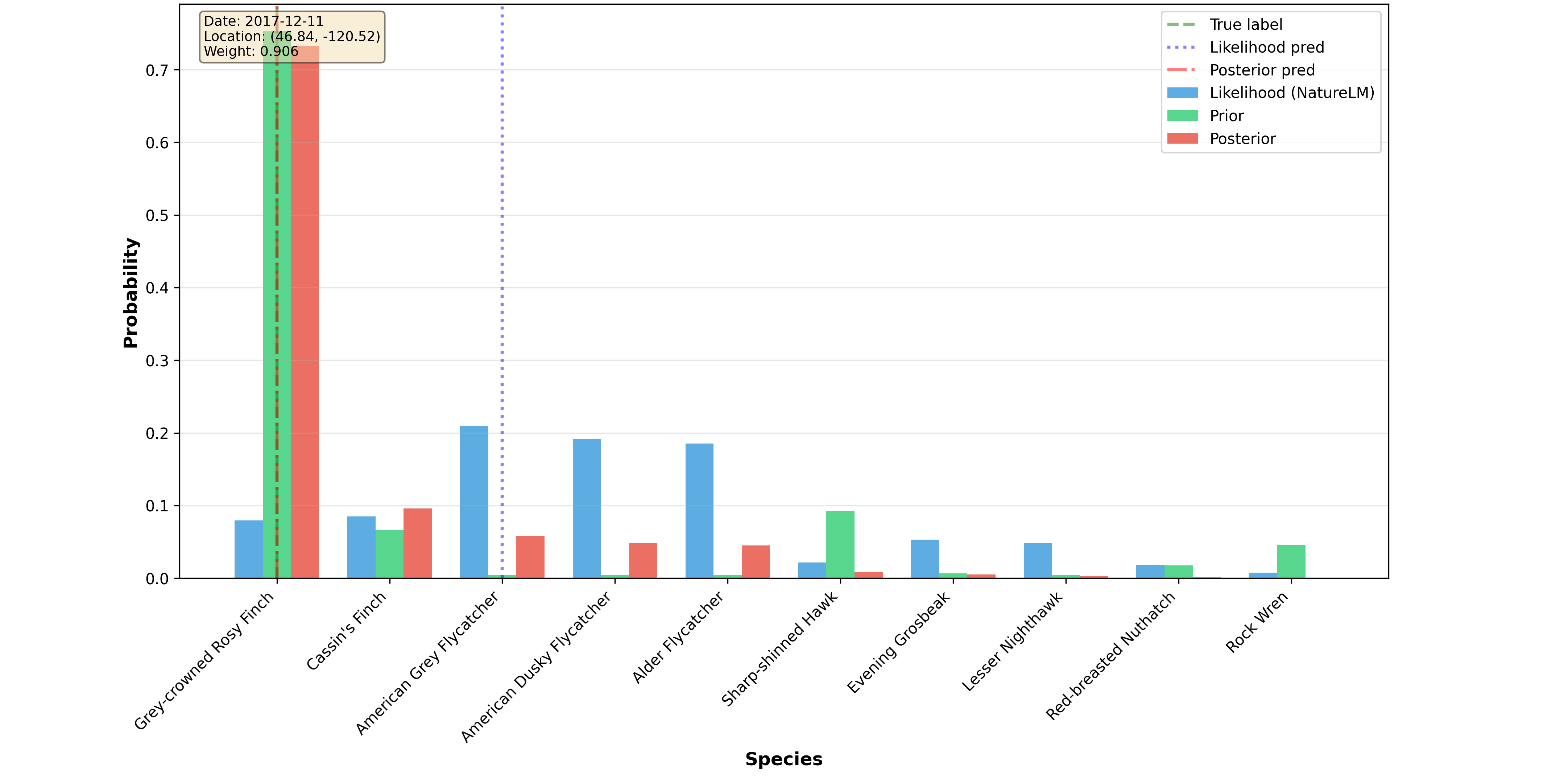
在实验中,FINCH在CBI数据集上实现了最先进的性能,相较于固定权重融合方法,提升了分类准确率,并在BirdSet的多个子集上表现出竞争力或改进,展示了其在弱上下文信息条件下的优越性。
🎯 应用场景
该研究的潜在应用领域包括生物声学监测、生态研究和环境保护等。通过提高物种识别的准确性,FINCH框架能够帮助研究人员更好地理解生态系统的动态变化,进而制定有效的保护措施。未来,该方法还可以扩展到其他多模态学习任务中,提升其在复杂环境下的应用价值。
📄 摘要(原文)
Many machine learning systems have access to multiple sources of evidence for the same prediction target, yet these sources often differ in reliability and informativeness across inputs. In bioacoustic classification, species identity may be inferred both from the acoustic signal and from spatiotemporal context such as location and season; while Bayesian inference motivates multiplicative evidence combination, in practice we typically only have access to discriminative predictors rather than calibrated generative models. We introduce \textbf{F}usion under \textbf{IN}dependent \textbf{C}onditional \textbf{H}ypotheses (\textbf{FINCH}), an adaptive log-linear evidence fusion framework that integrates a pre-trained audio classifier with a structured spatiotemporal predictor. FINCH learns a per-sample gating function that estimates the reliability of contextual information from uncertainty and informativeness statistics. The resulting fusion family \emph{contains} the audio-only classifier as a special case and explicitly bounds the influence of contextual evidence, yielding a risk-contained hypothesis class with an interpretable audio-only fallback. Across benchmarks, FINCH consistently outperforms fixed-weight fusion and audio-only baselines, improving robustness and error trade-offs even when contextual information is weak in isolation. We achieve state-of-the-art performance on CBI and competitive or improved performance on several subsets of BirdSet using a lightweight, interpretable, evidence-based approach. Code is available: \texttt{\href{https://anonymous.4open.science/r/birdnoise-85CD/README.md}{anonymous-repository}}