Conformal Thinking: Risk Control for Reasoning on a Compute Budget
作者: Xi Wang, Anushri Suresh, Alvin Zhang, Rishi More, William Jurayj, Benjamin Van Durme, Mehrdad Farajtabar, Daniel Khashabi, Eric Nalisnick
分类: cs.AI, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出基于风险控制的自适应推理框架,优化大语言模型在计算预算下的推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自适应推理 风险控制 计算预算 推理优化
📋 核心要点
- 现有大语言模型推理依赖于token预算,但如何设置预算以及自适应推理的阈值是一个挑战,需要在风险和准确性之间权衡。
- 论文将预算设置问题重新定义为风险控制问题,通过设置上下限阈值来控制推理过程,在满足风险目标的同时最小化计算量。
- 实验结果表明,该方法在多种推理任务和模型上有效,能够在满足用户指定风险目标的同时,提升计算效率。
📝 摘要(中文)
本文提出了一种基于风险控制的自适应推理框架,旨在限制错误率的同时最小化计算量。该框架通过引入一个上限阈值,在模型置信度高时停止推理(可能导致错误输出);以及一个参数化的下限阈值,用于提前停止不可解的实例(可能导致过早停止)。给定目标风险和验证集,我们使用无分布风险控制来优化这些停止机制。对于具有多个预算控制标准的场景,我们引入效率损失来选择计算效率最高的退出机制。在各种推理任务和模型上的实验结果表明,我们的风险控制方法是有效的,通过下限阈值和集成停止机制实现了计算效率的提升,同时满足了用户指定的风险目标。
🔬 方法详解
问题定义:论文旨在解决大语言模型推理过程中,如何在计算预算有限的情况下,平衡推理准确性和计算效率的问题。现有方法通常需要手动设置token预算或自适应推理的阈值,这需要在风险(错误率)和准确性之间进行权衡,缺乏一种系统性的方法来控制风险并优化计算资源的使用。
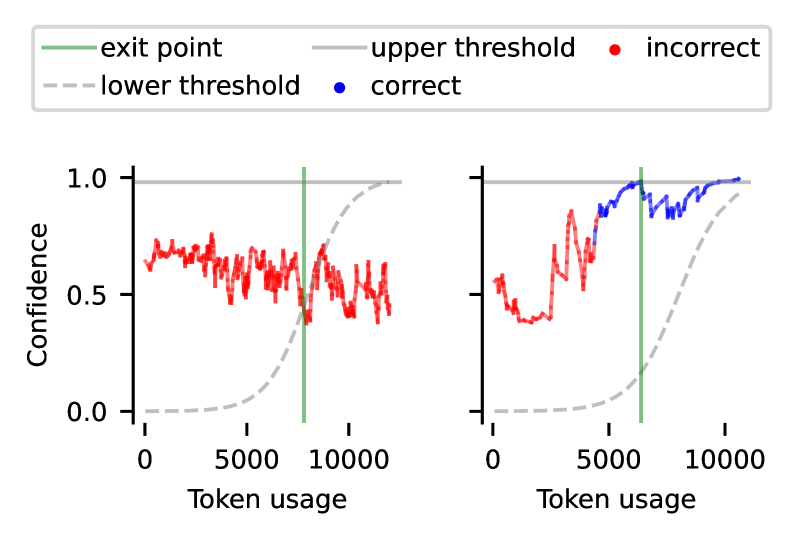
核心思路:论文的核心思路是将预算设置问题转化为风险控制问题。通过引入上限阈值和下限阈值,分别控制模型在置信度高时停止推理(避免不必要的计算),以及在问题难以解决时提前停止(避免浪费计算资源)。通过优化这两个阈值,可以在满足用户指定的风险目标下,最小化计算量。
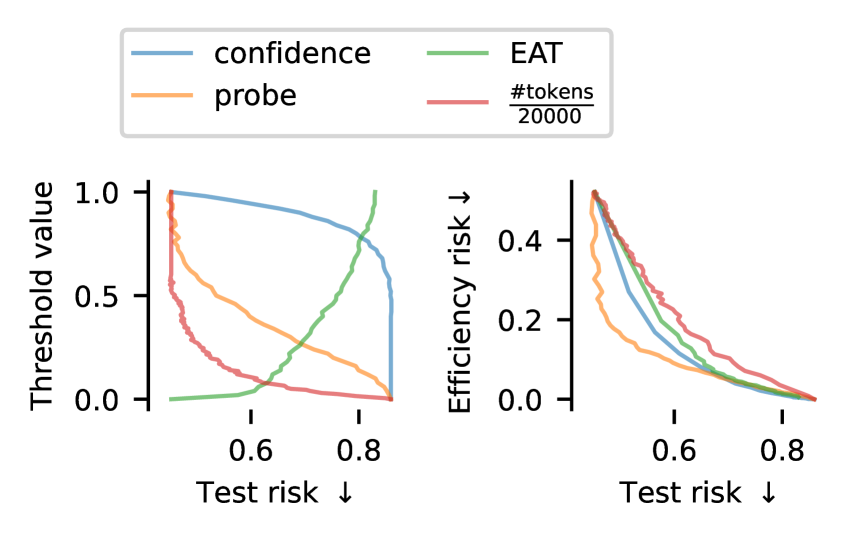
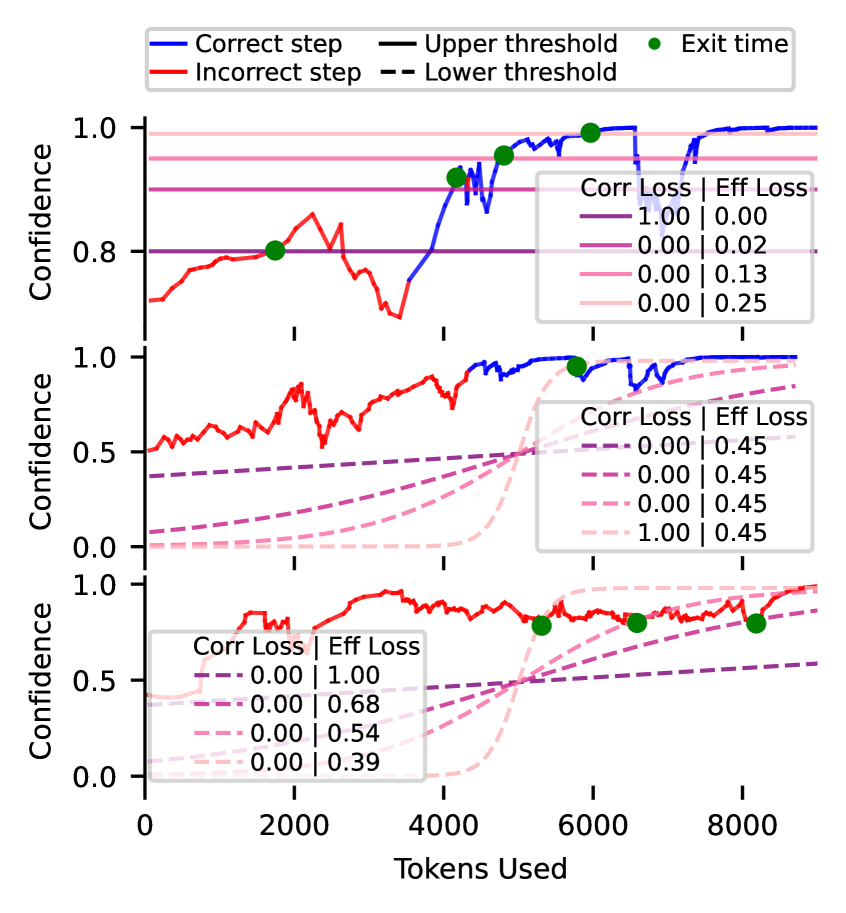
技术框架:整体框架包含以下几个主要阶段:1) 推理阶段:模型根据输入进行推理,并输出置信度得分。2) 阈值判断阶段:将模型的置信度得分与预先设定的上限阈值和下限阈值进行比较。如果置信度高于上限阈值,则停止推理并输出结果;如果置信度低于下限阈值,则提前停止推理并可能采取其他策略(例如,返回默认答案)。3) 风险控制阶段:使用验证集来评估不同阈值组合下的风险,并根据用户指定的风险目标,选择最优的阈值组合。4) 效率优化阶段:对于具有多个预算控制标准的场景,引入效率损失来选择计算效率最高的退出机制。
关键创新:论文的关键创新在于:1) 将预算设置问题重新定义为风险控制问题,提供了一种系统性的方法来平衡推理准确性和计算效率。2) 引入了参数化的下限阈值,用于提前停止不可解的实例,从而节省计算资源。3) 提出了一种基于无分布风险控制的方法,可以根据用户指定的风险目标,优化停止机制。
关键设计:论文的关键设计包括:1) 上限阈值:用于控制模型在置信度高时停止推理,避免不必要的计算。2) 下限阈值:用于提前停止不可解的实例,节省计算资源。下限阈值是参数化的,可以根据不同的问题进行调整。3) 风险控制方法:使用验证集来评估不同阈值组合下的风险,并根据用户指定的风险目标,选择最优的阈值组合。采用无分布风险控制,避免对数据分布的假设。4) 效率损失:用于在多个预算控制标准下,选择计算效率最高的退出机制。效率损失衡量了不同退出机制的计算成本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多种推理任务和模型上有效。通过引入下限阈值,可以显著减少计算量,同时满足用户指定的风险目标。例如,在某些任务上,该方法可以在保持风险不变的情况下,将计算量减少20%-30%。此外,集成停止机制可以进一步提高计算效率。
🎯 应用场景
该研究成果可应用于各种需要大语言模型进行推理的场景,尤其是在计算资源受限的情况下。例如,在移动设备上运行大语言模型、在低功耗设备上进行边缘计算、以及在需要快速响应的实时系统中,都可以利用该方法来优化推理过程,提高计算效率,并保证推理的准确性。
📄 摘要(原文)
Reasoning Large Language Models (LLMs) enable test-time scaling, with dataset-level accuracy improving as the token budget increases, motivating adaptive reasoning -- spending tokens when they improve reliability and stopping early when additional computation is unlikely to help. However, setting the token budget, as well as the threshold for adaptive reasoning, is a practical challenge that entails a fundamental risk-accuracy trade-off. We re-frame the budget setting problem as risk control, limiting the error rate while minimizing compute. Our framework introduces an upper threshold that stops reasoning when the model is confident (risking incorrect output) and a novel parametric lower threshold that preemptively stops unsolvable instances (risking premature stoppage). Given a target risk and a validation set, we use distribution-free risk control to optimally specify these stopping mechanisms. For scenarios with multiple budget controlling criteria, we incorporate an efficiency loss to select the most computationally efficient exiting mechanism. Empirical results across diverse reasoning tasks and models demonstrate the effectiveness of our risk control approach, demonstrating computational efficiency gains from the lower threshold and ensemble stopping mechanisms while adhering to the user-specified risk target.