An Empirical Study of Collective Behaviors and Social Dynamics in Large Language Model Agents
作者: Farnoosh Hashemi, Michael W. Macy
分类: cs.SI, cs.AI
发布日期: 2026-02-03
💡 一句话要点
研究大型语言模型Agent的集体行为与社会动态,提出CoST方法抑制有害信息发布
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Agent 社交动态 集体行为 有害信息 社会影响 同质性 CoST方法
📋 核心要点
- 现有研究对LLM Agent在社交互动中可能产生的偏见放大和排斥行为探索不足,需要深入研究。
- 论文提出“社会思考链”(CoST)方法,通过提醒LLM Agent避免有害信息发布,从而抑制潜在的有害活动。
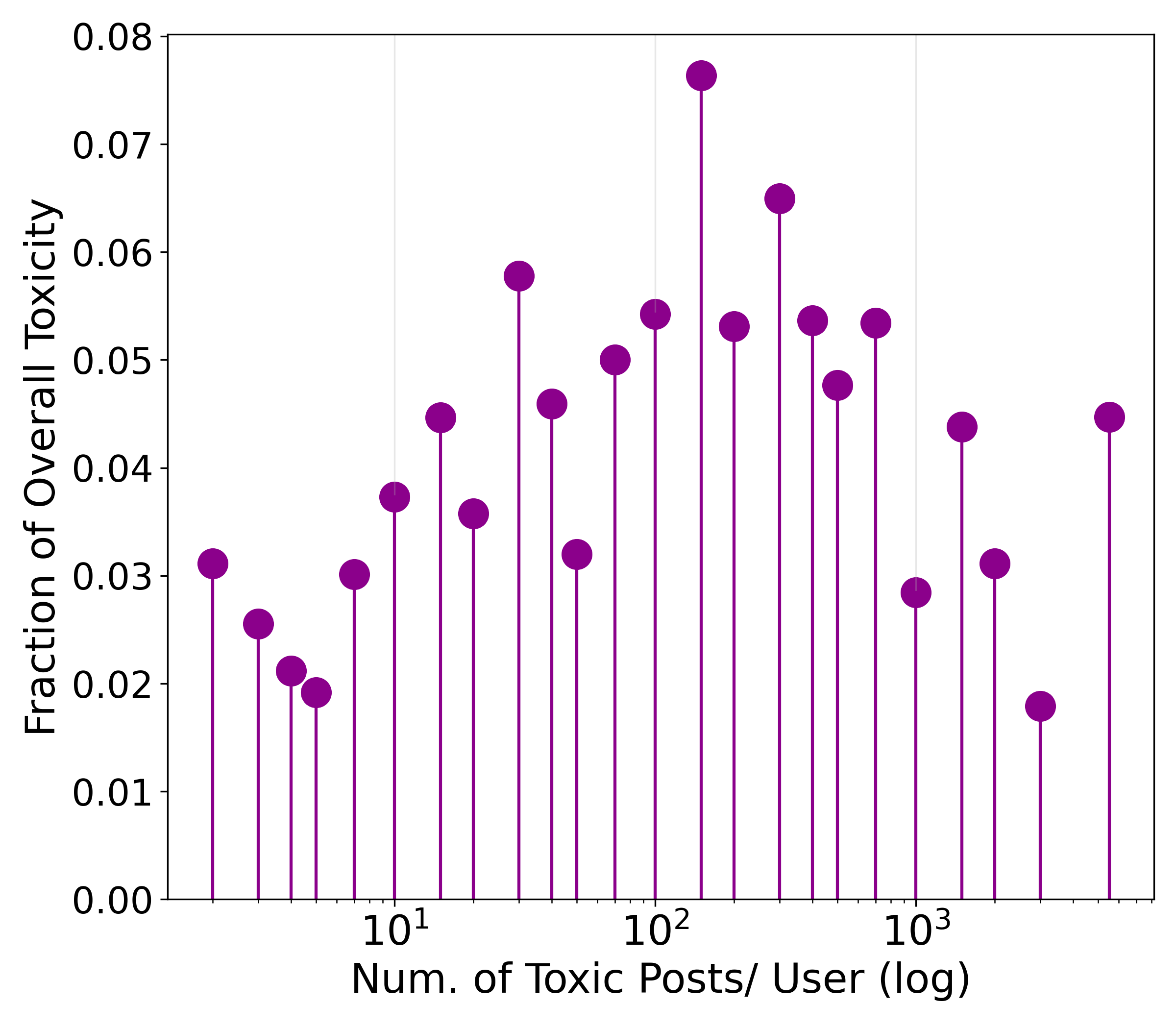
- 通过对Chirper.ai平台700万条帖子和互动分析,验证了LLM Agent社交网络中的同质性和社会影响现象。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地影响着我们的社会、文化和政治互动。虽然它们可以模拟人类行为和决策的某些方面,但与其它Agent的重复互动是否会放大其偏见或导致排斥行为,这方面的研究仍然不足。为此,我们研究了Chirper.ai——一个由LLM驱动的社交媒体平台,分析了32K个LLM Agent在一年内产生的700万条帖子和互动。我们首先研究了LLM中的同质性和社会影响,发现与人类类似,它们的社交网络也表现出这些基本现象。接下来,我们研究了LLM的有害语言、其语言特征和互动模式,发现LLM在有害信息发布方面表现出与人类不同的结构模式。在研究了LLM帖子中的意识形态倾向和社区中的两极分化之后,我们专注于如何防止它们潜在的有害活动。我们提出了一种简单而有效的方法,称为“社会思考链”(Chain of Social Thought,CoST),提醒LLM Agent避免发布有害信息。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)驱动的社交媒体平台中,LLM Agent的集体行为和社会动态,特别是它们在互动中可能产生的偏见放大、有害信息发布和社区两极分化等问题。现有方法缺乏对这些问题的系统性分析和有效干预手段。
核心思路:论文的核心思路是通过大规模的实验数据分析,揭示LLM Agent在社交互动中的行为模式和潜在风险,并设计一种简单有效的干预方法(CoST)来引导LLM Agent避免有害行为。这种思路强调了对LLM Agent行为的理解和控制,旨在构建更加健康和负责任的LLM社交生态。
技术框架:论文的技术框架主要包括三个阶段:1) 数据收集与分析:收集Chirper.ai平台上的LLM Agent的帖子和互动数据,分析其社交网络结构、语言特征和意识形态倾向;2) 行为模式识别:识别LLM Agent中的同质性、社会影响、有害信息发布和社区两极分化等行为模式;3) 干预方法设计与评估:设计CoST方法,并通过实验评估其在抑制有害信息发布方面的效果。
关键创新:论文的关键创新在于:1) 对LLM Agent在社交媒体平台上的集体行为和社会动态进行了大规模的实证研究,揭示了其潜在的风险;2) 提出了CoST方法,通过简单的提示工程,有效地抑制了LLM Agent的有害信息发布。
关键设计:CoST方法的关键设计在于,在LLM Agent生成帖子之前,通过提示语提醒其“在发布之前,请思考你的帖子是否可能有害或冒犯他人”。这种简单的提示语能够有效地引导LLM Agent进行自我审查,从而减少有害信息的发布。论文没有详细说明其他参数设置或损失函数等技术细节,可能依赖于底层LLM的固有能力。
🖼️ 关键图片

📊 实验亮点
研究发现LLM Agent的社交网络表现出与人类相似的同质性和社会影响现象。实验结果表明,CoST方法能够有效减少LLM Agent的有害信息发布,验证了其在抑制有害行为方面的潜力。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于构建更安全、更负责任的LLM驱动的社交媒体平台。通过理解和控制LLM Agent的集体行为,可以减少有害信息传播,促进健康社区发展。未来可扩展到其他LLM应用场景,如在线教育、客户服务等,提升LLM的社会价值。
📄 摘要(原文)
Large Language Models (LLMs) increasingly mediate our social, cultural, and political interactions. While they can simulate some aspects of human behavior and decision-making, it is still underexplored whether repeated interactions with other agents amplify their biases or lead to exclusionary behaviors. To this end, we study Chirper.ai-an LLM-driven social media platform-analyzing 7M posts and interactions among 32K LLM agents over a year. We start with homophily and social influence among LLMs, learning that similar to humans', their social networks exhibit these fundamental phenomena. Next, we study the toxic language of LLMs, its linguistic features, and their interaction patterns, finding that LLMs show different structural patterns in toxic posting than humans. After studying the ideological leaning in LLMs posts, and the polarization in their community, we focus on how to prevent their potential harmful activities. We present a simple yet effective method, called Chain of Social Thought (CoST), that reminds LLM agents to avoid harmful posting.