Mitigating Conversational Inertia in Multi-Turn Agents
作者: Yang Wan, Zheng Cao, Zhenhao Zhang, Zhengwen Zeng, Shuheng Shen, Changhua Meng, Linchao Zhu
分类: cs.AI, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出上下文偏好学习,缓解多轮Agent对话中的惯性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话Agent 对话惯性 上下文偏好学习 少样本学习 注意力机制
📋 核心要点
- 多轮对话Agent易受“对话惯性”影响,即过度模仿历史回复,限制探索。
- 提出上下文偏好学习,利用不同长度上下文的惯性差异构建偏好对,引导模型降低惯性。
- 实验表明,该方法能有效降低对话惯性,并在多个Agent环境中提升性能。
📝 摘要(中文)
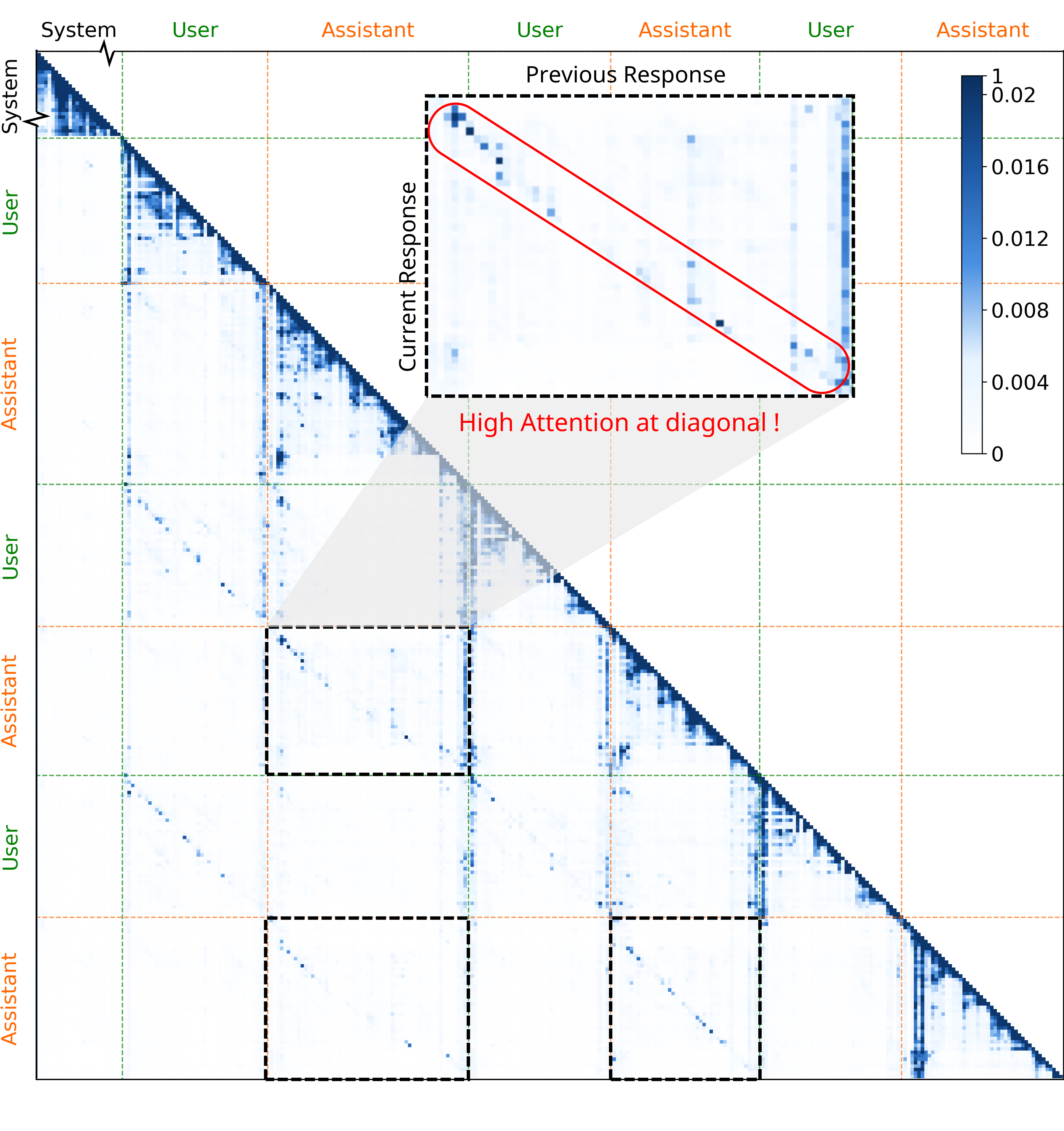
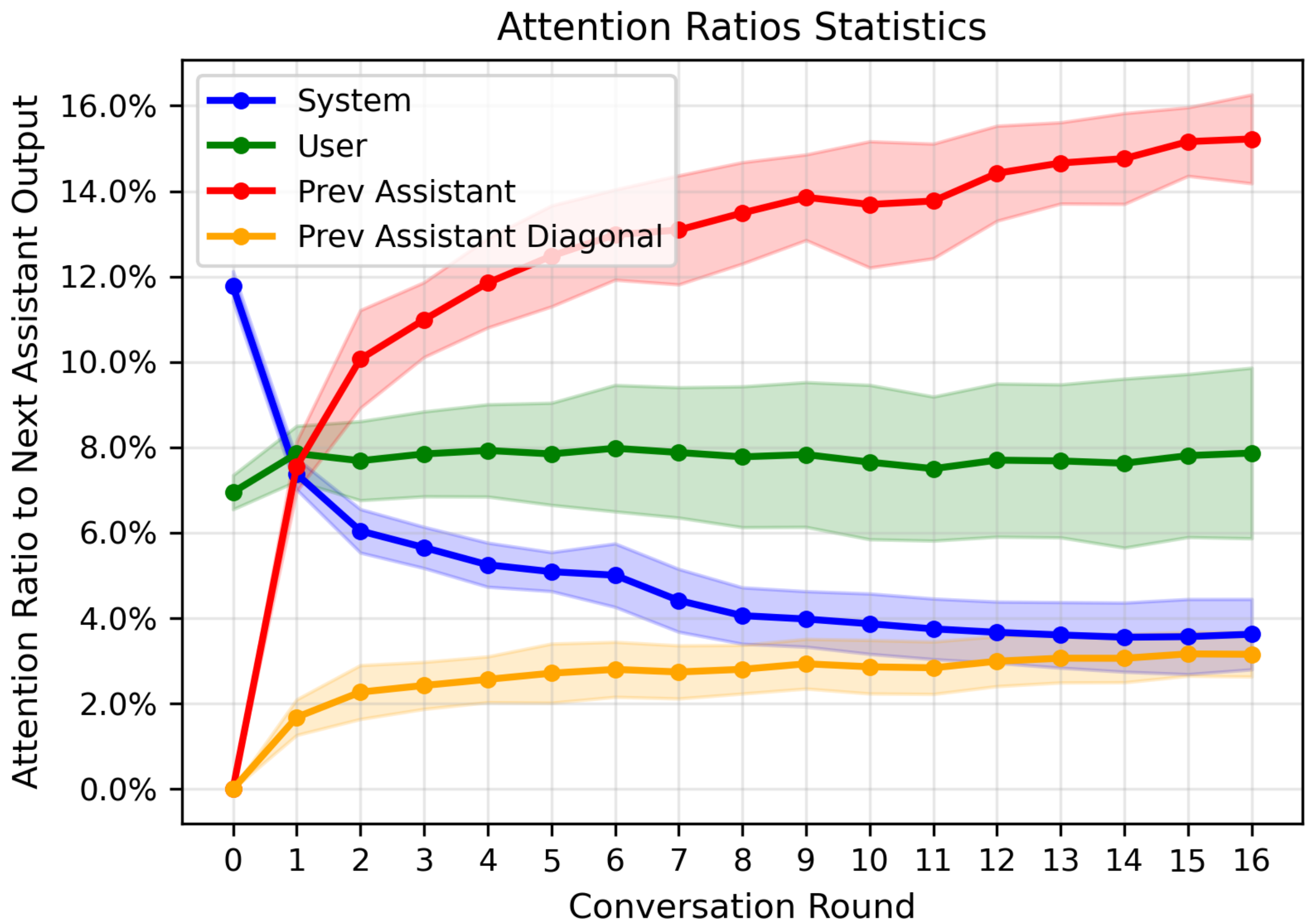
大型语言模型在提供适当的少量样本时表现出卓越的少样本学习能力,但在多轮Agent场景中,这种优势会带来问题,因为LLM会错误地模仿自己之前的响应作为少样本示例。通过注意力分析,我们发现了对话惯性现象,即模型对之前的响应表现出很强的对角注意力,这与限制探索的模仿偏差有关。这揭示了将少样本LLM转化为Agent时存在的矛盾:更长的上下文丰富了环境反馈以进行利用,但也放大了削弱探索的对话惯性。我们的关键见解是,对于相同的状态,使用更长上下文生成的动作比使用更短上下文生成的动作表现出更强的惯性,从而能够在没有环境奖励的情况下构建偏好对。基于此,我们提出了上下文偏好学习,以校准模型偏好,使其偏向于低惯性响应而不是高惯性响应。我们还在推理时提供上下文管理策略,以平衡探索和利用。在八个Agent环境和一个深度研究场景中的实验结果验证了我们的框架减少了对话惯性并实现了性能提升。
🔬 方法详解
问题定义:论文旨在解决多轮对话Agent中存在的“对话惯性”问题。现有方法,特别是基于大型语言模型(LLM)的少样本学习方法,在多轮交互中容易过度模仿之前的回复,导致探索不足,性能受限。这种惯性源于LLM对历史信息的过度依赖,尤其是在注意力机制中表现为对角注意力的增强。
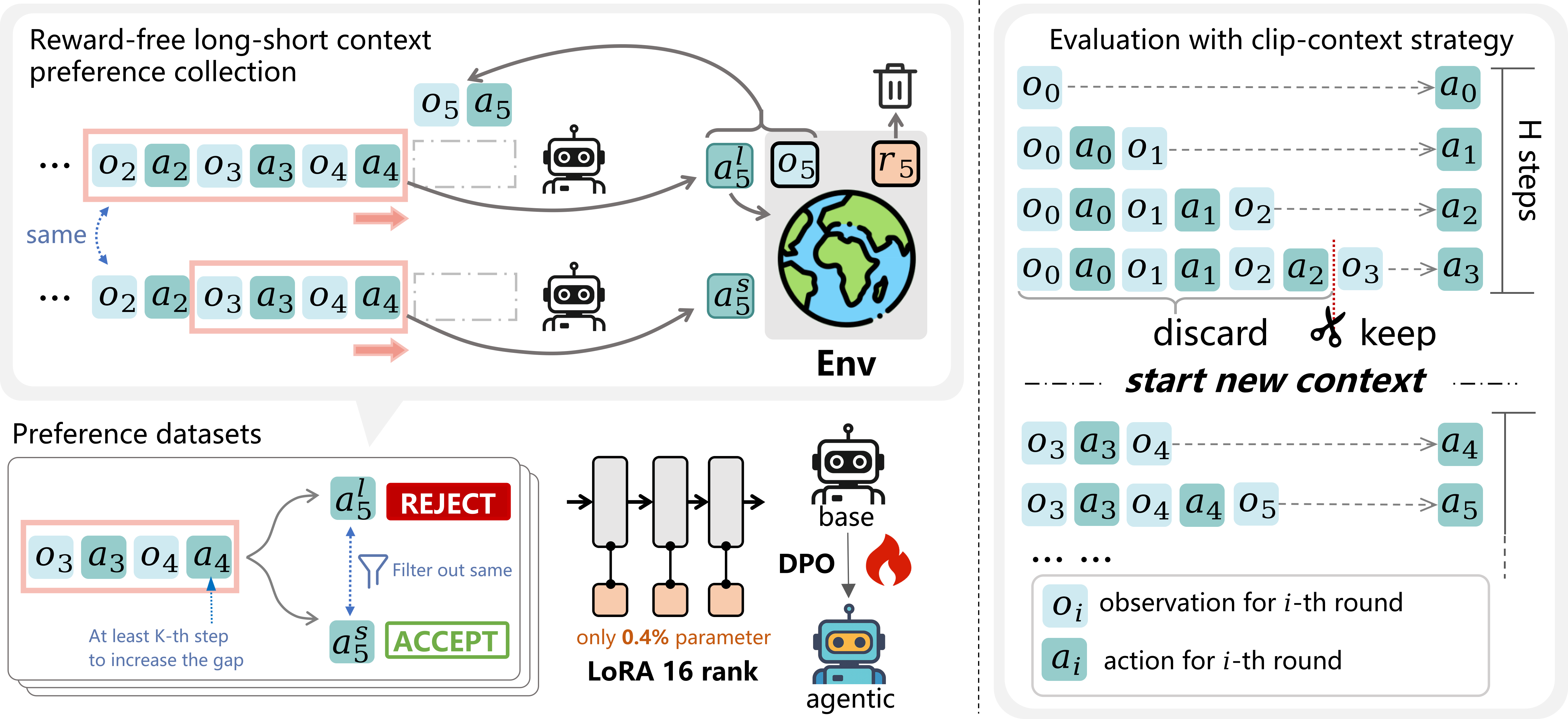
核心思路:论文的核心思路是利用不同长度上下文对Agent行为惯性的影响差异。具体来说,对于相同的状态,使用更长上下文生成的动作通常比使用更短上下文生成的动作表现出更强的惯性。因此,可以通过比较不同上下文长度下的Agent行为,构建偏好对,并训练模型偏向于低惯性行为。
技术框架:论文提出的框架主要包含两个阶段:上下文偏好学习和推理时的上下文管理。在上下文偏好学习阶段,首先收集不同上下文长度下的Agent行为数据,然后利用这些数据构建偏好对,并使用偏好学习算法(如pairwise ranking loss)训练模型。在推理阶段,采用上下文管理策略,动态调整上下文长度,以平衡探索和利用。
关键创新:论文最重要的技术创新点在于利用上下文长度与Agent行为惯性之间的关系,提出了一种无需环境奖励的偏好学习方法。这种方法避免了传统强化学习中奖励函数设计的困难,可以直接从数据中学习到降低惯性的策略。
关键设计:上下文偏好学习的关键在于如何构建有效的偏好对。论文利用不同上下文长度下Agent行为的差异,将低惯性行为作为正样本,高惯性行为作为负样本。此外,推理时的上下文管理策略也至关重要,需要根据当前状态和历史行为动态调整上下文长度,以平衡探索和利用。具体的上下文管理策略可能包括:固定长度截断、滑动窗口等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的上下文偏好学习方法在八个Agent环境和一个深度研究场景中均取得了显著的性能提升。与基线方法相比,该方法能够有效降低对话惯性,并提高Agent的探索能力和最终奖励。具体性能提升幅度取决于具体的环境和任务,但总体趋势是积极的。
🎯 应用场景
该研究成果可应用于各种多轮对话Agent系统,例如智能客服、虚拟助手、游戏AI等。通过降低对话惯性,可以提升Agent的探索能力和泛化性能,使其能够更好地适应复杂多变的环境,提供更优质的服务。此外,该方法也为解决LLM在多轮交互中的其他问题提供了新的思路。
📄 摘要(原文)
Large language models excel as few-shot learners when provided with appropriate demonstrations, yet this strength becomes problematic in multiturn agent scenarios, where LLMs erroneously mimic their own previous responses as few-shot examples. Through attention analysis, we identify conversational inertia, a phenomenon where models exhibit strong diagonal attention to previous responses, which is associated with imitation bias that constrains exploration. This reveals a tension when transforming few-shot LLMs into agents: longer context enriches environmental feedback for exploitation, yet also amplifies conversational inertia that undermines exploration. Our key insight is that for identical states, actions generated with longer contexts exhibit stronger inertia than those with shorter contexts, enabling construction of preference pairs without environment rewards. Based on this, we propose Context Preference Learning to calibrate model preferences to favor low-inertia responses over highinertia ones. We further provide context management strategies at inference time to balance exploration and exploitation. Experimental results across eight agentic environments and one deep research scenario validate that our framework reduces conversational inertia and achieves performance improvements.