Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration
作者: Bowei He, Minda Hu, Zenan Xu, Hongru Wang, Licheng Zong, Yankai Chen, Chen Ma, Xue Liu, Pluto Zhou, Irwin King
分类: cs.AI, cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出Search-R2以解决搜索集成推理中的多尺度信用分配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 搜索集成推理 强化学习 演员-修正者协作 多尺度信用分配 问答系统
📋 核心要点
- 现有的搜索集成推理方法在训练过程中面临多尺度信用分配问题,导致无法有效区分高质量推理与偶然猜测。
- 本文提出的Search-R2框架通过演员-修正者协作,优化推理过程,采用切割与再生成机制修复错误步骤。
- 实验结果表明,Search-R2在多种问答数据集上超越了强基线,显著提高了推理准确性,且计算开销较小。
📝 摘要(中文)
搜索集成推理使语言代理能够通过主动查询外部资源超越静态参数知识。然而,通过强化学习训练这些代理时,面临多尺度信用分配问题:现有方法通常依赖稀疏的轨迹级奖励,无法区分高质量推理与偶然猜测,导致冗余或误导的搜索行为。为此,本文提出了Search-R2,一个新颖的演员-修正者协作框架,通过目标干预增强推理,两个组件在训练过程中共同优化。该方法将生成过程分解为演员生成初始推理轨迹,元修正者通过“切割与再生成”机制选择性地诊断和修复错误步骤。为提供细粒度监督,本文引入了一种混合奖励设计,将结果正确性与量化检索证据信息密度的密集过程奖励结合。理论上,我们将演员-修正者交互形式化为平滑混合策略,证明选择性修正相较于强基线具有严格的性能提升。大量实验表明,Search-R2在各种通用和多跳问答数据集上始终优于强大的RAG和基于RL的基线,取得了更高的推理准确性且开销最小。
🔬 方法详解
问题定义:本文旨在解决搜索集成推理中的多尺度信用分配问题,现有方法依赖稀疏的轨迹级奖励,难以有效评估推理质量,导致冗余和误导的搜索行为。
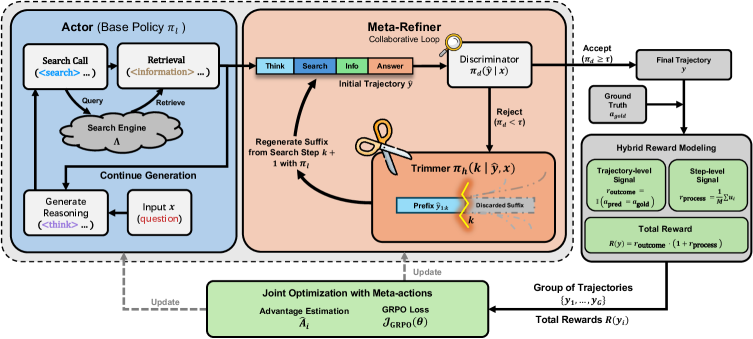
核心思路:提出Search-R2框架,通过演员-修正者协作,优化推理过程。演员负责生成初始推理轨迹,而修正者则通过选择性干预修复错误,提升推理质量。
技术框架:Search-R2框架包含两个主要模块:演员和元修正者。演员生成初步推理,元修正者通过“切割与再生成”机制对错误步骤进行诊断和修复,二者在训练过程中共同优化。
关键创新:最重要的创新在于引入了演员-修正者的协作机制和混合奖励设计,前者通过选择性修正提升推理质量,后者结合了结果正确性与信息密度,提供了更细致的监督。
关键设计:在奖励设计中,结合了结果的正确性和检索证据的信息密度,确保了对推理过程的细粒度评估。此外,采用了平滑混合策略来形式化演员-修正者的交互,确保了选择性修正的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Search-R2在多个通用和多跳问答数据集上均优于强大的RAG和基于RL的基线,推理准确性显著提升,且计算开销保持在最低水平,展现出良好的实用性和效率。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话系统和信息检索等。通过提升推理准确性,Search-R2能够为用户提供更为精准和相关的信息,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Search-integrated reasoning enables language agents to transcend static parametric knowledge by actively querying external sources. However, training these agents via reinforcement learning is hindered by the multi-scale credit assignment problem: existing methods typically rely on sparse, trajectory-level rewards that fail to distinguish between high-quality reasoning and fortuitous guesses, leading to redundant or misleading search behaviors. To address this, we propose Search-R2, a novel Actor-Refiner collaboration framework that enhances reasoning through targeted intervention, with both components jointly optimized during training. Our approach decomposes the generation process into an Actor, which produces initial reasoning trajectories, and a Meta-Refiner, which selectively diagnoses and repairs flawed steps via a 'cut-and-regenerate' mechanism. To provide fine-grained supervision, we introduce a hybrid reward design that couples outcome correctness with a dense process reward quantifying the information density of retrieved evidence. Theoretically, we formalize the Actor-Refiner interaction as a smoothed mixture policy, proving that selective correction yields strict performance gains over strong baselines. Extensive experiments across various general and multi-hop QA datasets demonstrate that Search-R2 consistently outperforms strong RAG and RL-based baselines across model scales, achieving superior reasoning accuracy with minimal overhead.