Persona Generators: Generating Diverse Synthetic Personas at Scale
作者: Davide Paglieri, Logan Cross, William A. Cunningham, Joel Z. Leibo, Alexander Sasha Vezhnevets
分类: cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出Persona Generators,利用进化算法生成多样化合成角色,用于AI系统评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成角色生成 进化算法 大型语言模型 AI系统评估 多样性覆盖
📋 核心要点
- 现有AI系统评估依赖真实人类数据,但数据收集成本高、覆盖范围有限,尤其是在新场景下。
- 论文提出Persona Generators,利用进化算法优化LLM,生成多样化、覆盖长尾行为的合成角色。
- 实验表明,该方法在多样性指标上显著优于现有基线,能生成包含罕见特征组合的角色。
📝 摘要(中文)
评估与人类交互的AI系统需要在多样化的用户群体中理解其行为,但收集具有代表性的人类数据通常成本高昂或不可行,尤其是在新技术或假设的未来场景中。生成式Agent建模的最新研究表明,大型语言模型可以高保真地模拟类人合成角色,准确地重现特定个体的信念和行为。然而,大多数方法需要关于目标群体的详细数据,并且通常优先考虑密度匹配(复制最可能发生的事情)而不是支持覆盖(涵盖可能发生的事情),导致长尾行为未被充分探索。我们引入了Persona Generators,它可以生成针对任意上下文定制的多样化合成人群。我们应用基于AlphaEvolve的迭代改进循环,使用大型语言模型作为变异算子,在数百次迭代中改进我们的Persona Generator代码。优化过程产生了轻量级的Persona Generators,可以自动将小型描述扩展为多样化的合成角色人群,从而最大限度地覆盖相关多样性轴上的观点和偏好。我们证明,进化的生成器在六个多样性指标上显著优于现有基线,产生的人群跨越了标准LLM输出中难以实现的罕见特征组合。
🔬 方法详解
问题定义:现有方法在生成合成角色时,往往依赖于详细的目标群体数据,并且侧重于密度匹配,即复制最常见的行为模式。这导致长尾行为被忽略,无法充分覆盖所有可能的个体特征和偏好,从而限制了AI系统在多样化场景下的评估效果。
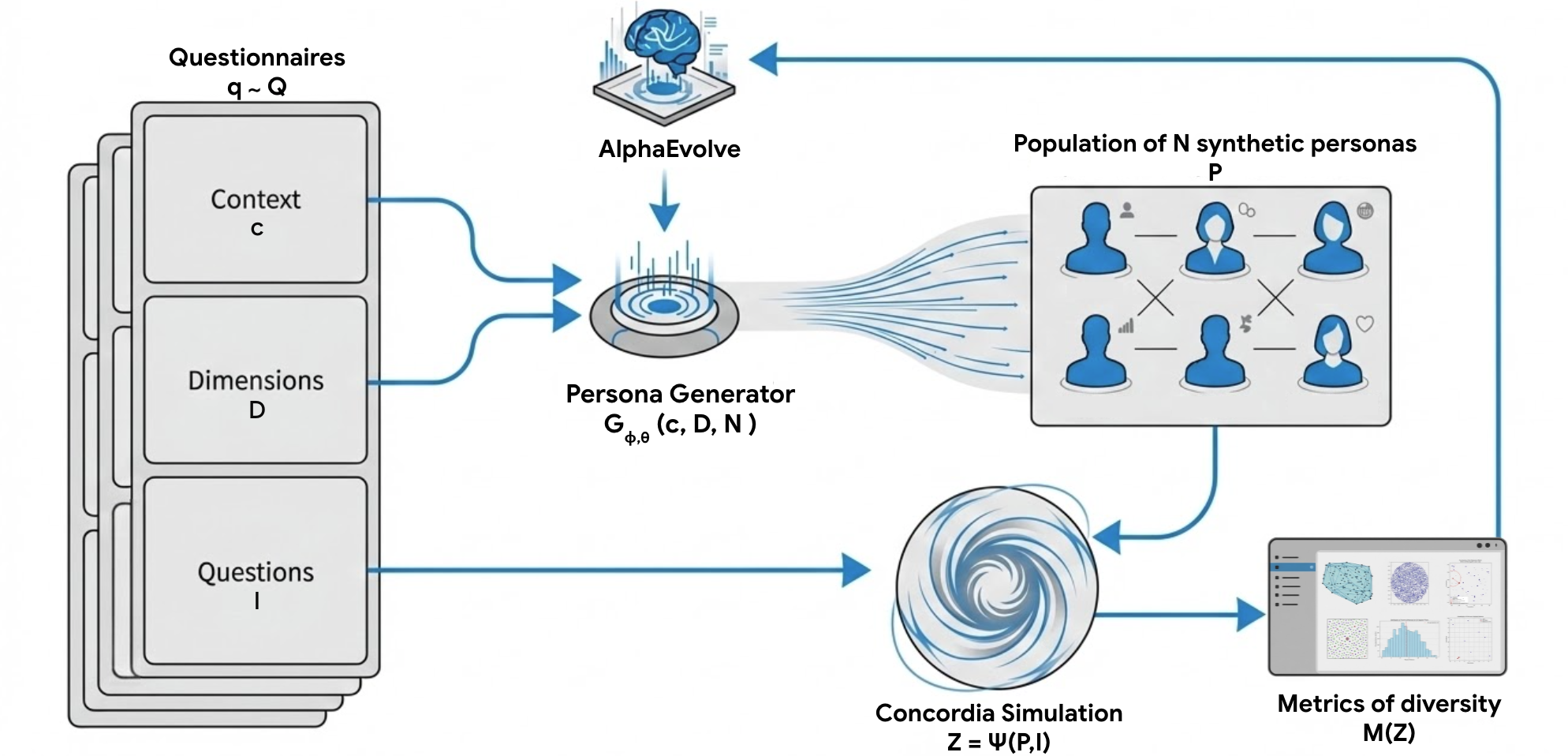
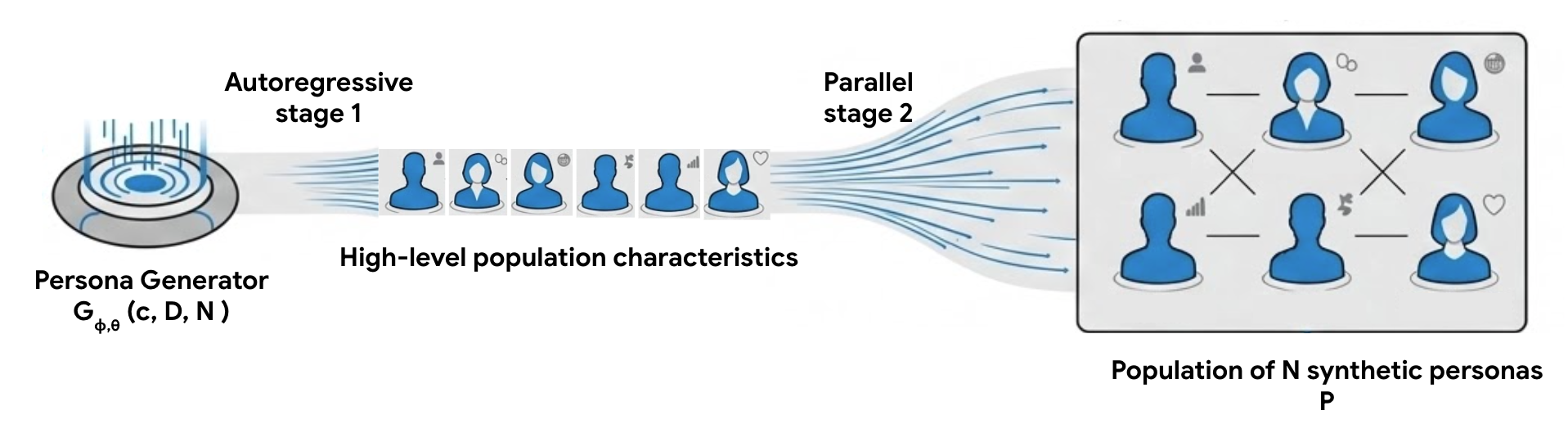
核心思路:论文的核心思路是利用进化算法(AlphaEvolve)来迭代优化Persona Generator的代码。Persona Generator本质上是一个函数,它接收少量描述作为输入,并生成多样化的合成角色。通过进化算法,可以不断改进这个函数,使其能够生成更具多样性、更能覆盖长尾行为的角色。
技术框架:整体框架包含以下几个主要步骤:1) 定义初始的Persona Generator;2) 使用LLM作为变异算子,对Persona Generator的代码进行变异,生成新的Persona Generator;3) 使用多样性指标评估新生成的Persona Generator的性能;4) 根据评估结果,选择表现最好的Persona Generator作为下一轮迭代的起点;5) 重复步骤2-4,直到达到预定的迭代次数或性能指标。
关键创新:最重要的技术创新点在于将进化算法与大型语言模型相结合,用于优化Persona Generator。这种方法能够自动探索和发现生成多样化合成角色的有效策略,而无需人工干预。与现有方法相比,该方法能够更好地覆盖长尾行为,生成更具代表性的合成人群。
关键设计:论文使用了AlphaEvolve算法,这是一种基于策略梯度强化学习的进化算法。LLM被用作变异算子,负责生成新的Persona Generator代码。多样性指标用于评估生成角色的多样性,例如覆盖率、熵等。具体的参数设置和网络结构在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
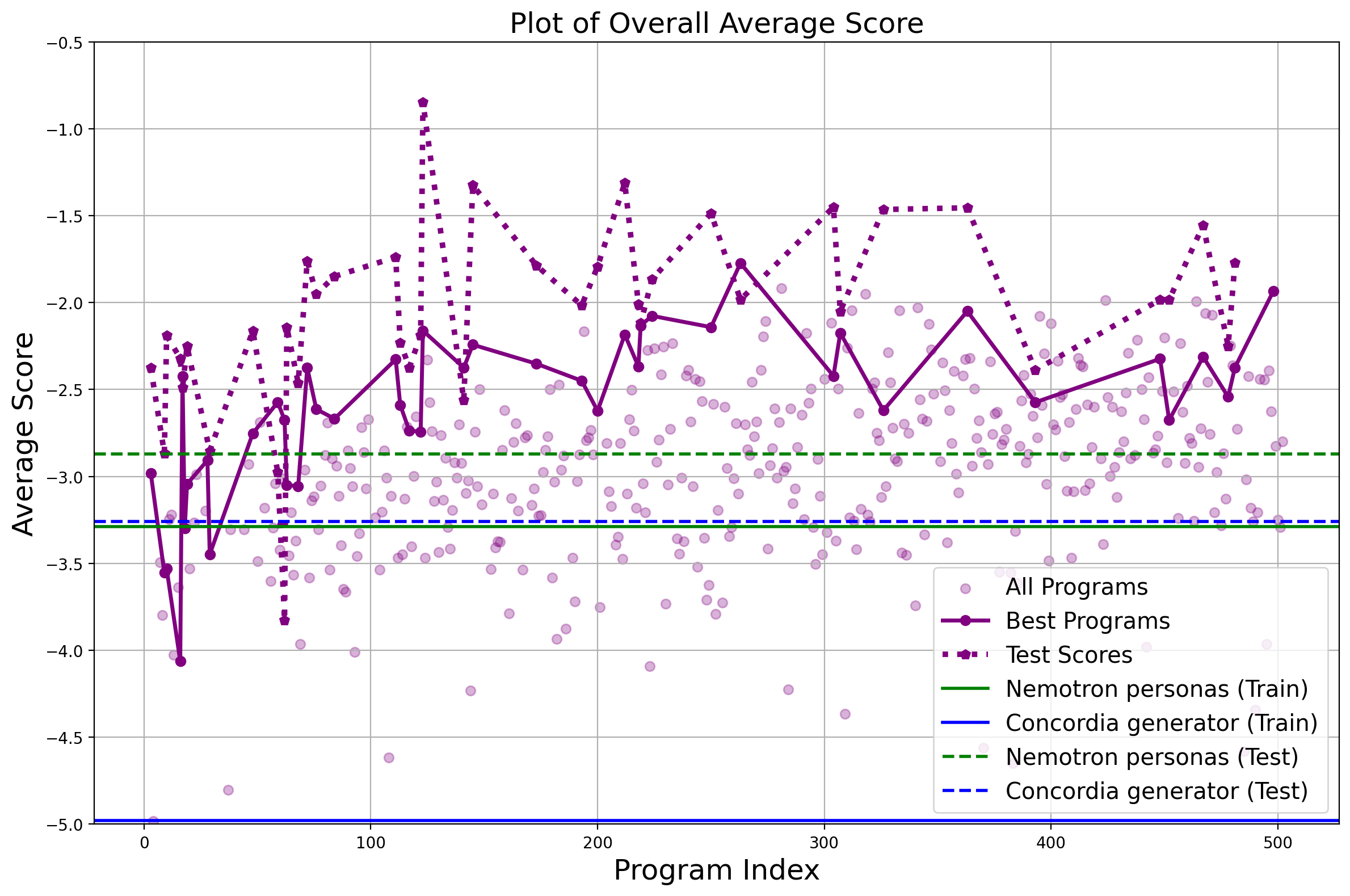
实验结果表明,经过进化算法优化的Persona Generators在六个多样性指标上显著优于现有基线。具体来说,该方法能够生成包含罕见特征组合的角色,这些角色在标准LLM输出中很难实现。这表明该方法能够更好地覆盖长尾行为,生成更具代表性的合成人群。
🎯 应用场景
该研究成果可应用于AI系统的评估和测试,尤其是在需要考虑用户多样性的场景下,例如推荐系统、对话系统、社交网络等。通过使用Persona Generators生成的合成角色,可以更全面地评估AI系统的性能,发现潜在的偏见和漏洞,从而提高AI系统的鲁棒性和公平性。此外,该方法还可以用于模拟未来场景,预测AI技术可能带来的社会影响。
📄 摘要(原文)
Evaluating AI systems that interact with humans requires understanding their behavior across diverse user populations, but collecting representative human data is often expensive or infeasible, particularly for novel technologies or hypothetical future scenarios. Recent work in Generative Agent-Based Modeling has shown that large language models can simulate human-like synthetic personas with high fidelity, accurately reproducing the beliefs and behaviors of specific individuals. However, most approaches require detailed data about target populations and often prioritize density matching (replicating what is most probable) rather than support coverage (spanning what is possible), leaving long-tail behaviors underexplored. We introduce Persona Generators, functions that can produce diverse synthetic populations tailored to arbitrary contexts. We apply an iterative improvement loop based on AlphaEvolve, using large language models as mutation operators to refine our Persona Generator code over hundreds of iterations. The optimization process produces lightweight Persona Generators that can automatically expand small descriptions into populations of diverse synthetic personas that maximize coverage of opinions and preferences along relevant diversity axes. We demonstrate that evolved generators substantially outperform existing baselines across six diversity metrics on held-out contexts, producing populations that span rare trait combinations difficult to achieve in standard LLM outputs.