Morphe: High-Fidelity Generative Video Streaming with Vision Foundation Model
作者: Tianyi Gong, Zijian Cao, Zixing Zhang, Jiangkai Wu, Xinggong Zhang, Shuguang Cui, Fangxin Wang
分类: cs.NI, cs.AI, cs.MM
发布日期: 2026-02-03
备注: Accepted by NSDI 2026 Fall
💡 一句话要点
提出Morphe以解决视频流传输中的质量与延迟问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频流传输 视觉基础模型 生成模型 带宽优化 鲁棒性 实时传输 智能丢包 时空优化
📋 核心要点
- 现有视频流传输方法在带宽受限和恶劣网络条件下难以保证视频质量,尤其是传统编码方法已接近极限。
- Morphe通过利用视觉基础模型的强大视频理解和处理能力,提出了一种新的端到端生成视频流传输框架,旨在提高压缩率和抗损失能力。
- 实验结果显示,Morphe在视觉质量上与H.265相当,同时在带宽使用上节省62.5%,实现了在复杂网络环境下的实时视频传输。
📝 摘要(中文)
视频流传输是基础的互联网服务,但在带宽受限和偏远地区等恶劣网络条件下,质量难以保证。现有方法主要集中在传统像素编码和新兴的神经增强流媒体上,但都面临压缩极限和延迟问题。本文提出Morphe,利用视觉基础模型(VFM)进行端到端的生成视频流传输,旨在实现高保真和抗损失的实时视频传输。Morphe通过联合训练视觉标记器和可变分辨率时空优化,构建了一个智能丢包的鲁棒流媒体系统。评估结果表明,Morphe在视觉质量上与H.265相当,同时节省62.5%的带宽,能够在挑战性网络环境中实现实时、抗损失的视频传输,标志着VFM驱动的多媒体流传输解决方案的里程碑。
🔬 方法详解
问题定义:本文旨在解决在带宽受限和恶劣网络条件下视频流传输质量不佳的问题。现有的传统像素编码方法已接近其压缩极限,而新兴的神经增强流媒体在延迟和视觉保真度上存在不足,限制了其实际应用。
核心思路:Morphe的核心思路是利用视觉基础模型(VFM)进行视频流的生成与传输,通过联合训练视觉标记器和可变分辨率时空优化,提升视频流的质量和抗损失能力。这样的设计使得系统能够在不同网络条件下保持高效的性能。
技术框架:Morphe的整体架构包括视觉标记器、时空优化模块和智能丢包机制。视觉标记器负责将视频内容转化为可处理的视觉标记,时空优化模块则在模拟网络约束下进行优化,智能丢包机制则用于应对实际网络中的扰动。
关键创新:Morphe的最大创新在于首次将视觉基础模型应用于端到端的生成视频流传输,突破了传统编码方法的限制,提供了更高的压缩率和更好的视觉质量。
关键设计:在设计中,Morphe采用了可变分辨率的时空优化策略,并结合了智能丢包算法,以增强系统在不稳定网络环境下的鲁棒性。损失函数的设计也经过精心调整,以确保在压缩过程中尽可能保留视频的视觉信息。
🖼️ 关键图片

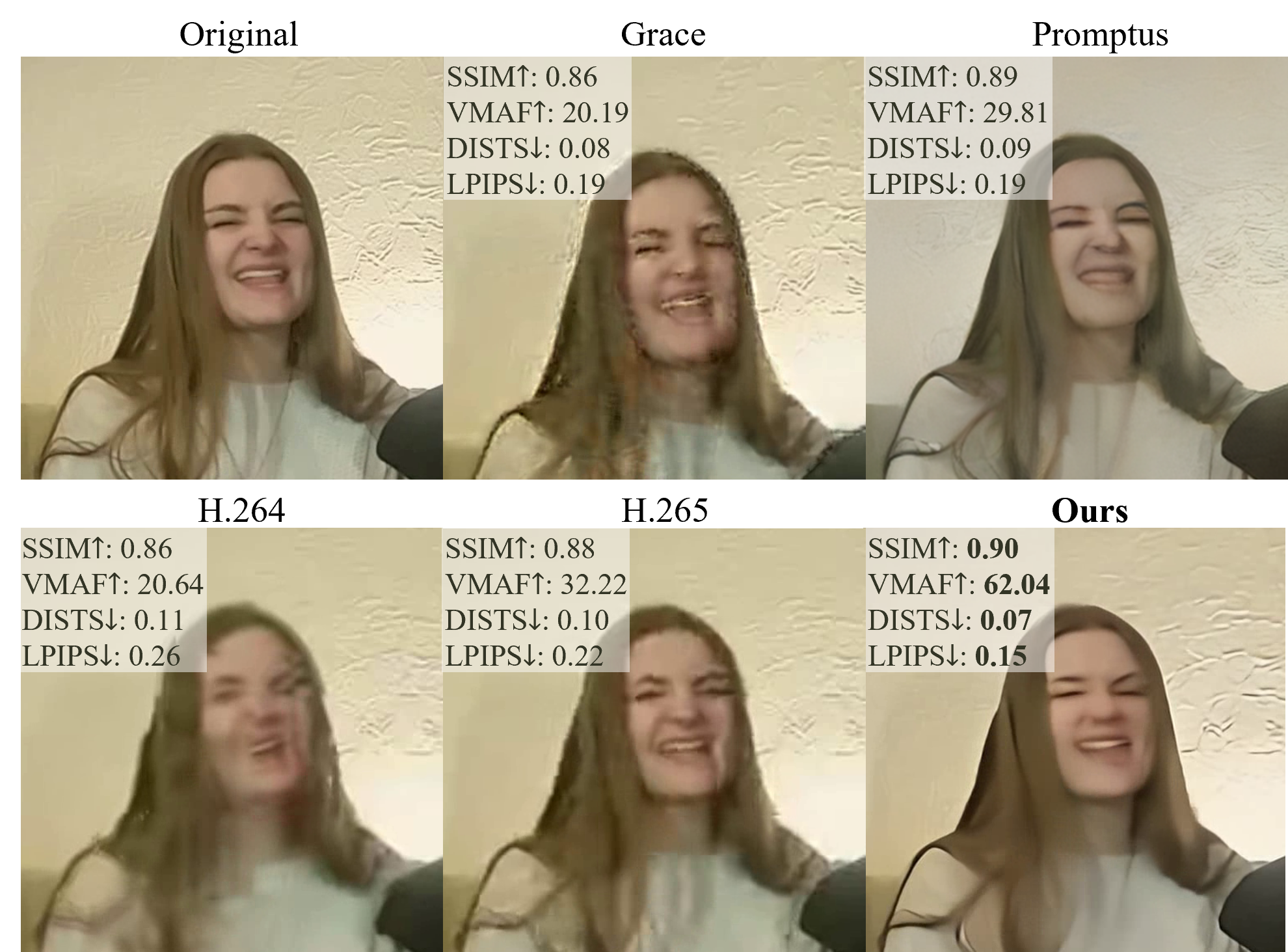
📊 实验亮点
Morphe在实验中表现出色,视觉质量与H.265相当,同时节省了62.5%的带宽。这一成果表明Morphe能够在复杂的网络环境中实现实时、抗损失的视频传输,具有重要的实际应用价值。
🎯 应用场景
Morphe的研究成果在多个领域具有广泛的应用潜力,包括在线教育、远程医疗、视频会议和娱乐等场景。其高效的视频流传输能力能够在带宽受限的环境中提供高质量的视觉体验,推动相关行业的发展。未来,Morphe的技术还可能与其他多媒体应用结合,进一步提升用户体验。
📄 摘要(原文)
Video streaming is a fundamental Internet service, while the quality still cannot be guaranteed especially in poor network conditions such as bandwidth-constrained and remote areas. Existing works mainly work towards two directions: traditional pixel-codec streaming nearly approaches its limit and is hard to step further in compression; the emerging neural-enhanced or generative streaming usually fall short in latency and visual fidelity, hindering their practical deployment. Inspired by the recent success of vision foundation model (VFM), we strive to harness the powerful video understanding and processing capacities of VFM to achieve generalization, high fidelity and loss resilience for real-time video streaming with even higher compression rate. We present the first revolutionized paradigm that enables VFM-based end-to-end generative video streaming towards this goal. Specifically, Morphe employs joint training of visual tokenizers and variable-resolution spatiotemporal optimization under simulated network constraints. Additionally, a robust streaming system is constructed that leverages intelligent packet dropping to resist real-world network perturbations. Extensive evaluation demonstrates that Morphe achieves comparable visual quality while saving 62.5\% bandwidth compared to H.265, and accomplishes real-time, loss-resilient video delivery in challenging network environments, representing a milestone in VFM-enabled multimedia streaming solutions.