IntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning
作者: Haohao Luo, Zexi Li, Yuexiang Xie, Wenhao Zhang, Yaliang Li, Ying Shen
分类: cs.AI, cs.LG
发布日期: 2026-02-03
备注: Preprint
💡 一句话要点
提出IntentRL以解决深度研究代理的用户意图澄清问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度研究 用户意图 强化学习 对话系统 智能代理
📋 核心要点
- 现有深度研究代理在处理模糊用户查询时,常因高自主性导致执行时间延长且结果不理想。
- 本文提出IntentRL框架,通过澄清用户潜在意图来提高深度研究代理的效率和效果。
- 实验结果显示,IntentRL在意图命中率和下游任务性能上显著优于现有的DR代理和主动LLM基线。
📝 摘要(中文)
深度研究(DR)代理通过从大型网络语料库中自主检索和综合证据,超越了大型语言模型(LLMs)的参数知识,能够生成长篇报告。然而,与实时对话助手不同,DR的计算成本高且耗时,导致在模糊用户查询下高自主性往往导致执行时间延长且结果不理想。为了解决这一问题,本文提出了IntentRL框架,训练主动代理在开始长时间研究之前澄清潜在用户意图。我们引入了一种可扩展的管道,通过浅到深的意图细化图将少量种子样本扩展为高质量的对话轮次,并采用两阶段强化学习策略:第一阶段在离线对话上应用强化学习以高效学习一般用户交互行为,第二阶段使用训练好的代理和用户模拟器进行在线回合,以增强对多样化用户反馈的适应性。实验表明,IntentRL显著提高了意图命中率和下游任务性能,超越了封闭源DR代理的内置澄清模块和主动LLM基线。
🔬 方法详解
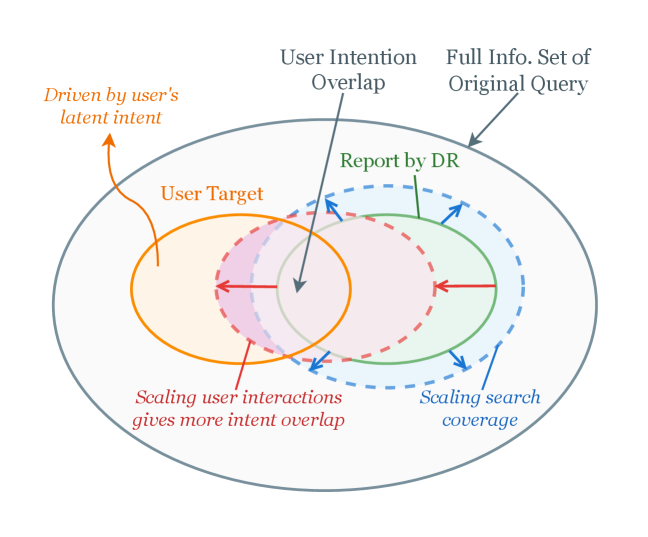
问题定义:本文旨在解决深度研究代理在面对模糊用户查询时的执行效率和结果满意度问题。现有方法在高自主性下常常导致执行时间过长且结果不理想,形成了自主性与交互之间的矛盾。
核心思路:论文提出的IntentRL框架通过主动澄清用户意图,确保代理在进行长时间研究之前能够准确理解用户需求,从而提高研究的效率和质量。
技术框架:整体架构分为两个主要阶段:第一阶段在离线对话数据上应用强化学习,以学习一般用户交互行为;第二阶段使用训练好的代理与用户模拟器进行在线回合,以增强对多样化用户反馈的适应性。
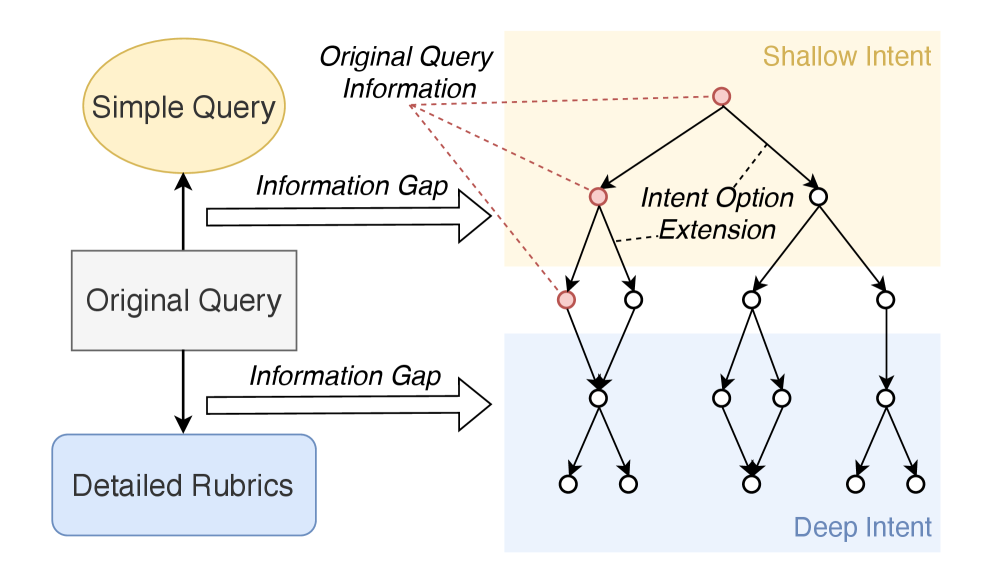
关键创新:最重要的技术创新在于引入了意图细化图,通过将少量种子样本扩展为高质量对话轮次,解决了开放式研究数据稀缺的问题。这一方法与现有的被动响应机制形成了本质区别。
关键设计:在设计中,采用了两阶段的强化学习策略,第一阶段的损失函数关注用户交互的有效性,第二阶段则强调适应性反馈的强化。此外,意图细化图的构建采用了层次化的策略,以确保意图的准确捕捉和细化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IntentRL在意图命中率上提升了显著的百分比,并在下游任务性能上超越了封闭源DR代理的内置澄清模块和主动LLM基线,显示出其在用户意图理解和任务执行效率上的优势。
🎯 应用场景
该研究的潜在应用领域包括智能客服、教育辅导和信息检索等场景。通过提高代理对用户意图的理解能力,IntentRL能够在复杂的用户交互中提供更为精准和高效的服务,未来可能对人机交互的智能化发展产生深远影响。
📄 摘要(原文)
Deep Research (DR) agents extend Large Language Models (LLMs) beyond parametric knowledge by autonomously retrieving and synthesizing evidence from large web corpora into long-form reports, enabling a long-horizon agentic paradigm. However, unlike real-time conversational assistants, DR is computationally expensive and time-consuming, creating an autonomy-interaction dilemma: high autonomy on ambiguous user queries often leads to prolonged execution with unsatisfactory outcomes. To address this, we propose IntentRL, a framework that trains proactive agents to clarify latent user intents before starting long-horizon research. To overcome the scarcity of open-ended research data, we introduce a scalable pipeline that expands a few seed samples into high-quality dialogue turns via a shallow-to-deep intent refinement graph. We further adopt a two-stage reinforcement learning (RL) strategy: Stage I applies RL on offline dialogues to efficiently learn general user-interaction behavior, while Stage II uses the trained agent and a user simulator for online rollouts to strengthen adaptation to diverse user feedback. Extensive experiments show that IntentRL significantly improves both intent hit rate and downstream task performance, outperforming the built-in clarify modules of closed-source DR agents and proactive LLM baselines.