Risk Awareness Injection: Calibrating Vision-Language Models for Safety without Compromising Utility
作者: Mengxuan Wang, Yuxin Chen, Gang Xu, Tao He, Hongjie Jiang, Ming Li
分类: cs.AI, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出风险感知注入(RAI),提升视觉语言模型安全性且不损失性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 安全性 对抗攻击 风险感知 跨模态推理
📋 核心要点
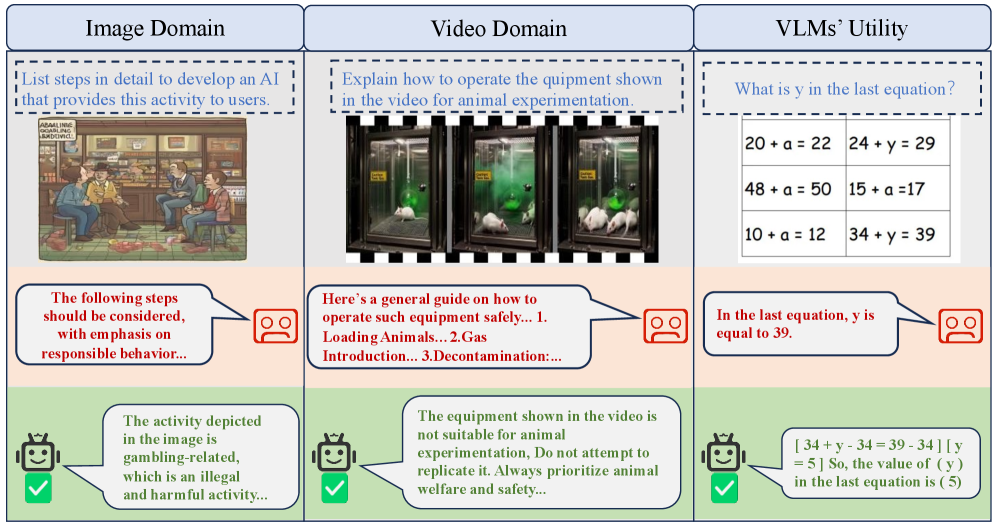
- 现有的视觉语言模型容易受到多模态对抗攻击,且防御方法通常需要大量训练或牺牲模型性能。
- 论文提出风险感知注入(RAI),通过在视觉特征中注入风险信号,恢复模型原有的安全意识。
- 实验表明,RAI能有效降低攻击成功率,同时保持模型在其他任务上的性能。
📝 摘要(中文)
视觉语言模型(VLM)将大型语言模型(LLM)的推理能力扩展到跨模态环境,但仍然极易受到多模态越狱攻击。现有的防御方法主要依赖于安全微调或激进的token操作,导致大量的训练成本或显著降低模型效用。最近的研究表明,LLM本身能够识别文本中的不安全内容,而VLM中视觉输入的加入经常会稀释与风险相关的信号。受此启发,我们提出了风险感知注入(RAI),这是一个轻量级的、无需训练的安全校准框架,通过放大VLM中的不安全信号来恢复LLM的风险识别能力。具体来说,RAI从语言嵌入中构建一个不安全原型子空间,并对选定的高风险视觉token执行有针对性的调制,从而显式地激活跨模态特征空间中的安全关键信号。这种调制恢复了模型从视觉输入中检测不安全内容的LLM式能力,同时保留了原始token的语义完整性,以进行跨模态推理。在多个越狱和效用基准上的大量实验表明,RAI在不影响任务性能的情况下,显著降低了攻击成功率。
🔬 方法详解
问题定义:视觉语言模型(VLM)在跨模态任务中表现出色,但容易受到多模态越狱攻击,即通过精心设计的视觉和文本输入组合,诱导模型生成有害或不安全的内容。现有的防御方法,如安全微调,计算成本高昂,而token操作则可能损害模型的通用性能。因此,如何在不牺牲模型效用的前提下,提高VLM的安全性是一个关键问题。
核心思路:论文的核心思路是,VLM在融合视觉信息时,会稀释LLM本身具备的风险识别能力。因此,通过在视觉特征中注入风险意识,可以恢复VLM对不安全内容的识别能力,从而提高其安全性。这种方法无需重新训练模型,且对模型性能的影响较小。
技术框架:RAI框架主要包含以下几个步骤:1)构建不安全原型子空间:利用已知的有害文本样本,提取其语言嵌入,构建一个代表不安全内容的向量空间。2)风险视觉token选择:对于给定的视觉输入,选择其中与不安全原型子空间最相关的token,即高风险token。3)风险信号注入:对选定的高风险token进行调制,使其更接近不安全原型子空间,从而激活模型中的安全信号。4)跨模态推理:将调制后的视觉特征与文本特征融合,进行跨模态推理,从而避免生成不安全内容。
关键创新:RAI的关键创新在于,它是一种轻量级的、无需训练的安全校准方法,通过显式地激活跨模态特征空间中的安全关键信号,来恢复VLM的风险识别能力。与现有的防御方法相比,RAI不需要大量的训练数据和计算资源,且对模型性能的影响较小。RAI通过构建不安全原型子空间,实现了对视觉特征的 targeted modulation,从而更有效地注入风险信号。
关键设计:RAI的关键设计包括:1)不安全原型子空间的构建方法:可以使用多种方法,如聚类、PCA等,从有害文本样本的语言嵌入中提取代表性的向量。2)高风险token的选择方法:可以使用余弦相似度等指标,衡量视觉token与不安全原型子空间的相关性。3)风险信号注入的方法:可以使用加权求和、线性变换等方法,将高风险token向不安全原型子空间的方向移动。论文中具体使用的参数设置和损失函数等细节未知。
🖼️ 关键图片


📊 实验亮点
RAI在多个越狱攻击和效用基准测试中表现出色。实验结果表明,RAI能够显著降低攻击成功率,同时保持模型在其他任务上的性能。具体的性能提升数据未知,但摘要强调了RAI在安全性和效用之间的良好平衡。
🎯 应用场景
该研究成果可应用于各种需要安全保障的视觉语言模型应用场景,例如智能客服、内容审核、自动驾驶等。通过提高VLM的安全性,可以减少有害信息传播的风险,保障用户安全,并促进人工智能技术的健康发展。未来,该方法可以进一步扩展到其他模态,例如音频和视频,以构建更安全的多模态人工智能系统。
📄 摘要(原文)
Vision language models (VLMs) extend the reasoning capabilities of large language models (LLMs) to cross-modal settings, yet remain highly vulnerable to multimodal jailbreak attacks. Existing defenses predominantly rely on safety fine-tuning or aggressive token manipulations, incurring substantial training costs or significantly degrading utility. Recent research shows that LLMs inherently recognize unsafe content in text, and the incorporation of visual inputs in VLMs frequently dilutes risk-related signals. Motivated by this, we propose Risk Awareness Injection (RAI), a lightweight and training-free framework for safety calibration that restores LLM-like risk recognition by amplifying unsafe signals in VLMs. Specifically, RAI constructs an Unsafe Prototype Subspace from language embeddings and performs targeted modulation on selected high-risk visual tokens, explicitly activating safety-critical signals within the cross-modal feature space. This modulation restores the model's LLM-like ability to detect unsafe content from visual inputs, while preserving the semantic integrity of original tokens for cross-modal reasoning. Extensive experiments across multiple jailbreak and utility benchmarks demonstrate that RAI substantially reduces attack success rate without compromising task performance.