Precision in Practice: Knowledge Guided Code Summarizing Grounded in Industrial Expectations
作者: Jintai Li, Songqiang Chen, Shuo Jin, Xiaoyuan Xie
分类: cs.SE, cs.AI
发布日期: 2026-02-03
💡 一句话要点
ExpSum:结合工业期望的知识引导代码摘要生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码摘要 大型语言模型 工业期望 知识引导 元数据 领域知识 HarmonyOS
📋 核心要点
- 现有代码摘要方法生成的摘要在工业环境中实用性不足,未能满足开发者对领域术语、功能分类和避免冗余实现细节的期望。
- ExpSum通过函数元数据抽象、信息元数据过滤、上下文感知的领域知识检索和约束驱动的提示,引导LLM生成符合开发者期望的结构化摘要。
- 在HarmonyOS和通用基准测试中,ExpSum显著优于现有方法,在HarmonyOS上BLEU-4提升高达26.71%,ROUGE-L提升高达20.10%。
📝 摘要(中文)
代码摘要对于帮助开发者理解代码功能、降低维护和协作成本至关重要。尽管大型语言模型(LLMs)的最新进展显著改进了自动代码摘要生成,但生成的摘要在工业环境中的实际效用仍未得到充分探索。通过与HarmonyOS项目的文档专家合作,我们进行了一项问卷调查,结果表明,由于违反了开发者对工业文档的期望,超过57.4%的现有最佳方法生成的代码摘要被拒绝。除了与参考摘要的语义相似性之外,开发者还强调了其他要求,包括使用适当的领域术语、明确的功能分类以及避免冗余的实现细节。为了满足这些期望,我们提出了一种期望感知的代码摘要方法ExpSum,它集成了函数元数据抽象、信息元数据过滤、上下文感知的领域知识检索和约束驱动的提示,以指导LLM生成结构化的、符合期望的摘要。我们在HarmonyOS项目和广泛使用的代码摘要基准上评估了ExpSum。实验结果表明,ExpSum始终优于所有基线,在HarmonyOS上BLEU-4提高了26.71%,ROUGE-L提高了20.10%。此外,基于LLM的评估表明,ExpSum生成的摘要更好地符合其他项目的开发者期望,证明了其在工业代码文档方面的有效性。
🔬 方法详解
问题定义:现有代码摘要生成方法,特别是基于大型语言模型的方法,虽然在语义相似度上有所提升,但在工业实践中生成的摘要往往不符合开发者的期望。这些期望包括使用正确的领域术语、明确的功能分类以及避免不必要的实现细节,导致大量生成的摘要被拒绝,降低了代码理解和维护的效率。
核心思路:ExpSum的核心思路是让代码摘要生成过程能够感知并满足工业界开发者的期望。通过提取和利用代码的元数据信息,并结合领域知识,引导大型语言模型生成更符合实际需求的摘要。这种方法旨在弥合学术研究与工业实践之间的差距,提高代码摘要的实用性。
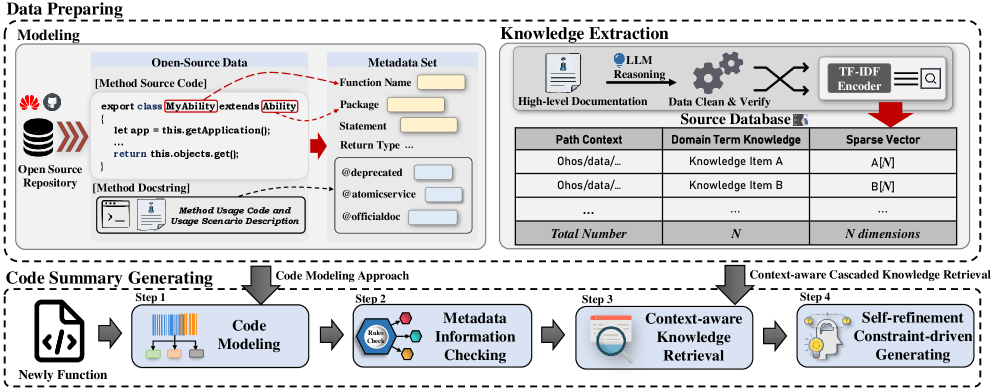
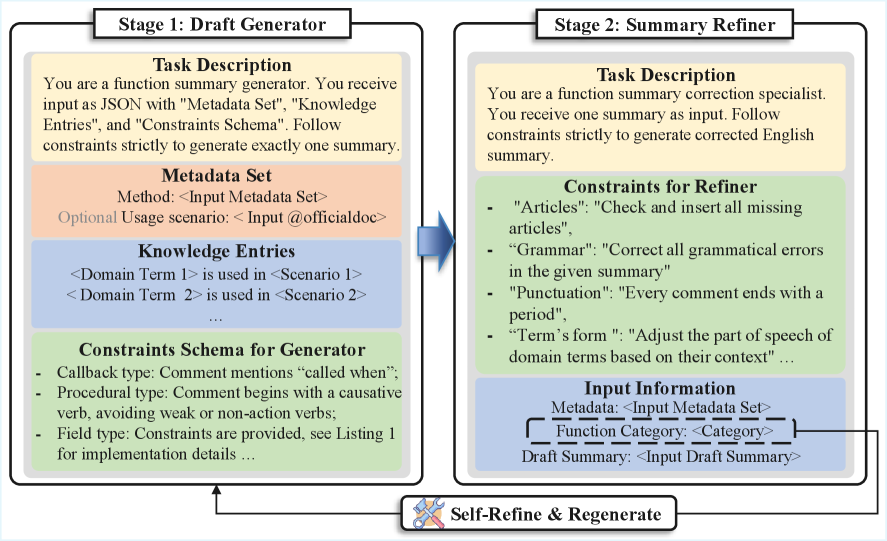
技术框架:ExpSum包含以下几个主要模块:1) 函数元数据抽象:从代码中提取函数名、参数、返回值等元数据信息。2) 信息元数据过滤:过滤掉不重要的元数据,保留对摘要生成有用的信息。3) 上下文感知的领域知识检索:根据代码上下文检索相关的领域知识,例如API文档、术语表等。4) 约束驱动的提示:利用提取的元数据和检索到的领域知识,构建提示(prompt),引导大型语言模型生成符合期望的摘要。
关键创新:ExpSum的关键创新在于其期望感知的摘要生成方法。它不仅仅关注摘要的语义准确性,更关注摘要是否符合工业界开发者的实际需求。通过将元数据抽象、信息过滤、领域知识检索和约束驱动的提示相结合,ExpSum能够生成更实用、更易于理解的代码摘要。
关键设计:ExpSum的关键设计包括:元数据过滤策略,用于选择对摘要生成有用的元数据;领域知识检索方法,用于找到与代码上下文相关的领域知识;以及约束驱动的提示模板,用于引导大型语言模型生成符合期望的摘要。具体的参数设置和网络结构取决于所使用的大型语言模型和数据集,论文中可能未详细描述。
🖼️ 关键图片
📊 实验亮点
ExpSum在HarmonyOS项目上取得了显著的性能提升,BLEU-4指标提高了26.71%,ROUGE-L指标提高了20.10%。此外,基于LLM的评估表明,ExpSum生成的摘要在其他项目中也更符合开发者的期望。这些实验结果表明,ExpSum是一种有效的、实用的代码摘要生成方法,能够满足工业界的需求。
🎯 应用场景
ExpSum可应用于各种软件开发场景,尤其是在大型工业项目中,能够显著提高代码文档的质量和开发效率。通过自动生成符合开发者期望的代码摘要,ExpSum可以降低代码理解的难度,减少维护成本,并促进团队协作。未来,该方法可以进一步扩展到其他编程语言和软件开发领域,例如API文档生成、代码搜索等。
📄 摘要(原文)
Code summaries are essential for helping developers understand code functionality and reducing maintenance and collaboration costs. Although recent advances in large language models (LLMs) have significantly improved automatic code summarization, the practical usefulness of generated summaries in industrial settings remains insufficiently explored. In collaboration with documentation experts from the industrial HarmonyOS project, we conducted a questionnaire study showing that over 57.4% of code summaries produced by state-of-the-art approaches were rejected due to violations of developers' expectations for industrial documentation. Beyond semantic similarity to reference summaries, developers emphasize additional requirements, including the use of appropriate domain terminology, explicit function categorization, and the avoidance of redundant implementation details. To address these expectations, we propose ExpSum, an expectation-aware code summarization approach that integrates function metadata abstraction, informative metadata filtering, context-aware domain knowledge retrieval, and constraint-driven prompting to guide LLMs in generating structured, expectation-aligned summaries. We evaluate ExpSum on the HarmonyOS project and widely used code summarization benchmarks. Experimental results show that ExpSum consistently outperforms all baselines, achieving improvements of up to 26.71% in BLEU-4 and 20.10% in ROUGE-L on HarmonyOS. Furthermore, LLM-based evaluations indicate that ExpSum-generated summaries better align with developer expectations across other projects, demonstrating its effectiveness for industrial code documentation.