Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis
作者: Zhengbo Jiao, Shaobo Wang, Zifan Zhang, Xuan Ren, Wei Wang, Bing Zhao, Hu Wei, Linfeng Zhang
分类: cs.AI, cs.LG
发布日期: 2026-02-03
备注: 23page4
💡 一句话要点
提出Agentic Proposing框架,通过组合技能合成高质量数据,提升大语言模型推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据合成 智能体 强化学习 推理能力 多粒度策略优化 序列决策 问题生成
📋 核心要点
- 现有数据合成方法难以兼顾结构有效性和问题复杂度,限制了大语言模型推理能力的提升。
- Agentic Proposing框架将问题生成视为智能体通过组合技能实现目标的序列决策过程。
- 实验表明,基于Agentic Proposing合成数据训练的模型,在数学、编码和科学推理任务上显著优于现有方法。
📝 摘要(中文)
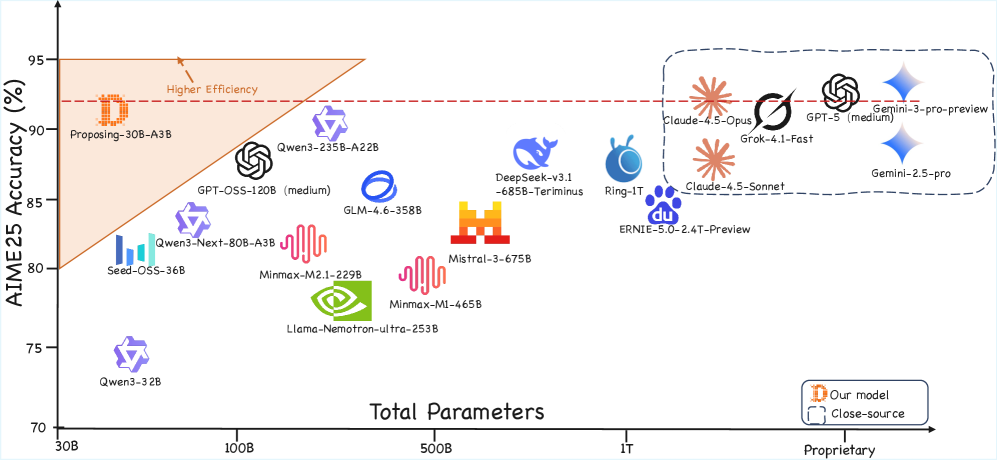
为了提升大语言模型在复杂推理方面的能力,本文提出了一种名为Agentic Proposing的框架。该框架将问题合成建模为一个目标驱动的序列决策过程,其中一个专门的智能体动态地选择和组合模块化的推理技能。通过内部反思和工具使用的迭代工作流程,我们使用多粒度策略优化(MGPO)开发了Agentic-Proposer-4B,以生成跨数学、编码和科学领域的高精度、可验证的训练轨迹。实验结果表明,在智能体合成数据上训练的下游求解器显著优于领先的基线,并表现出强大的跨领域泛化能力。值得注意的是,一个仅在11,000个合成轨迹上训练的30B求解器在AIME25上实现了91.6%的state-of-the-art准确率,与GPT-5等前沿规模的专有模型相媲美,证明少量高质量的合成信号可以有效地替代大量人工策划的数据集。
🔬 方法详解
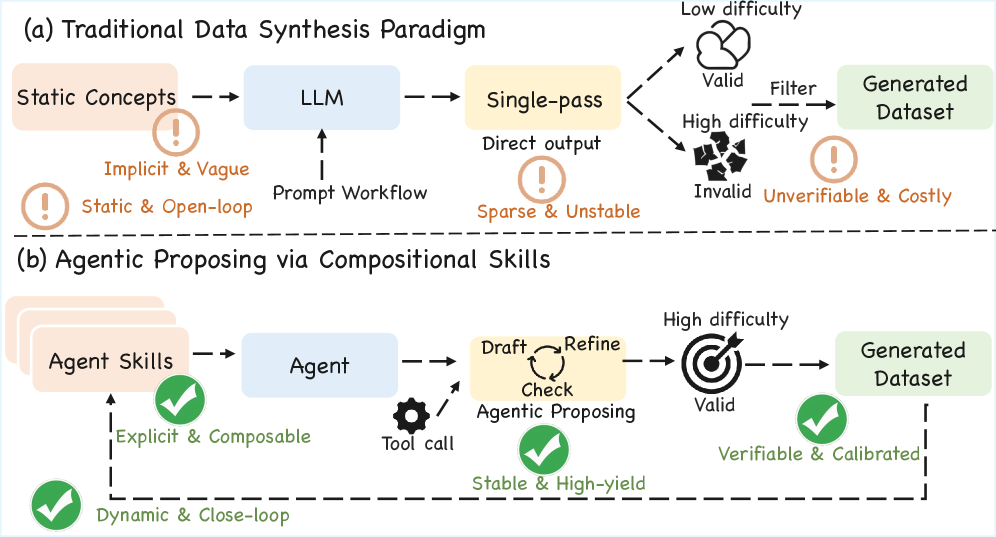
问题定义:现有的大语言模型依赖于高质量、可验证的数据集来提升复杂推理能力,但人工标注成本高昂且难以扩展。现有的合成范式通常面临一个反复出现的权衡:保持结构有效性通常会限制问题的复杂性,而放宽约束以增加难度通常会导致不一致或无法解决的实例。因此,如何高效地生成高质量、高难度且可验证的训练数据成为一个关键问题。
核心思路:Agentic Proposing的核心思路是将问题合成过程建模为一个智能体驱动的序列决策过程。该智能体通过动态选择和组合模块化的推理技能,逐步构建复杂的问题。这种方法允许在保持问题结构有效性的同时,增加问题的复杂性,从而生成更具挑战性的训练数据。
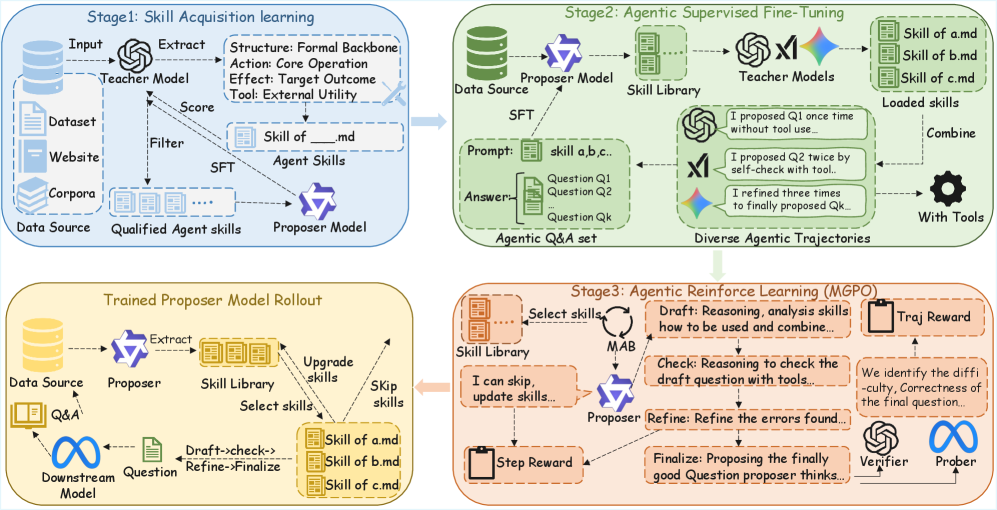
技术框架:Agentic Proposing框架包含以下主要模块:1) 技能库:包含各种模块化的推理技能,例如数学运算、代码生成、科学概念应用等。2) 智能体:负责根据当前状态和目标,从技能库中选择合适的技能进行组合。3) 环境:模拟问题生成过程,并根据智能体的行为更新状态。4) 反思机制:智能体通过内部反思和工具使用,评估当前生成的问题的质量和难度,并调整策略。框架使用多粒度策略优化(MGPO)来训练智能体。
关键创新:Agentic Proposing的关键创新在于将问题合成过程建模为一个智能体驱动的序列决策过程,并引入了内部反思和工具使用机制。这种方法允许智能体动态地调整策略,生成高质量、高难度且可验证的训练数据。与现有方法相比,Agentic Proposing能够更好地平衡问题结构有效性和问题复杂度。
关键设计:Agentic-Proposer-4B 使用了 4B 参数的语言模型作为智能体。多粒度策略优化(MGPO)被用于训练智能体,该方法允许在不同粒度级别上优化策略,从而提高训练效率和性能。具体来说,MGPO 包括以下几个关键设计:1) 技能选择策略:使用神经网络预测每个技能的概率。2) 奖励函数:根据生成的问题的质量和难度,为智能体提供奖励。3) 内部反思机制:智能体使用语言模型评估当前生成的问题的质量和难度,并根据评估结果调整策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在Agentic Proposing合成数据上训练的30B求解器在AIME25上实现了91.6%的state-of-the-art准确率,与GPT-5等前沿规模的专有模型相媲美。这证明少量高质量的合成信号可以有效地替代大量人工策划的数据集。此外,该方法在数学、编码和科学推理任务上均取得了显著的性能提升,并表现出强大的跨领域泛化能力。
🎯 应用场景
Agentic Proposing可应用于各种需要高质量训练数据的领域,例如数学、编码、科学推理等。该方法可以降低人工标注成本,提高数据生成效率,并提升大语言模型在复杂推理任务上的性能。未来,该方法可以扩展到其他领域,例如自然语言处理、计算机视觉等,为各种人工智能应用提供高质量的训练数据。
📄 摘要(原文)
Advancing complex reasoning in large language models relies on high-quality, verifiable datasets, yet human annotation remains cost-prohibitive and difficult to scale. Current synthesis paradigms often face a recurring trade-off: maintaining structural validity typically restricts problem complexity, while relaxing constraints to increase difficulty frequently leads to inconsistent or unsolvable instances. To address this, we propose Agentic Proposing, a framework that models problem synthesis as a goal-driven sequential decision process where a specialized agent dynamically selects and composes modular reasoning skills. Through an iterative workflow of internal reflection and tool-use, we develop the Agentic-Proposer-4B using Multi-Granularity Policy Optimization (MGPO) to generate high-precision, verifiable training trajectories across mathematics, coding, and science. Empirical results demonstrate that downstream solvers trained on agent-synthesized data significantly outperform leading baselines and exhibit robust cross-domain generalization. Notably, a 30B solver trained on only 11,000 synthesized trajectories achieves a state-of-the-art 91.6% accuracy on AIME25, rivaling frontier-scale proprietary models such as GPT-5 and proving that a small volume of high-quality synthetic signals can effectively substitute for massive human-curated datasets.