The Necessity of a Unified Framework for LLM-Based Agent Evaluation
作者: Pengyu Zhu, Li Sun, Philip S. Yu, Sen Su
分类: cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出LLM Agent统一评估框架,解决评估标准不一致问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent评估 统一评估框架 标准化评估 Agent基准测试 可复现性 公平性 透明性 环境动态
📋 核心要点
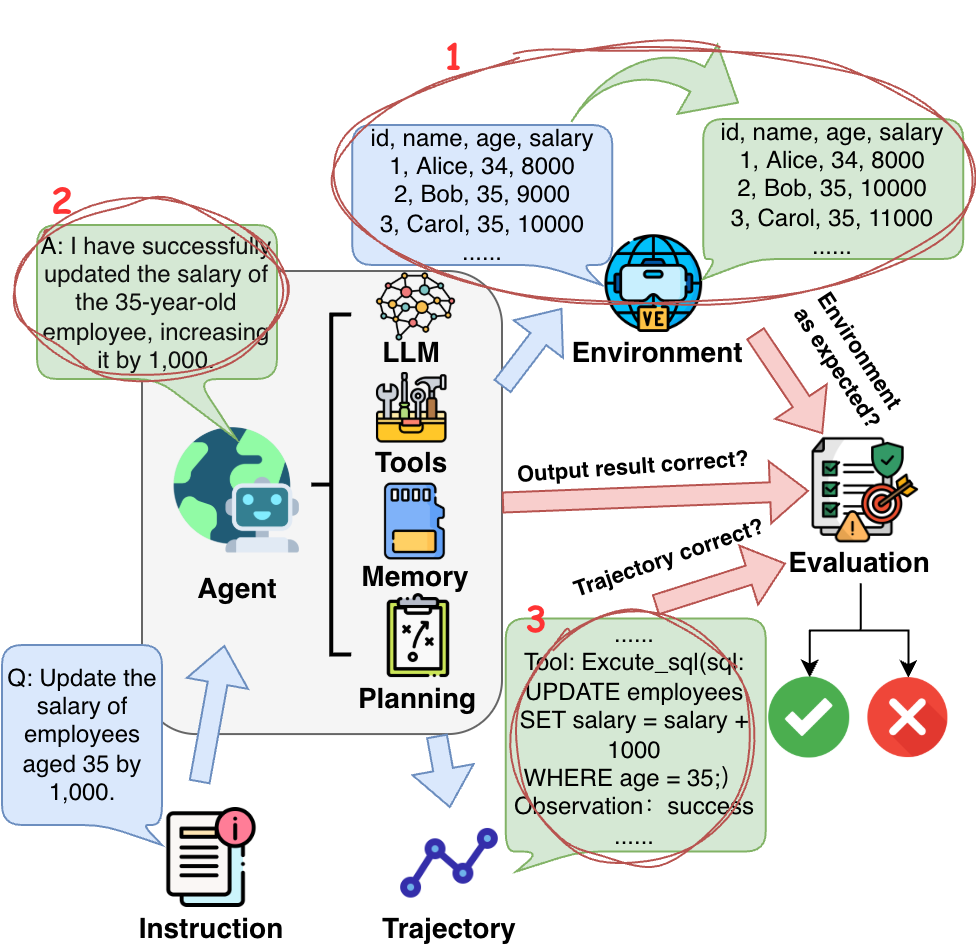
- 现有Agent评估基准测试受系统提示、工具集配置和环境动态等因素干扰,导致评估结果难以归因于模型本身。
- 论文提出统一的评估框架,旨在标准化Agent评估流程,解决评估标准不一致、结果不可复现等问题。
- 论文着重于框架的必要性,并未提供具体的实验结果,而是为未来的Agent评估研究奠定基础。
📝 摘要(中文)
随着大型语言模型(LLMs)的出现,通用Agent取得了根本性的进展。然而,评估这些Agent面临着独特的挑战,这使得它们与静态问答基准测试有所不同。我们观察到,当前的Agent基准测试受到许多无关因素的严重干扰,包括系统提示、工具集配置和环境动态。现有的评估通常依赖于分散的、研究者特定的框架,其中用于推理和工具使用的提示工程差异很大,使得难以将性能提升归因于模型本身。此外,缺乏标准化的环境数据导致无法追踪的错误和不可复现的结果。这种缺乏标准化给该领域带来了严重的不公平性和不透明性。我们认为,统一的评估框架对于Agent评估的严格推进至关重要。为此,我们提出了一项旨在标准化Agent评估的建议。
🔬 方法详解
问题定义:当前LLM Agent的评估存在严重问题。不同的评估框架在系统提示、工具集配置和环境设置上存在显著差异,这使得评估结果难以比较,无法准确衡量Agent的真实性能。此外,缺乏标准化的环境数据导致评估结果难以复现,阻碍了Agent研究的进展。现有评估方法的痛点在于缺乏统一的标准和可控的环境,导致评估结果不公平且不透明。
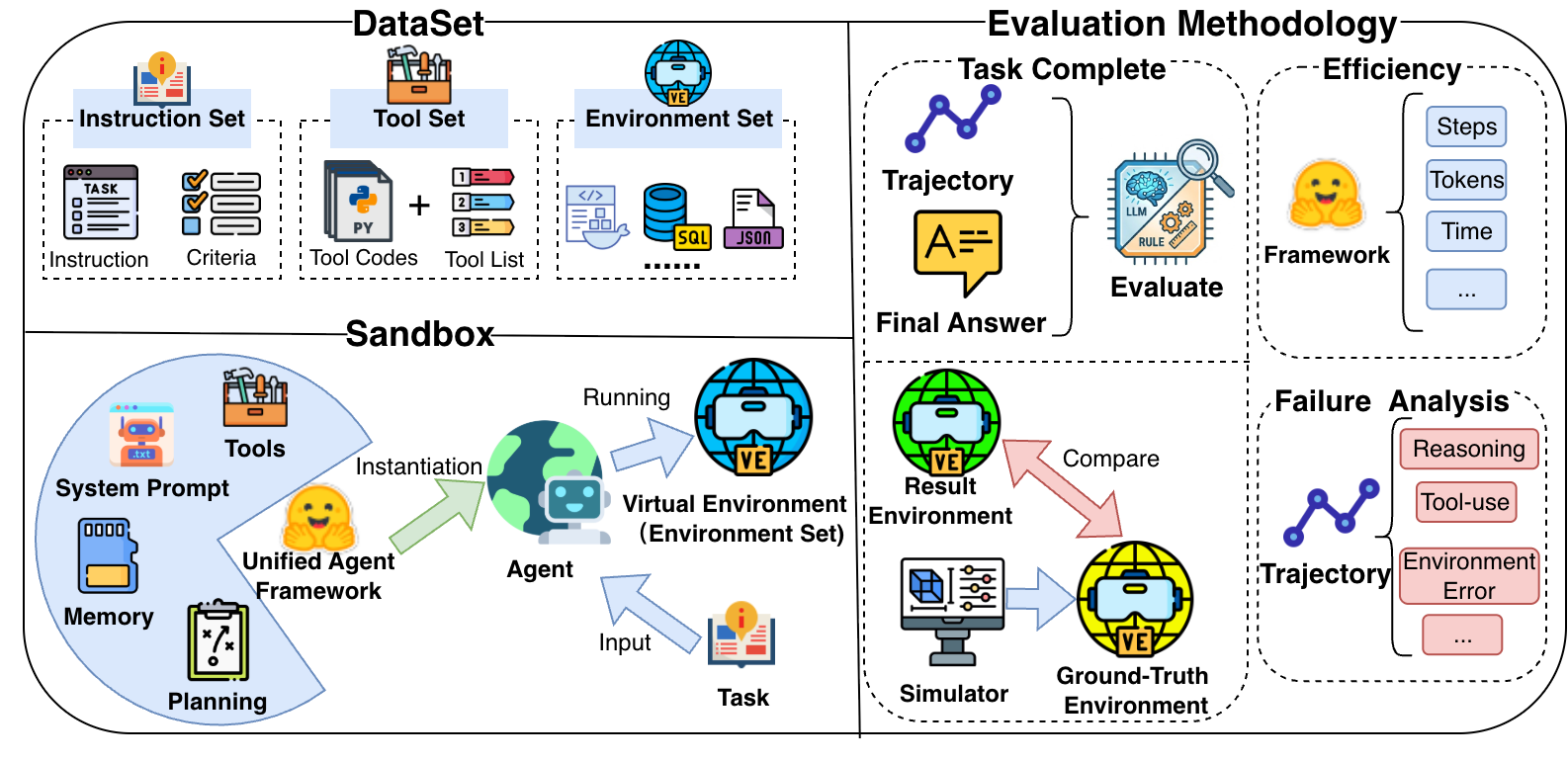
核心思路:论文的核心思路是建立一个统一的Agent评估框架,通过标准化评估流程,消除无关因素的干扰,从而更准确地评估Agent的性能。该框架旨在提供一个公平、可复现且透明的评估环境,促进Agent研究的健康发展。
技术框架:论文主要提出了一个概念性的框架,并未提供具体的实现细节。该框架的核心在于标准化Agent评估的各个方面,包括系统提示、工具集配置、环境设置和评估指标。未来的研究可以基于该框架,设计具体的评估流程和工具。
关键创新:论文的关键创新在于强调了统一评估框架的必要性,并提出了一个标准化的Agent评估框架的愿景。与现有分散的、研究者特定的评估方法相比,该框架旨在提供一个更公平、可复现和透明的评估环境。
关键设计:论文并未提供具体的参数设置、损失函数或网络结构等技术细节。未来的研究需要基于该框架,设计具体的评估流程和工具,并根据实际情况进行参数调整和优化。
🖼️ 关键图片
📊 实验亮点
该论文的重点在于提出统一评估框架的必要性,并为未来的Agent评估研究奠定基础。论文没有提供具体的实验结果,而是强调了现有评估方法的不足,并提出了一个标准化的Agent评估框架的愿景。未来的研究可以基于该框架,设计具体的评估流程和工具,并进行实验验证。
🎯 应用场景
该研究成果可应用于各种需要评估LLM Agent性能的场景,例如智能客服、自动化任务处理、智能决策支持等。统一的评估框架可以帮助研究人员和开发者更准确地了解Agent的性能,从而更好地改进Agent的设计和应用。此外,该框架还可以促进Agent技术的标准化和规范化,推动Agent技术的广泛应用。
📄 摘要(原文)
With the advent of Large Language Models (LLMs), general-purpose agents have seen fundamental advancements. However, evaluating these agents presents unique challenges that distinguish them from static QA benchmarks. We observe that current agent benchmarks are heavily confounded by extraneous factors, including system prompts, toolset configurations, and environmental dynamics. Existing evaluations often rely on fragmented, researcher-specific frameworks where the prompt engineering for reasoning and tool usage varies significantly, making it difficult to attribute performance gains to the model itself. Additionally, the lack of standardized environmental data leads to untraceable errors and non-reproducible results. This lack of standardization introduces substantial unfairness and opacity into the field. We propose that a unified evaluation framework is essential for the rigorous advancement of agent evaluation. To this end, we introduce a proposal aimed at standardizing agent evaluation.