Beyond Quantity: Trajectory Diversity Scaling for Code Agents
作者: Guhong Chen, Chenghao Sun, Cheng Fu, Qiyao Wang, Zhihong Huang, Chaopeng Wei, Guangxu Chen, Feiteng Fang, Ahmadreza Argha, Bing Zhao, Xander Xu, Qi Han, Hamid Alinejad-Rokny, Qiang Qu, Binhua Li, Shiwen Ni, Min Yang, Hu Wei, Yongbin Li
分类: cs.AI
发布日期: 2026-02-03
💡 一句话要点
TDScaling:通过轨迹多样性提升代码智能体性能,突破数量 scaling 瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码智能体 轨迹多样性 数据合成 工具交互 大语言模型 长尾场景 自适应进化
📋 核心要点
- 现有代码智能体受限于低质量合成数据和数量 scaling 的收益递减,无法充分利用轨迹数据。
- TDScaling 框架通过增加训练数据的轨迹多样性,而非单纯增加数据量,来提升代码智能体的性能。
- 实验表明,TDScaling 在工具使用泛化能力和固有编码能力上均有提升,实现了性能和成本的双赢。
📝 摘要(中文)
随着代码大语言模型(LLMs)通过模型上下文协议(MCP)演变为工具交互智能体,其泛化能力日益受到低质量合成数据和数量 scaling 收益递减的限制。此外,以数量为中心的 scaling 表现出早期瓶颈,未能充分利用轨迹数据。我们提出了 TDScaling,一种基于轨迹多样性 scaling 的代码智能体数据合成框架,通过多样性而非原始数量来提升性能。在固定的训练预算下,增加轨迹多样性比增加更多轨迹产生更大的收益,从而改善了智能体训练的性能-成本权衡。TDScaling 整合了四项创新:(1)捕获真实服务逻辑依赖的业务集群机制;(2)强制轨迹一致性的蓝图驱动多智能体范式;(3)使用领域熵、推理模式熵和累积动作复杂度来引导合成到长尾场景,防止模式崩溃的自适应进化机制;(4)缓解固有编码能力灾难性遗忘的沙盒代码工具。在通用工具使用基准(BFCL、tau^2-Bench)和代码智能体任务(RebenchT、CodeCI、BIRD)上的实验表明,TDScaling 实现了双赢的结果:既提高了工具使用的泛化能力,又提高了固有的编码能力。我们计划在发表时发布完整的代码库和合成数据集(包括 30,000 多个工具集群)。
🔬 方法详解
问题定义:当前代码大语言模型在工具交互场景下的泛化能力受限于合成数据的质量和数量 scaling 的瓶颈。简单增加数据量带来的收益递减,且无法覆盖长尾场景,导致模型在实际应用中表现不佳。
核心思路:TDScaling 的核心在于通过提升训练数据的轨迹多样性来改善模型的泛化能力。它认为,在固定训练预算下,增加轨迹的多样性比单纯增加轨迹的数量更能有效地提升模型性能,从而优化性能-成本的权衡。
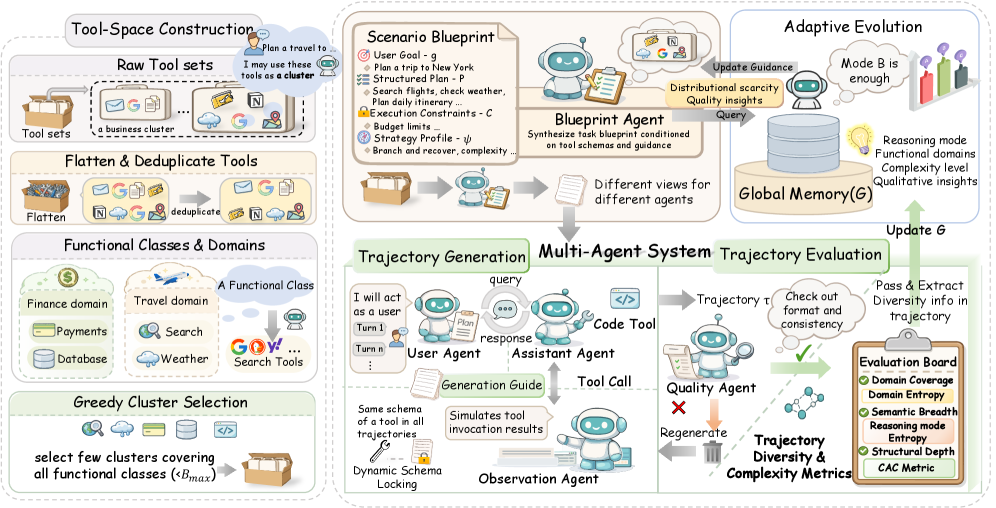
技术框架:TDScaling 包含四个主要组成部分:1) 业务集群机制:用于捕获真实服务中的逻辑依赖关系,模拟真实场景;2) 蓝图驱动的多智能体范式:通过预定义的蓝图来保证生成轨迹的一致性和连贯性;3) 自适应进化机制:利用领域熵、推理模式熵和累积动作复杂度等指标,引导数据生成过程关注长尾场景,避免模式崩溃;4) 沙盒代码工具:用于执行和验证生成的代码,同时防止模型遗忘固有的编码能力。
关键创新:TDScaling 的关键创新在于其对数据合成策略的转变,从传统的数量 scaling 转向多样性 scaling。通过业务集群、蓝图驱动和自适应进化等机制,TDScaling 能够生成更具代表性和挑战性的训练数据,从而提升模型的泛化能力。
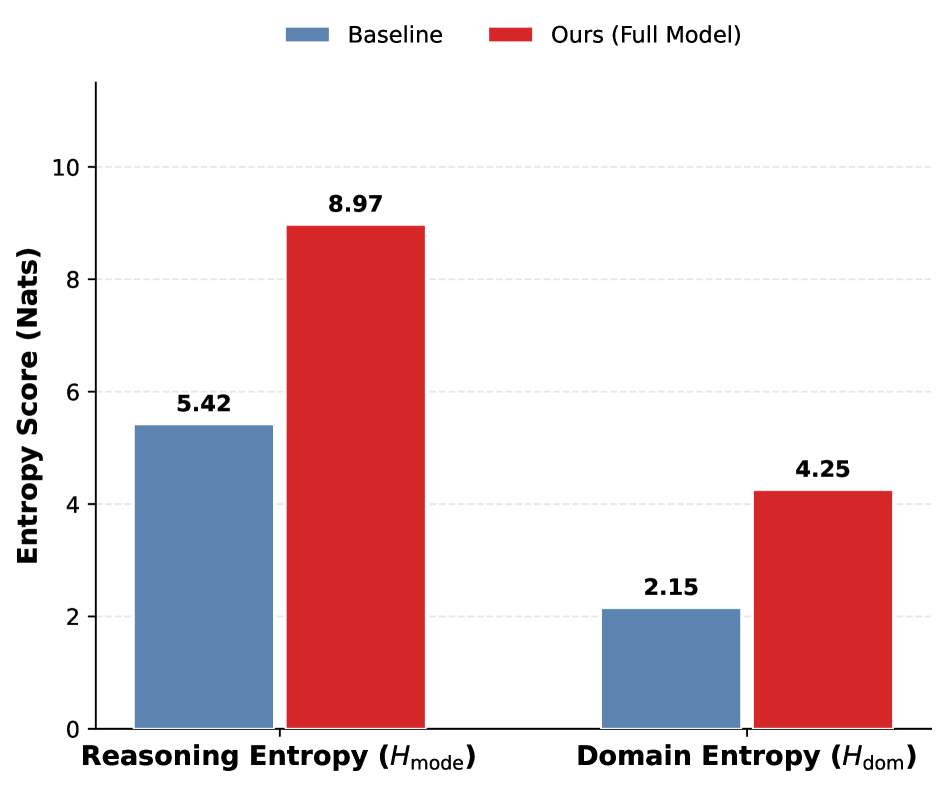
关键设计:自适应进化机制中的领域熵、推理模式熵和累积动作复杂度是关键的设计。领域熵用于衡量当前生成数据在不同领域上的分布情况,推理模式熵用于衡量模型使用的推理方式的多样性,累积动作复杂度则用于评估生成轨迹的复杂程度。通过最大化这些熵值,TDScaling 能够引导数据生成过程探索更广泛的场景和更复杂的任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TDScaling 在通用工具使用基准(BFCL、tau^2-Bench)和代码智能体任务(RebenchT、CodeCI、BIRD)上均取得了显著的性能提升。具体来说,TDScaling 不仅提高了工具使用的泛化能力,还增强了代码智能体固有的编码能力,实现了双赢的结果。论文计划开源代码和包含 30,000+ 工具集群的数据集。
🎯 应用场景
TDScaling 可应用于各种需要代码智能体进行工具交互的场景,例如自动化软件开发、智能运维、智能客服等。通过提升代码智能体的泛化能力和编码能力,可以降低开发和维护成本,提高工作效率,并为用户提供更智能化的服务。该研究对于推动代码智能体在实际应用中的落地具有重要意义。
📄 摘要(原文)
As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.