RC-GRPO: Reward-Conditioned Group Relative Policy Optimization for Multi-Turn Tool Calling Agents
作者: Haitian Zhong, Jixiu Zhai, Lei Song, Jiang Bian, Qiang Liu, Tieniu Tan
分类: cs.AI, cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出RC-GRPO,通过奖励调节提升多轮工具调用Agent的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮工具调用 奖励调节 策略优化 强化学习 大型语言模型
📋 核心要点
- 多轮工具调用任务中,奖励稀疏和探索成本高是现有方法面临的主要挑战。
- RC-GRPO通过奖励调节,将探索过程转化为可控的引导问题,提升组内多样性。
- 实验表明,RC-GRPO在BFCLv4基准测试中显著优于现有方法,甚至超越闭源API模型。
📝 摘要(中文)
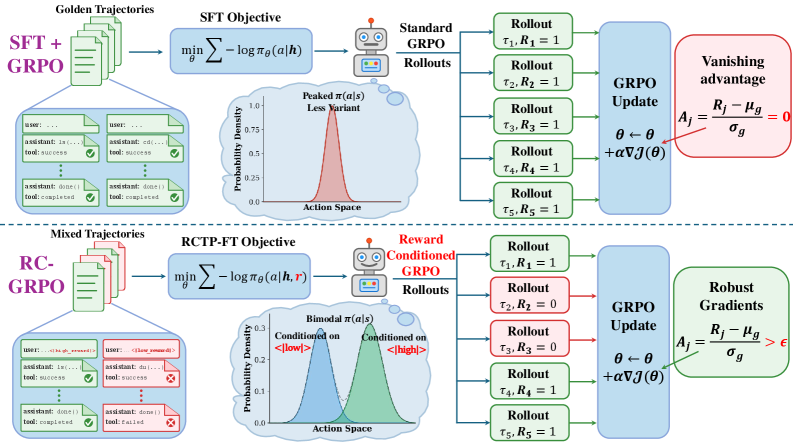
多轮工具调用对大型语言模型(LLMs)来说极具挑战,因为奖励稀疏且探索成本高昂。一种常见的方案,即SFT后接GRPO,当组内奖励变化较小时(例如,组内更多rollout获得全0或全1奖励)会停滞,导致组归一化优势信息量不足,产生消失的更新。为了解决这个问题,我们提出了RC-GRPO(奖励条件组相对策略优化),它通过离散奖励token将探索视为可控的引导问题。我们首先在混合质量的轨迹上微调一个奖励条件轨迹策略(RCTP),将奖励目标特殊token(例如,<|high_reward|>,<|low_reward|>)注入到提示中,使模型能够学习按需生成不同质量的轨迹。然后在RL期间,我们在每个GRPO组内采样不同的奖励token,并以采样的token为条件进行rollout,以提高组内多样性,从而提高优势增益。在Berkeley Function Calling Leaderboard v4(BFCLv4)多轮基准测试中,我们的方法比基线方法始终如一地提高了性能,并且在Qwen-2.5-7B-Instruct上的性能甚至超过了所有闭源API模型。
🔬 方法详解
问题定义:论文旨在解决多轮工具调用任务中,大型语言模型因奖励稀疏和探索成本高而导致的训练困难问题。现有方法,如SFT+GRPO,在组内奖励变化小的情况下,会产生信息量不足的优势函数,导致模型更新停滞,无法有效探索。
核心思路:论文的核心思路是将探索过程视为一个可控的引导问题,通过引入奖励条件机制,鼓励模型生成更多样化的轨迹。具体来说,通过在训练过程中显式地调节奖励目标,使模型能够根据不同的奖励信号生成不同质量的轨迹,从而提高组内多样性,改善优势函数的质量。
技术框架:RC-GRPO包含两个主要阶段:1) 奖励条件轨迹策略(RCTP)的微调;2) 基于奖励条件的组相对策略优化(RC-GRPO)。首先,使用混合质量的轨迹数据,通过在prompt中注入奖励目标token(如<|high_reward|>,<|low_reward|>)来微调RCTP,使其具备根据奖励目标生成不同质量轨迹的能力。然后,在RL训练阶段,针对每个GRPO组,采样不同的奖励token,并以此为条件进行rollout,从而增加组内轨迹的多样性。
关键创新:RC-GRPO的关键创新在于引入了奖励条件机制,将探索过程显式地建模为可控的引导问题。与传统的GRPO方法相比,RC-GRPO不再依赖于随机探索,而是通过调节奖励目标来引导模型生成更具信息量的轨迹,从而改善优势函数的质量,加速模型学习。
关键设计:RCTP微调阶段,使用交叉熵损失函数,目标是最大化给定奖励token和上下文的情况下,生成高质量轨迹的概率。在RC-GRPO阶段,使用标准的GRPO损失函数,但rollout过程以采样的奖励token为条件。奖励token的选择可以根据具体任务进行调整,例如,可以使用离散的奖励等级(高、中、低)或连续的奖励值。
🖼️ 关键图片
📊 实验亮点
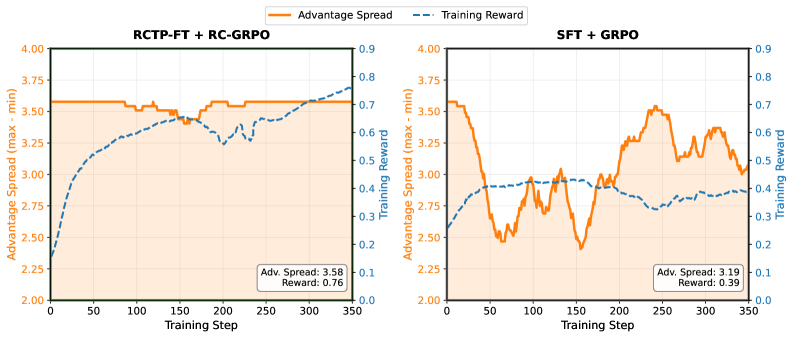
在Berkeley Function Calling Leaderboard v4 (BFCLv4)多轮基准测试中,RC-GRPO方法始终优于基线方法。特别是在Qwen-2.5-7B-Instruct模型上,RC-GRPO的性能甚至超越了所有闭源API模型,证明了其在复杂工具调用任务中的有效性。
🎯 应用场景
RC-GRPO可应用于各种需要多轮交互和工具调用的智能Agent,例如智能助手、自动化客服、以及涉及复杂API调用的任务型对话系统。该方法能够提升Agent在复杂环境中的探索能力和任务完成效率,具有广泛的应用前景。
📄 摘要(原文)
Multi-turn tool calling is challenging for Large Language Models (LLMs) because rewards are sparse and exploration is expensive. A common recipe, SFT followed by GRPO, can stall when within-group reward variation is low (e.g., more rollouts in a group receive the all 0 or all 1 reward), making the group-normalized advantage uninformative and yielding vanishing updates. To address this problem, we propose RC-GRPO (Reward-Conditioned Group Relative Policy Optimization), which treats exploration as a controllable steering problem via discrete reward tokens. We first fine-tune a Reward-Conditioned Trajectory Policy (RCTP) on mixed-quality trajectories with reward goal special tokens (e.g., <|high_reward|>, <|low_reward|>) injected into the prompts, enabling the model to learn how to generate distinct quality trajectories on demand. Then during RL, we sample diverse reward tokens within each GRPO group and condition rollouts on the sampled token to improve within-group diversity, improving advantage gains. On the Berkeley Function Calling Leaderboard v4 (BFCLv4) multi-turn benchmark, our method yields consistently improved performance than baselines, and the performance on Qwen-2.5-7B-Instruct even surpasses all closed-source API models.