STAR: Similarity-guided Teacher-Assisted Refinement for Super-Tiny Function Calling Models
作者: Jiliang Ni, Jiachen Pu, Zhongyi Yang, Jingfeng Luo, Conggang Hu
分类: cs.AI
发布日期: 2026-02-03
备注: The paper has been accepted to ICLR 2026
💡 一句话要点
STAR:面向超小型函数调用模型的相似性引导的教师辅助精炼
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 函数调用 知识蒸馏 强化学习 相似性学习 小型语言模型 AI Agent 模型压缩
📋 核心要点
- 现有函数调用模型依赖大型LLM,但其规模限制了部署;现有蒸馏方法易过拟合,奖励机制不适用于多解任务。
- STAR框架通过约束知识蒸馏和相似性引导强化学习,将LLM能力迁移到超小型模型,提升训练稳定性和奖励信号质量。
- 实验表明,STAR模型在多个基准测试中达到SOTA,0.6B模型超越了1B规模的开源模型,证明了其有效性。
📝 摘要(中文)
大型语言模型(LLM)在函数调用中的应用对于创建先进的AI Agent至关重要,但其庞大的规模阻碍了广泛应用,因此需要将其能力转移到较小的模型中。然而,现有的范例常常受到过拟合、训练不稳定、多解任务的无效二元奖励以及协同技术困难等问题的困扰。我们提出了STAR:相似性引导的教师辅助精炼,这是一个新颖的整体框架,可以有效地将LLM的能力转移到超小型模型。STAR包含两个核心技术创新:(1)约束知识蒸馏(CKD),一种训练目标,它增强了top-k前向KL散度,以抑制自信的错误预测,确保训练稳定性,同时保留下游RL的探索能力。(2)相似性引导的RL(Sim-RL),一种RL机制,引入了细粒度的、基于相似性的奖励。通过评估生成输出与真实值之间的相似性,为更好的策略优化提供了鲁棒、连续和丰富的信号。在具有挑战性和著名的基准测试中进行的大量实验证明了我们方法的有效性。我们的STAR模型在其规模类别中建立了SOTA,显着优于基线。值得注意的是,我们的0.6B STAR模型在所有小于1B的开放模型中实现了最佳性能,甚至超过了几个更大规模的知名开放模型。STAR展示了一个训练框架,可以将LLM的能力提炼到超小型模型中,为强大、可访问和高效的AI Agent铺平了道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在函数调用任务中规模过大,难以部署的问题。现有的知识蒸馏方法在将LLM的能力迁移到小型模型时,容易出现过拟合、训练不稳定等问题,并且对于存在多个正确答案的函数调用任务,传统的二元奖励信号不足以指导模型学习。
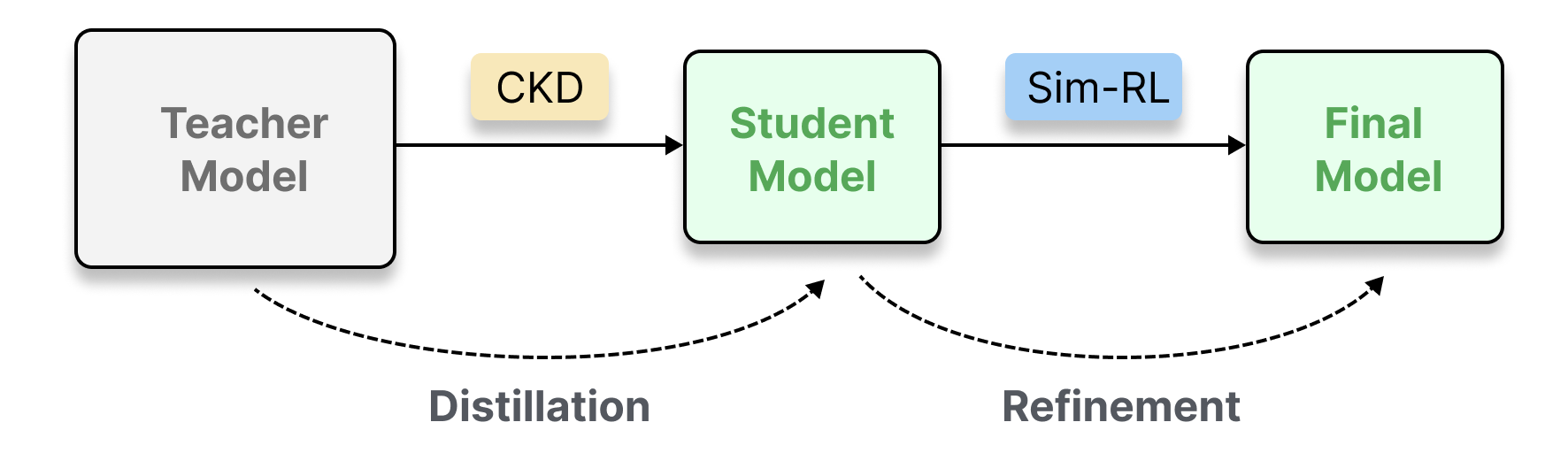
核心思路:论文的核心思路是通过结合约束知识蒸馏(CKD)和相似性引导的强化学习(Sim-RL),构建一个整体的训练框架,从而有效地将LLM的能力迁移到超小型模型。CKD旨在抑制模型对错误答案的过度自信,Sim-RL则提供更细粒度、更丰富的奖励信号。
技术框架:STAR框架包含两个主要阶段:首先使用约束知识蒸馏(CKD)对小型模型进行预训练,使其初步具备函数调用的能力。然后,使用相似性引导的强化学习(Sim-RL)对模型进行微调,进一步提升其性能。CKD阶段利用LLM的输出作为教师信号,通过最小化KL散度来指导小型模型的学习,并引入约束项来抑制错误预测。Sim-RL阶段则根据生成结果与ground truth之间的相似度来设计奖励函数,从而为模型提供更有效的学习信号。
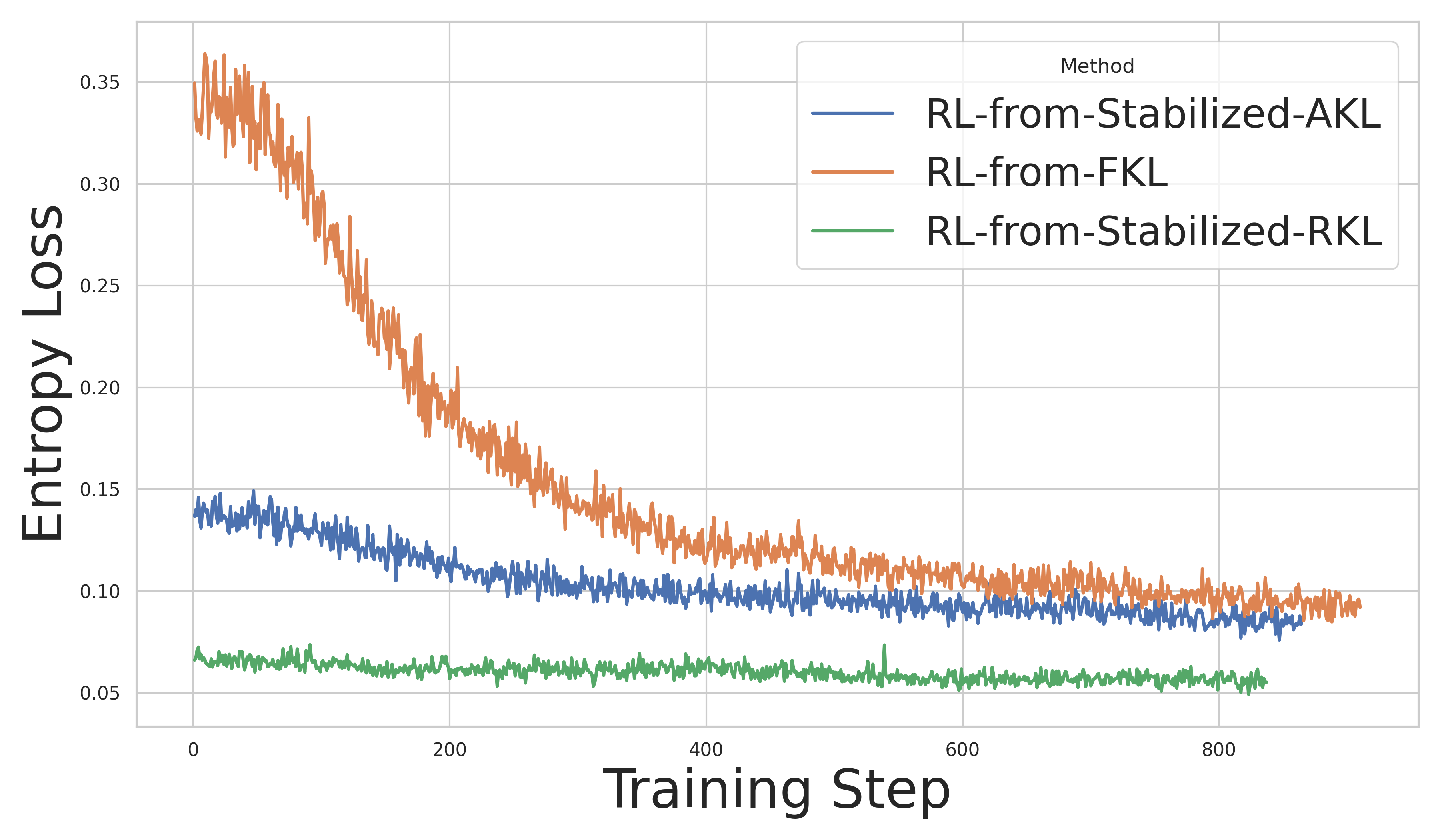
关键创新:STAR框架的关键创新在于以下两点:一是提出了约束知识蒸馏(CKD),通过抑制模型对错误答案的过度自信,提高了训练的稳定性;二是提出了相似性引导的强化学习(Sim-RL),通过引入细粒度的相似度奖励,为模型提供了更有效的学习信号,尤其是在多解任务中。与现有方法相比,STAR能够更好地平衡探索和利用,从而获得更好的性能。
关键设计:在CKD中,使用了top-k前向KL散度来衡量学生模型和教师模型之间的差异,并引入了一个约束项,用于惩罚学生模型对错误答案的过度自信。在Sim-RL中,奖励函数的设计基于生成结果与ground truth之间的相似度,可以使用BLEU、ROUGE等指标来计算相似度。此外,论文还设计了一个训练课程,逐步增加任务的难度,从而提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
STAR模型在多个函数调用基准测试中取得了SOTA性能。特别地,0.6B的STAR模型在所有小于1B的开源模型中表现最佳,甚至超过了几个更大规模的知名开源模型。实验结果表明,STAR框架能够有效地将LLM的能力迁移到超小型模型,并显著提升其性能。
🎯 应用场景
该研究成果可应用于各种需要函数调用的AI Agent,例如智能助手、自动化客服、智能家居控制等。通过将大型语言模型的能力迁移到小型模型,可以降低部署成本,提高响应速度,并使得AI Agent能够在资源受限的设备上运行。该研究为开发高效、可访问的AI Agent提供了新的思路。
📄 摘要(原文)
The proliferation of Large Language Models (LLMs) in function calling is pivotal for creating advanced AI agents, yet their large scale hinders widespread adoption, necessitating transferring their capabilities into smaller ones. However, existing paradigms are often plagued by overfitting, training instability, ineffective binary rewards for multi-solution tasks, and the difficulty of synergizing techniques. We introduce STAR: Similarity-guided Teacher-Assisted Refinement, a novel holistic framework that effectively transfers LLMs' capabilities to super-tiny models. STAR consists of two core technical innovations: (1) Constrained Knowledge Distillation (CKD), a training objective that augments top-k forward KL divergence to suppress confidently incorrect predictions, ensuring training stability while preserving exploration capacity for downstream RL. STAR holistically synergizes these strategies within a cohesive training curriculum, enabling super-tiny models to achieve exceptional performance on complex function calling tasks; (2) Similarity-guided RL (Sim-RL), a RL mechanism that introduces a fine-grained, similarity-based reward. This provides a robust, continuous, and rich signal for better policy optimization by evaluating the similarity between generated outputs and the ground truth. Extensive experiments on challenging and renowned benchmarks demonstrate the effectiveness of our method. Our STAR models establish SOTA in their size classes, significantly outperforming baselines. Remarkably, our 0.6B STAR model achieves the best performance among all open models under 1B, surpassing even several well-known open models at a larger scale. STAR demonstrates a training framework that distills capabilities of LLMs into super-tiny models, paving the way for powerful, accessible, and efficient AI agents.