Distilling LLM Reasoning into Graph of Concept Predictors
作者: Ziyang Yu, Liang Zhao
分类: cs.AI
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出概念预测图(GCP)框架,用于将LLM推理能力蒸馏到小型判别模型中,提升效率和可解释性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识蒸馏 概念预测 主动学习 图神经网络 自然语言处理 推理过程 可解释性
📋 核心要点
- 现有LLM蒸馏方法忽略中间推理过程,导致学生模型缺乏可解释性和诊断能力,限制了性能提升。
- GCP框架将LLM推理过程建模为概念预测图,学生模型通过模仿图中的节点进行推理,提升了蒸馏效率。
- 实验表明,GCP在有限标注预算下,在多个NLP分类任务上优于现有方法,并提供更清晰的训练过程控制。
📝 摘要(中文)
将大型语言模型(LLM)部署到判别任务中通常受到推理延迟、计算成本和API成本的限制。主动蒸馏通过查询LLM作为教师来训练紧凑的判别学生模型,从而降低这些成本。然而,大多数流程仅蒸馏最终标签,忽略了中间推理信号,并且对缺失的推理环节和错误产生的原因提供有限的诊断。我们提出了概念预测图(GCP),这是一个推理感知的主动蒸馏框架,它将教师的决策过程外化为一个有向无环图,并使用学生模型中的模块化概念预测器来镜像它。GCP通过图感知的获取策略来提高样本效率,该策略针对关键推理节点上的不确定性和分歧。此外,它通过执行有针对性的子模块再训练来提高训练稳定性和效率,该方法将下游损失归因于特定的概念预测器,并仅更新最具影响力的模块。在八个NLP分类基准上的实验表明,GCP在有限的标注预算下提高了性能,同时产生了更具可解释性和可控性的训练动态。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)蒸馏方法主要关注最终标签的迁移,忽略了LLM在推理过程中产生的中间概念和推理路径。这导致学生模型缺乏对推理过程的理解,难以诊断错误原因,并且限制了在有限标注预算下的性能提升。现有方法无法有效利用LLM的推理能力,并且缺乏对学生模型训练过程的精细控制。
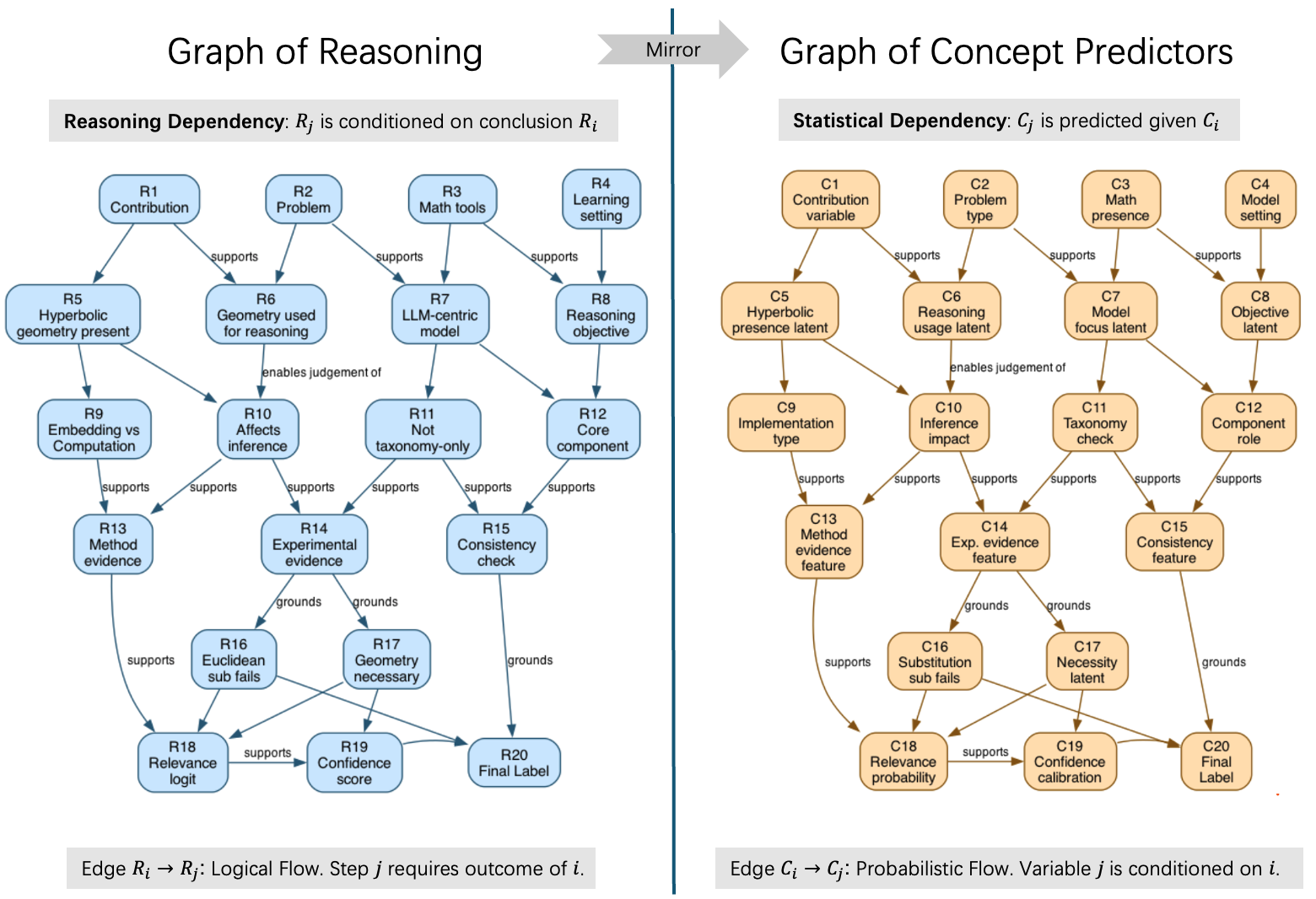
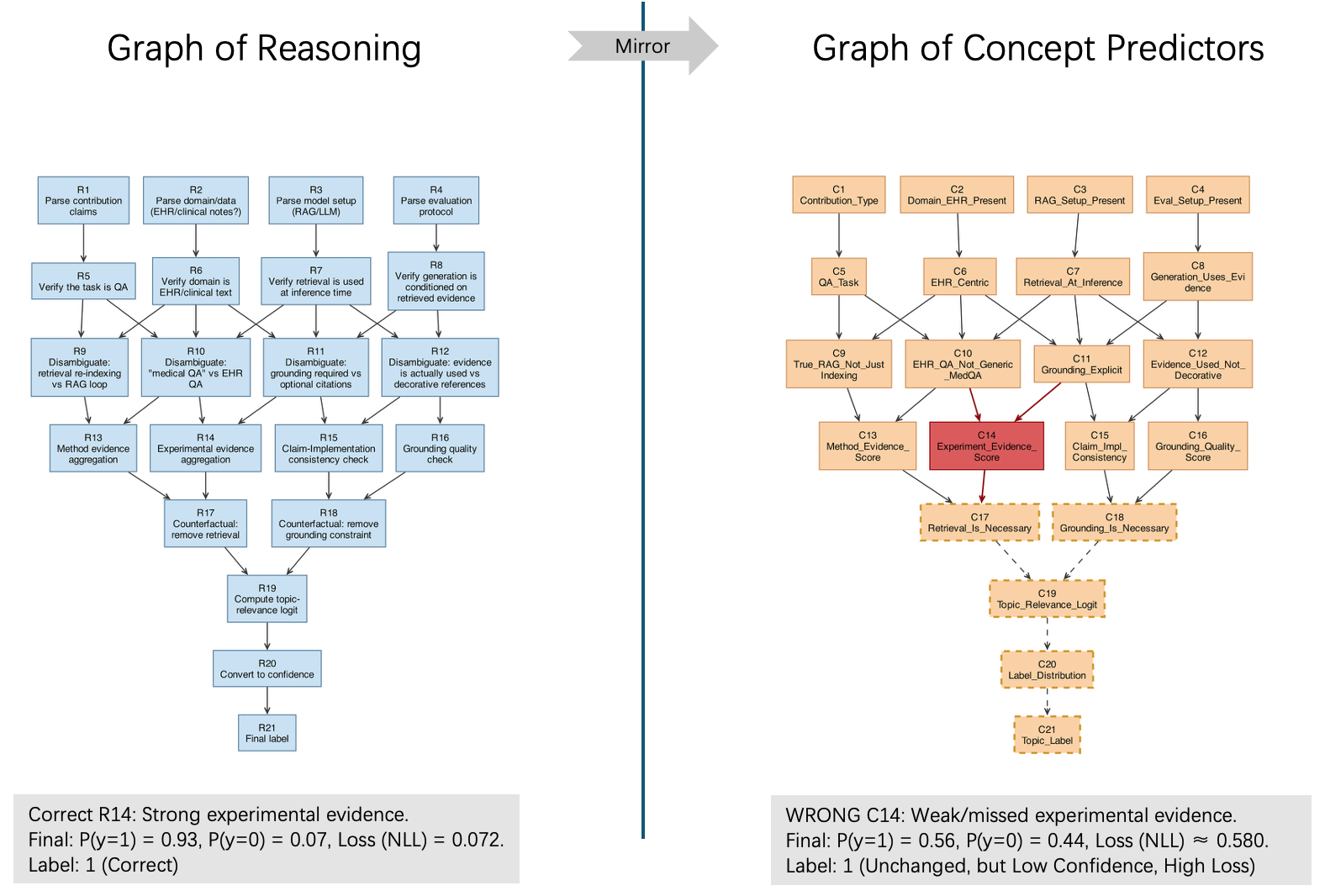
核心思路:本文的核心思路是将LLM的推理过程显式地建模为一个有向无环图,图中的每个节点代表一个概念预测器。学生模型通过学习预测这些概念,从而模仿LLM的推理过程。这种方法能够将LLM的推理能力分解为多个模块化的概念预测器,使得学生模型能够更好地理解和学习LLM的推理过程,并且能够针对性地进行训练和优化。通过图结构,可以追踪推理路径,定位错误节点,从而提高蒸馏效率和可解释性。
技术框架:GCP框架包含以下几个主要模块:1) LLM教师模型:负责提供推理过程和概念预测结果。2) 概念预测图(GCP):将LLM的推理过程建模为有向无环图,节点代表概念预测器,边代表概念之间的依赖关系。3) 学生模型:由多个模块化的概念预测器组成,每个概念预测器对应GCP中的一个节点。4) 图感知的主动学习策略:选择信息量最大的样本进行标注,提高样本效率。5) 有针对性的子模块再训练:根据下游损失,选择性地更新对损失影响最大的概念预测器。
关键创新:GCP框架的关键创新在于:1) 推理过程显式建模:将LLM的推理过程建模为概念预测图,使得学生模型能够更好地理解和学习LLM的推理过程。2) 图感知的学习策略:利用图结构选择信息量最大的样本进行标注,提高样本效率。3) 有针对性的子模块再训练:根据下游损失,选择性地更新对损失影响最大的概念预测器,提高训练效率和稳定性。与现有方法相比,GCP能够更好地利用LLM的推理能力,并且能够针对性地进行训练和优化。
关键设计:GCP的关键设计包括:1) 概念预测器的选择:根据具体的任务和LLM的推理过程,选择合适的概念作为预测目标。2) 图结构的构建:根据概念之间的依赖关系,构建有向无环图。3) 损失函数的设计:使用交叉熵损失函数来训练概念预测器,并使用正则化项来防止过拟合。4) 主动学习策略:使用不确定性采样和分歧采样相结合的方法来选择信息量最大的样本进行标注。5) 子模块再训练策略:使用梯度下降法来更新概念预测器的参数,并使用学习率衰减策略来提高训练稳定性。
🖼️ 关键图片

📊 实验亮点
在八个NLP分类基准测试中,GCP在有限的标注预算下显著优于现有的蒸馏方法。例如,在某些任务上,GCP仅使用少量标注数据就能达到与使用大量数据训练的基线模型相当甚至更高的性能。此外,GCP还提供了对模型推理过程的可视化和控制能力,使得用户能够更好地理解和调试模型。
🎯 应用场景
GCP框架可应用于各种需要将LLM推理能力迁移到小型模型的场景,例如移动设备上的自然语言处理、资源受限环境下的智能问答系统、以及需要可解释性和可控性的决策支持系统。该框架能够降低部署成本,提高推理速度,并提供对模型推理过程的深入理解。
📄 摘要(原文)
Deploying Large Language Models (LLMs) for discriminative workloads is often limited by inference latency, compute, and API costs at scale. Active distillation reduces these costs by querying an LLM oracle to train compact discriminative students, but most pipelines distill only final labels, discarding intermediate reasoning signals and offering limited diagnostics of what reasoning is missing and where errors arise. We propose Graph of Concept Predictors (GCP), a reasoning-aware active distillation framework that externalizes the teacher's decision process as a directed acyclic graph and mirrors it with modular concept predictors in the student. GCP enhances sample efficiency through a graph-aware acquisition strategy that targets uncertainty and disagreement at critical reasoning nodes. Additionally, it improves training stability and efficiency by performing targeted sub-module retraining, which attributes downstream loss to specific concept predictors and updates only the most influential modules. Experiments on eight NLP classification benchmarks demonstrate that GCP enhances performance under limited annotation budgets while yielding more interpretable and controllable training dynamics. Code is available at: https://github.com/Ziyang-Yu/GCP.