Large Language Models Can Take False First Steps at Inference-time Planning
作者: Haijiang Yan, Jian-Qiao Zhu, Adam Sanborn
分类: cs.AI
发布日期: 2026-02-03
💡 一句话要点
大型语言模型在推理时规划中存在虚假先验步骤问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理时规划 贝叶斯模型 自我生成上下文 规划能力退化
📋 核心要点
- 大型语言模型在训练中展现了规划能力,但在推理时却表现出短视和不一致的行为,这是一个待解决的问题。
- 论文提出了一种基于贝叶斯理论的解释,认为推理过程中累积的自我生成上下文导致了规划行为的转变。
- 通过随机生成和高斯采样实验,验证了模型,并观察到人工提示约束规划和自我生成上下文增强规划的现象。
📝 摘要(中文)
大型语言模型(LLMs)在训练过程中表现出序列级别的规划能力,但它们在推理时表现出的规划行为通常显得短视,与这些能力不符。我们提出了一个贝叶斯解释来解释这种差距,该解释将规划行为置于不断发展的生成上下文中:考虑到自然语言和LLMs内化的语言之间的细微差异,累积的自我生成上下文驱动了推理过程中的规划转变,从而造成了规划行为受损的假象。我们通过两个受控实验进一步验证了所提出的模型:一个随机生成任务,展示了在人工提示下受约束的规划以及随着自我生成上下文的积累而增加的规划强度;以及一个高斯采样任务,展示了在以自我生成的序列为条件时初始偏差的减少。这些发现为描述LLMs在推理过程中如何提前规划提供了理论解释和经验证据。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在推理时规划能力退化的问题。尽管LLMs在训练阶段表现出强大的序列规划能力,但在实际推理过程中,其规划行为往往显得短视且不一致,无法充分利用其内在的规划潜力。现有的方法缺乏对这种现象的有效解释和缓解策略。
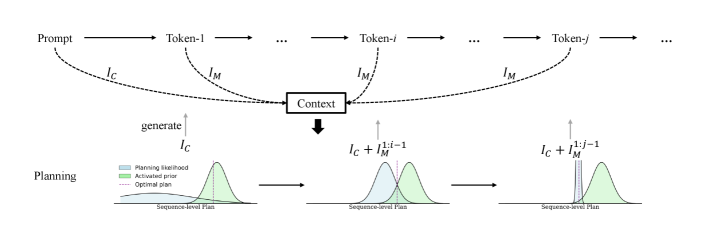
核心思路:论文的核心思路是基于贝叶斯理论,将LLMs的规划行为置于一个动态变化的生成上下文中。作者认为,LLMs在推理过程中生成的文本会反过来影响其后续的规划决策。由于自然语言和LLMs内部语言存在差异,累积的自我生成上下文会逐渐改变LLMs的规划方向,导致规划能力下降。
技术框架:论文构建了一个理论模型,用于描述LLMs在推理过程中的规划行为。该模型基于贝叶斯框架,将LLMs的规划过程建模为一个概率推断过程,其中先验知识来自训练数据,似然函数则由LLMs的生成能力决定。随着自我生成上下文的积累,先验知识逐渐被自我生成的文本所影响,从而导致规划行为的转变。
关键创新:论文最重要的创新点在于提出了一个基于贝叶斯框架的理论模型,用于解释LLMs在推理时规划能力退化的现象。该模型强调了自我生成上下文对LLMs规划行为的影响,并提供了一个统一的视角来理解LLMs的规划过程。
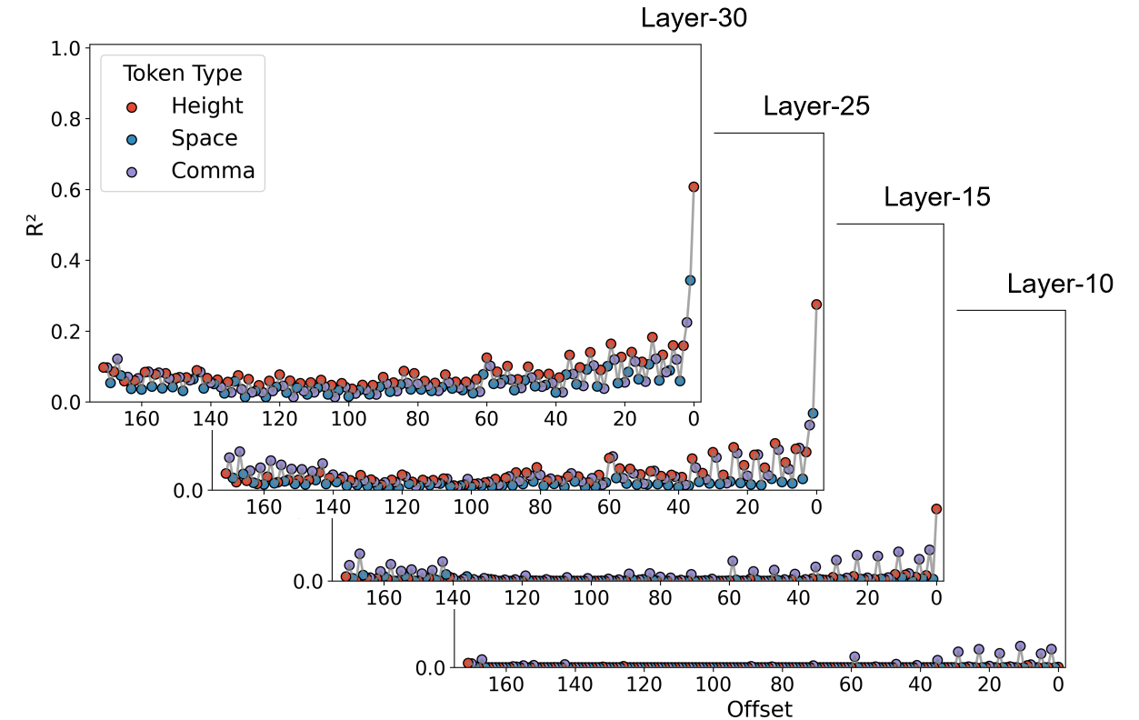
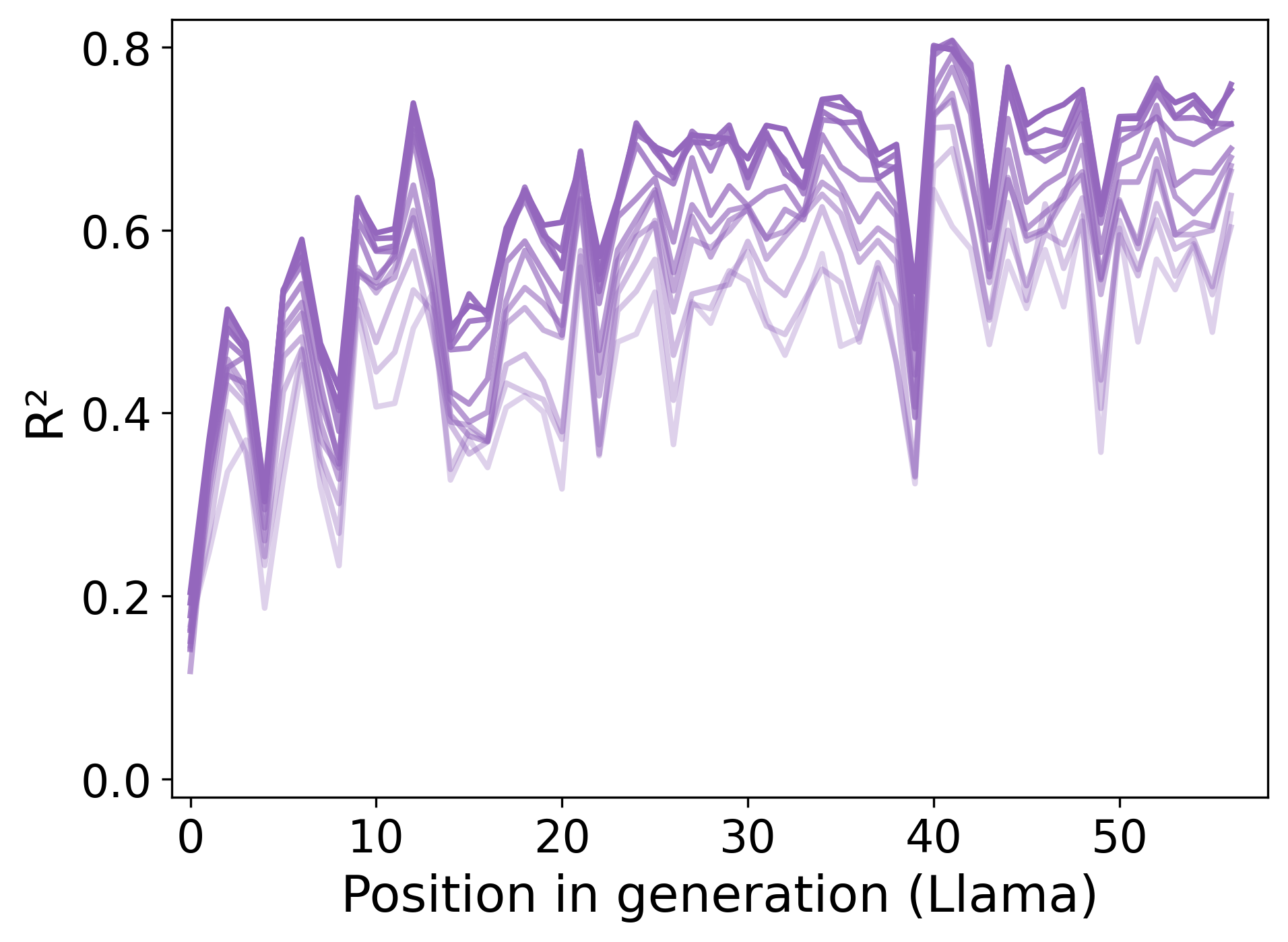
关键设计:论文设计了两个关键的实验来验证所提出的模型。第一个是随机生成任务,通过人工提示来约束LLMs的规划行为,并观察随着自我生成上下文的积累,LLMs的规划强度如何变化。第二个是高斯采样任务,通过以自我生成的序列为条件,来观察LLMs的初始偏差是否会减少。这些实验的设计旨在量化自我生成上下文对LLMs规划行为的影响。
🖼️ 关键图片
📊 实验亮点
论文通过随机生成任务和高斯采样任务验证了提出的贝叶斯模型。在随机生成任务中,观察到人工提示可以约束LLMs的规划行为,并且随着自我生成上下文的积累,LLMs的规划强度逐渐增加。在高斯采样任务中,发现以自我生成的序列为条件可以减少LLMs的初始偏差。这些实验结果为所提出的理论模型提供了有力的经验支持。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种任务中的推理能力,例如对话生成、文本摘要、代码生成等。通过理解和缓解推理时规划能力退化的问题,可以使LLMs在实际应用中更加可靠和有效。未来的研究可以探索如何设计更有效的干预策略,以防止或逆转这种规划转变。
📄 摘要(原文)
Large language models (LLMs) have been shown to acquire sequence-level planning abilities during training, yet their planning behavior exhibited at inference time often appears short-sighted and inconsistent with these capabilities. We propose a Bayesian account for this gap by grounding planning behavior in the evolving generative context: given the subtle differences between natural language and the language internalized by LLMs, accumulated self-generated context drives a planning-shift during inference and thereby creates the appearance of compromised planning behavior. We further validate the proposed model through two controlled experiments: a random-generation task demonstrating constrained planning under human prompts and increasing planning strength as self-generated context accumulates, and a Gaussian-sampling task showing reduced initial bias when conditioning on self-generated sequences. These findings provide a theoretical explanation along with empirical evidence for characterizing how LLMs plan ahead during inference.