Breaking the Reversal Curse in Autoregressive Language Models via Identity Bridge
作者: Xutao Ma, Yixiao Huang, Hanlin Zhu, Somayeh Sojoudi
分类: cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出身份桥接方法以解决自回归语言模型的反转诅咒问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自回归模型 逻辑推理 身份桥接 语言模型 深度学习 知识推导 梯度下降
📋 核心要点
- 核心问题:自回归语言模型在逻辑推理中存在反转诅咒,无法从正向知识推导反向知识,限制了其推理能力。
- 方法要点:提出身份桥接方法,通过在训练数据中引入"$A o A$"的示例,来帮助模型学习更高层次的推理规则。
- 实验或效果:经过身份桥接微调的模型在反转任务上成功率达到40%,显著高于仅使用正向知识数据训练的近零成功率。
📝 摘要(中文)
自回归大型语言模型在许多复杂任务中取得了显著成功,但在简单逻辑推理中仍然存在失败,尤其是反转诅咒问题。本文提出了一种名为身份桥接的正则化数据方法,通过在训练数据中引入形式为"$A o A$"的示例,来缓解这一固有限制。理论上,我们证明了即使是单层变换器也能通过分析梯度下降的隐含偏差来打破反转诅咒。实证结果显示,经过该方法微调的1B参数预训练语言模型在反转任务上的成功率达到了40%,而仅使用正向知识数据训练时的成功率接近于零。我们的研究为反转诅咒提供了新的理论基础,并为鼓励语言模型从数据中学习更高层次规则提供了一条有原则、低成本的路径。
🔬 方法详解
问题定义:本文旨在解决自回归语言模型在逻辑推理中的反转诅咒问题,即模型无法从形式为"$A o B$"的知识推导出"$B o A$"的知识。现有方法普遍认为这是自回归模型的固有限制,导致模型更倾向于记忆事实级别的知识,而非捕捉更高层次的推理规则。
核心思路:论文提出了一种简单的正则化数据方法,称为身份桥接,形式为"$A o A$",例如"Alice的名字是Alice"。通过这种方式,模型能够在训练过程中学习到更高层次的推理规则,从而缓解反转诅咒。
技术框架:整体架构包括数据预处理、模型训练和评估三个主要阶段。在数据预处理阶段,引入身份桥接示例;在模型训练阶段,使用带有身份桥接的训练数据微调预训练模型;在评估阶段,测试模型在反转任务上的表现。
关键创新:最重要的技术创新在于身份桥接方法的提出,这一方法通过引入自我指向的示例,改变了模型的学习方式,使其能够捕捉更高层次的逻辑推理规则,与传统方法形成鲜明对比。
关键设计:在模型训练中,采用了标准的交叉熵损失函数,同时在数据集中增加了身份桥接示例,以确保模型在学习过程中能够接触到这些新的推理模式。
🖼️ 关键图片
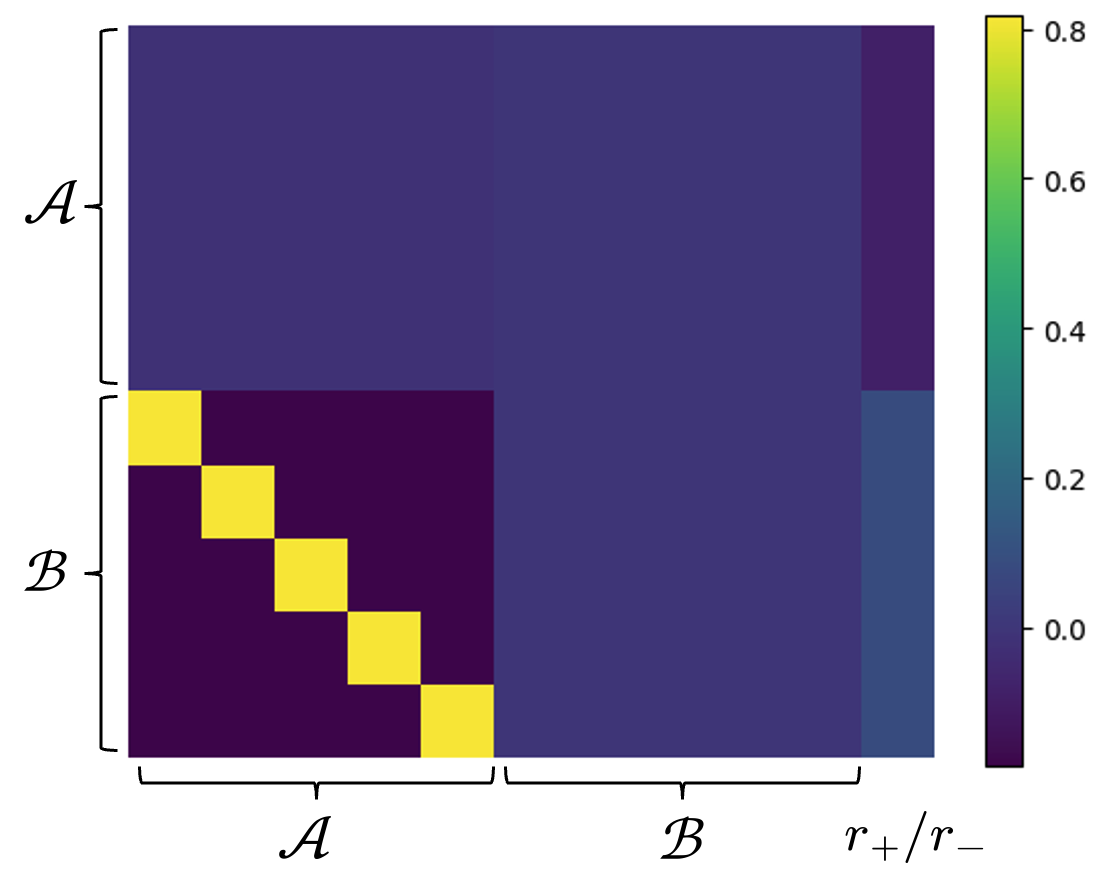
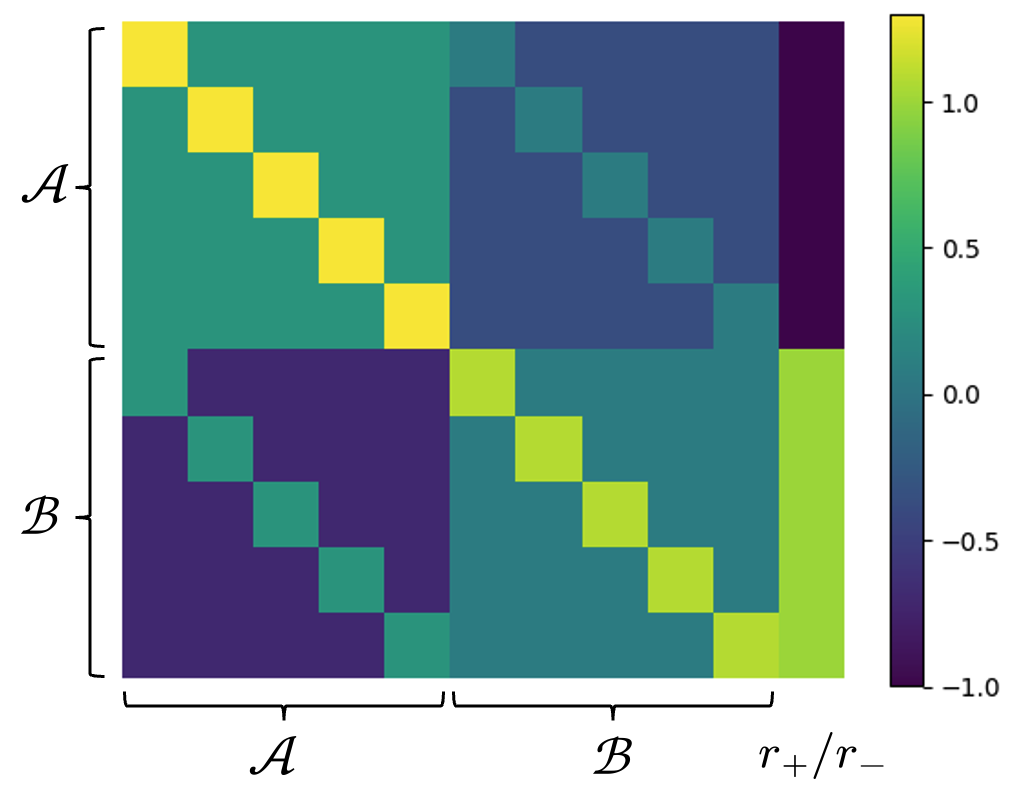

📊 实验亮点
实验结果显示,经过身份桥接微调的1B参数预训练语言模型在反转任务上的成功率达到了40%,相比之下,仅使用正向知识数据训练的模型成功率接近于零,提升幅度显著,证明了身份桥接方法的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能问答系统和对话系统等。通过改善语言模型的推理能力,能够提升这些系统在复杂逻辑推理任务中的表现,进而增强其实际应用价值。未来,该方法可能为更多领域的推理任务提供新的解决方案。
📄 摘要(原文)
Autoregressive large language models (LLMs) have achieved remarkable success in many complex tasks, yet they can still fail in very simple logical reasoning such as the "reversal curse" -- when trained on forward knowledge data of the form "$A \rightarrow B$" (e.g., Alice's husband is Bob), the model is unable to deduce the reversal knowledge "$B \leftarrow A$" (e.g., Bob's wife is Alice) during test. Extensive prior research suggests that this failure is an inherent, fundamental limit of autoregressive causal LLMs, indicating that these models tend to memorize factual-level knowledge rather than capture higher-level rules. In this paper, we challenge this view by showing that this seemingly fundamental limit can be mitigated by slightly tweaking the training data with a simple regularization data recipe called the Identity Bridge of the form "$A \to A$" (e.g., The name of Alice is Alice). Theoretically, we prove that under this recipe, even a one-layer transformer can break the reversal curse by analyzing the implicit bias of gradient descent. Empirically, we show that a 1B pretrained language model finetuned with the proposed data recipe achieves a 40% success rate on reversal tasks, in stark contrast to a near-zero success rate when trained solely on forward-knowledge data. Our work provides a novel theoretical foundation for the reversal curse and offers a principled, low-cost path to encouraging LLMs to learn higher-level rules from data.