MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
作者: Jana Zeller, Thaddäus Wiedemer, Fanfei Li, Thomas Klein, Prasanna Mayilvahanan, Matthias Bethge, Felix Wichmann, Ryan Cotterell, Wieland Brendel
分类: cs.AI, cs.CV, cs.LG
发布日期: 2026-02-02
备注: 9 pages, 8 figures
💡 一句话要点
MentisOculi:揭示心智图像推理的局限性,评估多模态模型利用视觉信息的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉推理 心智图像 基准测试 大型语言模型 统一多模态模型 生成模型
📋 核心要点
- 现有MLLM和UMM模型在利用视觉信息进行推理方面存在不足,尤其是在复杂的多步骤推理任务中。
- 论文提出MentisOculi基准,旨在评估模型形成、维持和操纵视觉表征以辅助推理的能力。
- 实验表明,即使模型能够生成正确的视觉信息,也难以有效利用这些信息来提升推理性能,揭示了视觉推理的局限性。
📝 摘要(中文)
前沿模型正从仅摄取视觉信息的多模态大型语言模型(MLLM)过渡到能够进行原生交错生成的多模态统一模型(UMM)。这种转变引发了人们对使用中间可视化作为推理辅助手段的兴趣,类似于人类的心智图像。这个想法的核心是形成、维持和以目标导向方式操纵视觉表征的能力。为了评估和探究这种能力,我们开发了MentisOculi,这是一个程序化的、分层的多步骤推理问题套件,适用于视觉解决方案,旨在挑战前沿模型。通过评估从潜在token到显式生成图像的各种视觉策略,我们发现它们通常无法提高性能。对UMM的分析特别揭示了一个关键限制:虽然它们具有解决任务的文本推理能力,并且有时可以生成正确的视觉效果,但它们会遭受复合生成错误的影响,甚至无法利用ground-truth可视化。我们的研究结果表明,尽管视觉思考具有内在吸引力,但它尚未能使模型推理受益。MentisOculi为分析和弥合不同模型系列之间的差距奠定了必要的基础。
🔬 方法详解
问题定义:论文旨在解决多模态模型(特别是UMM)在利用视觉信息进行复杂推理时遇到的困难。现有方法,如MLLM,主要依赖于文本信息进行推理,而忽略了视觉信息在推理过程中的潜在作用。即使模型能够生成视觉信息,也难以有效地将其融入到推理过程中,导致性能提升有限。因此,如何评估和提升模型利用视觉信息进行推理的能力是一个关键问题。
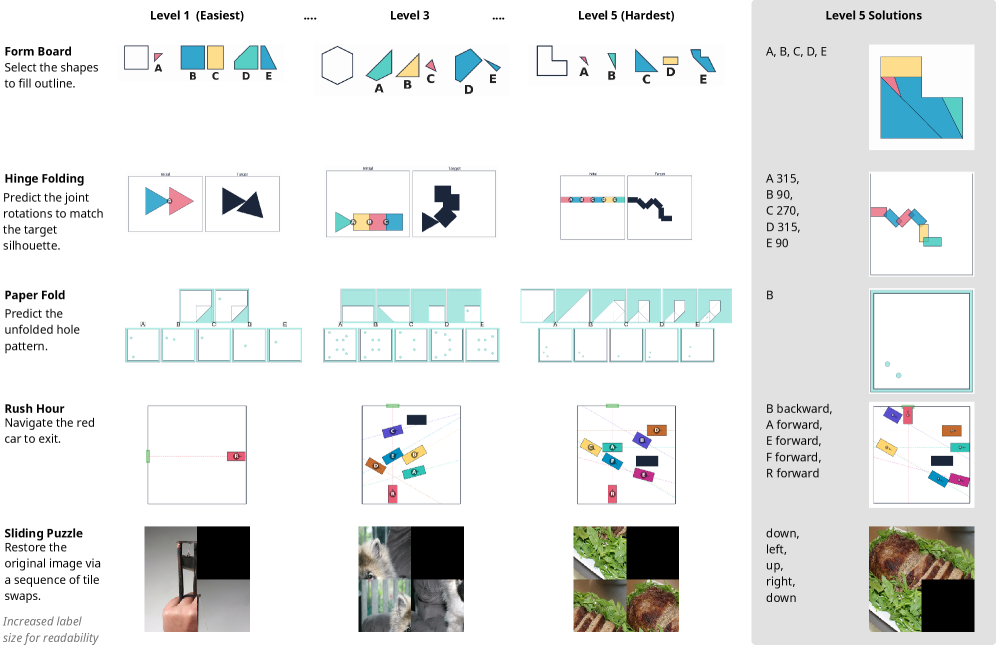
核心思路:论文的核心思路是构建一个专门用于评估模型视觉推理能力的基准测试集MentisOculi。该基准包含一系列多步骤推理问题,这些问题可以通过视觉方式解决。通过分析模型在解决这些问题时的表现,可以深入了解模型在形成、维持和操纵视觉表征方面的能力。同时,论文还探索了不同的视觉策略,例如使用潜在token和显式生成图像,以评估它们对推理性能的影响。
技术框架:MentisOculi基准测试集是一个程序化的、分层的多步骤推理问题套件。它允许研究人员系统地评估模型在不同难度级别和不同类型的视觉推理任务中的表现。评估流程包括:1) 给定一个推理问题;2) 模型尝试生成或利用视觉信息;3) 模型基于视觉信息和文本信息进行推理;4) 评估模型推理的准确性。论文还分析了UMM在生成视觉信息和利用ground-truth视觉信息方面的表现。
关键创新:该论文的关键创新在于提出了MentisOculi基准测试集,这是一个专门用于评估多模态模型视觉推理能力的工具。与现有的多模态基准测试集相比,MentisOculi更加关注模型在形成、维持和操纵视觉表征方面的能力,并提供了一系列具有挑战性的多步骤推理问题。此外,论文还深入分析了UMM在视觉推理方面的局限性,揭示了模型在生成和利用视觉信息时遇到的困难。
关键设计:MentisOculi基准测试集的设计考虑了以下关键因素:1) 程序化生成:问题是程序化生成的,可以控制难度和类型;2) 分层结构:问题分为不同的难度级别,可以逐步评估模型的推理能力;3) 多步骤推理:问题需要多个推理步骤才能解决,考验模型的长期记忆和推理能力;4) 视觉解决方案:问题可以通过视觉方式解决,鼓励模型利用视觉信息进行推理。论文还探索了不同的视觉策略,例如使用潜在token和显式生成图像,并分析了它们对推理性能的影响。
🖼️ 关键图片
📊 实验亮点
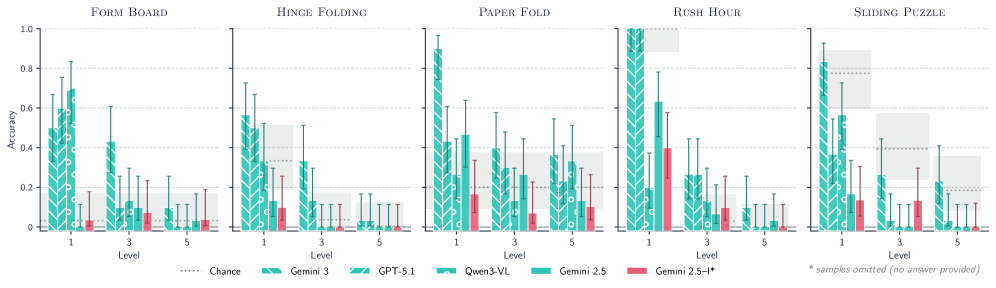
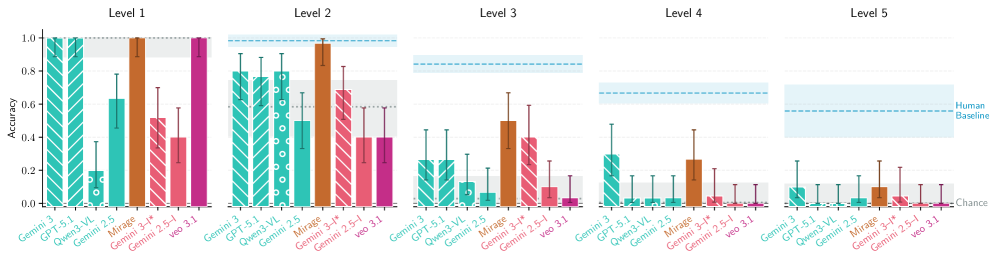
实验结果表明,即使是最先进的UMM模型在MentisOculi基准测试集上的表现仍然不尽如人意,即使提供了ground-truth可视化,模型也难以有效利用。这表明当前的多模态模型在视觉推理方面存在显著的局限性,需要进一步的研究和改进。该研究为未来的多模态模型研究提供了重要的方向。
🎯 应用场景
该研究成果可应用于提升多模态模型的推理能力,尤其是在需要视觉信息的复杂任务中,例如机器人导航、图像理解、视频分析等领域。通过更好地理解和利用视觉信息,可以开发出更智能、更可靠的多模态人工智能系统。未来,该研究可以推动开发更有效的视觉推理算法和模型架构。
📄 摘要(原文)
Frontier models are transitioning from multimodal large language models (MLLMs) that merely ingest visual information to unified multimodal models (UMMs) capable of native interleaved generation. This shift has sparked interest in using intermediate visualizations as a reasoning aid, akin to human mental imagery. Central to this idea is the ability to form, maintain, and manipulate visual representations in a goal-oriented manner. To evaluate and probe this capability, we develop MentisOculi, a procedural, stratified suite of multi-step reasoning problems amenable to visual solution, tuned to challenge frontier models. Evaluating visual strategies ranging from latent tokens to explicit generated imagery, we find they generally fail to improve performance. Analysis of UMMs specifically exposes a critical limitation: While they possess the textual reasoning capacity to solve a task and can sometimes generate correct visuals, they suffer from compounding generation errors and fail to leverage even ground-truth visualizations. Our findings suggest that despite their inherent appeal, visual thoughts do not yet benefit model reasoning. MentisOculi establishes the necessary foundation to analyze and close this gap across diverse model families.