Structure Enables Effective Self-Localization of Errors in LLMs
作者: Ankur Samanta, Akshayaa Magesh, Ayush Jain, Kavosh Asadi, Youliang Yu, Daniel Jiang, Boris Vidolov, Kaveh Hassani, Paul Sajda, Jalaj Bhandari, Yonathan Efroni
分类: cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出Thought-ICS框架,通过结构化推理实现LLM的有效误差自定位与修正
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自我纠正 结构化推理 思维链 错误定位
📋 核心要点
- 现有语言模型在自我纠正方面存在困难,难以有效定位和修正推理过程中的错误。
- 论文提出Thought-ICS框架,通过结构化思维步骤,使模型能够更精确地定位推理过程中的错误。
- 实验表明,Thought-ICS在自我纠正方面取得了显著提升,尤其是在自主设置下优于现有基线。
📝 摘要(中文)
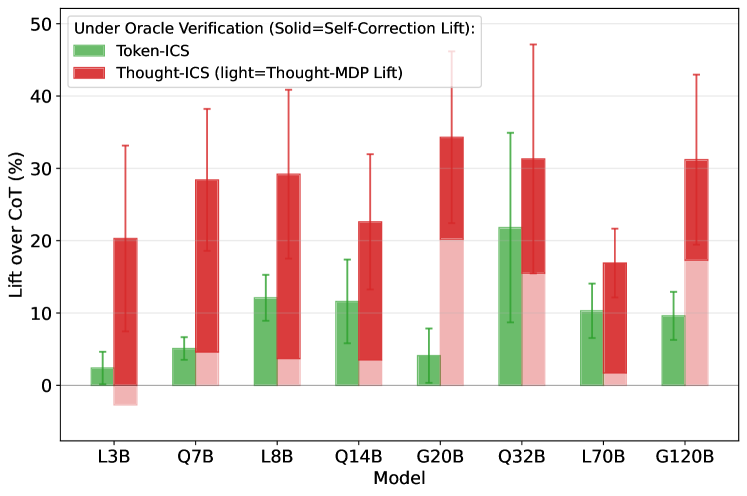
语言模型中的自我纠正能力仍然难以实现。本文探讨了语言模型是否能够显式地定位不正确推理中的错误,以此作为构建能够有效自我纠正的AI系统的途径。我们引入了一种提示方法,该方法将推理构建为离散的、语义连贯的思维步骤,并表明模型能够可靠地定位这种结构中的错误,但在传统的、非结构化的思维链推理中则无法做到这一点。受到人脑如何在离散决策点监控错误并重新采样替代方案的启发,我们引入了思维迭代纠正采样(Thought-ICS),这是一种自我纠正框架。Thought-ICS迭代地提示模型一次生成一个离散且完整的思维,其中每个思维代表模型的一个深思熟虑的决策,从而为精确的错误定位创建自然边界。经过验证后,模型定位第一个错误的步骤,系统回溯以从最后一个正确的点生成替代推理。当被要求纠正由预言机验证为不正确的推理时,Thought-ICS实现了20-40%的自我纠正提升。在没有外部验证的完全自主设置中,它优于当前的自我纠正基线。
🔬 方法详解
问题定义:现有的大语言模型在进行复杂推理时,虽然可以通过思维链(Chain-of-Thought)的方式提升性能,但当推理出现错误时,很难定位到具体的错误步骤并进行修正。传统的思维链方法缺乏结构化的推理过程,导致模型难以进行有效的错误自定位。
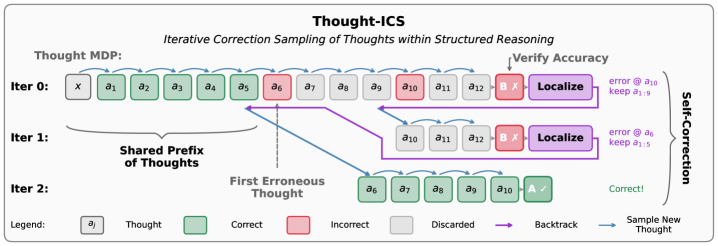
核心思路:论文的核心思路是将推理过程分解为一系列离散的、语义连贯的“思维步骤”(Thought Steps),每个步骤代表一个独立的决策。通过这种结构化的方式,模型可以更容易地识别和定位错误的步骤。同时,借鉴人类在决策过程中监控错误并重新采样的机制,设计迭代纠正采样方法。
技术框架:Thought-ICS框架包含以下几个主要阶段: 1. 结构化推理生成:模型按照预定义的结构,逐步生成推理过程中的每个思维步骤。 2. 错误定位:对生成的推理过程进行验证(可以使用外部预言机或模型自身的判断),如果发现错误,则定位到第一个错误的思维步骤。 3. 回溯与修正:从最后一个正确的思维步骤开始,重新生成后续的推理过程,尝试修正错误。 4. 迭代优化:重复上述过程,直到生成正确的推理结果或达到最大迭代次数。
关键创新:该方法最重要的创新点在于引入了结构化的思维步骤,将复杂的推理过程分解为一系列可控的决策点。这种结构化方法使得错误定位更加精确,为自我纠正提供了基础。与传统的非结构化思维链相比,Thought-ICS能够更有效地利用模型自身的知识和推理能力进行错误修正。
关键设计:论文的关键设计包括: 1. 思维步骤的定义:需要根据具体的任务设计合适的思维步骤,确保每个步骤都具有明确的语义含义。 2. 错误验证机制:可以使用外部预言机(如人工标注)或模型自身的判断来验证推理过程的正确性。模型自身的判断可以通过设计特定的提示语或训练额外的验证模型来实现。 3. 回溯策略:确定从哪个步骤开始回溯以及如何重新生成后续的推理过程。可以采用不同的采样策略,如Top-k采样或Nucleus采样,以增加生成多样性。
🖼️ 关键图片
📊 实验亮点
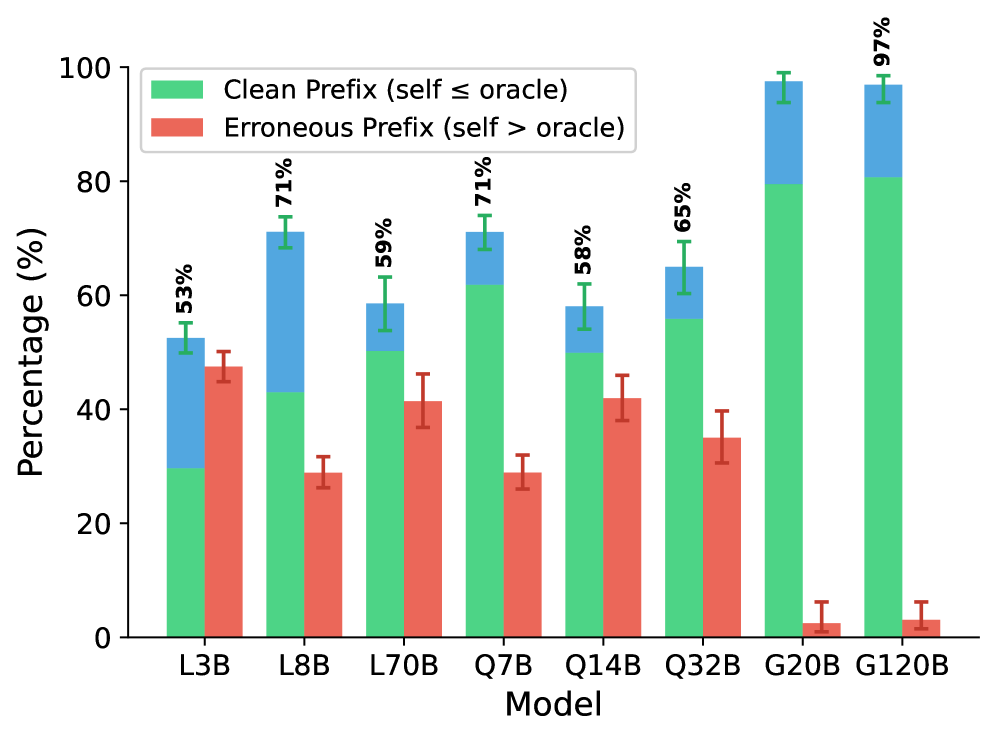
实验结果表明,在有外部预言机验证的情况下,Thought-ICS能够实现20-40%的自我纠正提升。在完全自主的设置下,Thought-ICS也优于现有的自我纠正基线。这些结果表明,结构化推理和迭代纠正采样是提高语言模型自我纠正能力的有效途径。
🎯 应用场景
该研究成果可应用于提升大语言模型在各种推理任务中的可靠性和准确性,例如数学问题求解、代码生成、知识问答等。通过自我纠正机制,可以减少对人工干预的依赖,提高模型的自主性和适应性。未来,该方法有望应用于构建更智能、更可靠的AI系统。
📄 摘要(原文)
Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.