Interpreting and Controlling LLM Reasoning through Integrated Policy Gradient
作者: Changming Li, Kaixing Zhang, Haoyun Xu, Yingdong Shi, Zheng Zhang, Kaitao Song, Kan Ren
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出IPG方法,通过积分策略梯度实现对LLM推理过程的解释与控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 推理控制 积分梯度 策略梯度
📋 核心要点
- 现有LLM可解释性方法难以精确定位复杂推理机制,也无法捕捉模型内部运作对推理输出的顺序影响。
- 论文提出积分策略梯度(IPG)框架,通过追踪推理轨迹,将推理行为归因于模型内部组件的贡献。
- 实验表明,IPG能更精确地定位推理组件,并实现对推理能力和强度的可靠调节。
📝 摘要(中文)
大型语言模型(LLMs)在解决复杂的现实世界问题中表现出强大的推理能力。然而,驱动这些复杂推理行为的内部机制仍然不透明。现有的针对推理的可解释性方法要么识别与特殊文本模式相关的组件(例如,神经元),要么依赖于人工标注的对比对来导出控制向量。因此,当前的方法难以精确定位复杂的推理机制,也难以捕捉从模型内部运作到推理输出的顺序影响。在本文中,基于面向结果和顺序影响感知的原则,我们专注于识别对推理行为具有顺序贡献的组件,其中结果通过长期效应累积。我们提出了一种新的框架——积分策略梯度(IPG),通过将基于复合结果的信号(例如,推理后的准确性)向后传播通过模型推理轨迹,将推理行为归因于模型的内部组件。实证评估表明,我们的方法实现了更精确的定位,并能够可靠地调节不同推理模型中的推理行为(例如,推理能力、推理强度)。
🔬 方法详解
问题定义:现有的大型语言模型推理过程如同黑盒,难以理解其内部机制。现有的可解释性方法,如基于文本模式关联或人工标注对比对的方法,无法精确定位复杂的推理机制,也忽略了模型内部运作对推理输出的顺序影响,导致无法有效控制推理行为。
核心思路:论文的核心思路是,将推理过程视为一个策略学习过程,通过计算每个组件对最终推理结果的贡献度,来解释和控制LLM的推理行为。核心在于将最终的推理结果(例如,准确率)反向传播到模型的内部组件,从而确定哪些组件对推理过程起到了关键作用。
技术框架:IPG框架主要包含以下几个阶段:1)前向推理:LLM执行推理任务,记录模型的内部状态和输出。2)结果评估:评估推理结果的质量(例如,准确率)。3)反向传播:使用积分梯度方法,将结果评估信号反向传播到模型的内部组件,计算每个组件对结果的贡献度。4)组件定位与控制:根据贡献度,定位关键的推理组件,并通过调整这些组件的状态来控制推理行为。
关键创新:IPG的关键创新在于,它将可解释性问题转化为一个策略梯度估计问题,通过积分梯度方法,可以有效地计算每个组件对最终结果的贡献度。与现有方法相比,IPG能够更精确地定位推理组件,并实现对推理行为的细粒度控制。此外,IPG考虑了推理过程的顺序性,能够捕捉模型内部运作对推理输出的长期影响。
关键设计:IPG使用积分梯度方法来计算每个组件的贡献度。具体来说,对于每个组件,IPG计算从一个基线状态到当前状态的积分梯度,作为该组件的贡献度。基线状态通常选择一个随机状态或一个零状态。损失函数通常是基于推理结果的质量(例如,准确率)定义的。关键参数包括积分路径的长度和积分步长。
🖼️ 关键图片


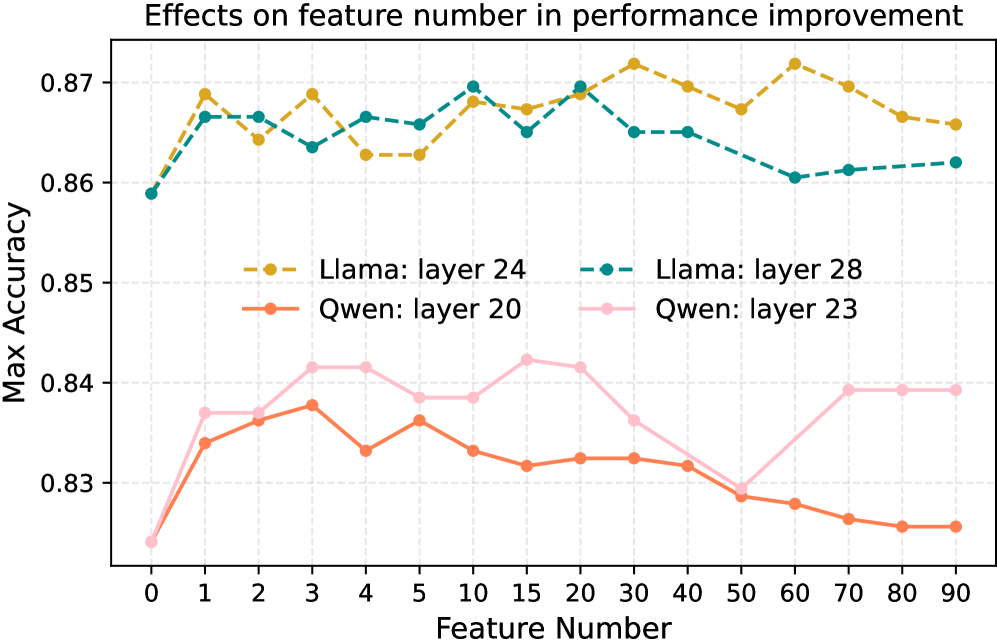
📊 实验亮点
实验结果表明,IPG能够更精确地定位LLM中的推理组件,并实现对推理行为的可靠控制。例如,通过调整关键组件的状态,可以显著提高LLM在特定推理任务上的准确率。与现有的可解释性方法相比,IPG在定位精度和控制效果方面均有显著提升。
🎯 应用场景
该研究成果可应用于提升LLM的可信度和安全性。通过理解LLM的推理过程,可以诊断和修复模型中的错误推理模式,防止模型产生有害或不准确的输出。此外,该方法还可以用于个性化LLM的推理行为,使其更符合特定用户的需求。
📄 摘要(原文)
Large language models (LLMs) demonstrate strong reasoning abilities in solving complex real-world problems. Yet, the internal mechanisms driving these complex reasoning behaviors remain opaque. Existing interpretability approaches targeting reasoning either identify components (e.g., neurons) correlated with special textual patterns, or rely on human-annotated contrastive pairs to derive control vectors. Consequently, current methods struggle to precisely localize complex reasoning mechanisms or capture sequential influence from model internal workings to the reasoning outputs. In this paper, built on outcome-oriented and sequential-influence-aware principles, we focus on identifying components that have sequential contribution to reasoning behavior where outcomes are cumulated by long-range effects. We propose Integrated Policy Gradient (IPG), a novel framework that attributes reasoning behaviors to model's inner components by propagating compound outcome-based signals such as post reasoning accuracy backward through model inference trajectories. Empirical evaluations demonstrate that our approach achieves more precise localization and enables reliable modulation of reasoning behaviors (e.g., reasoning capability, reasoning strength) across diverse reasoning models.