Position: Explaining Behavioral Shifts in Large Language Models Requires a Comparative Approach
作者: Martino Ciaperoni, Marzio Di Vece, Luca Pappalardo, Fosca Giannotti, Francesco Giannini
分类: cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出Δ-XAI框架,用于解释大语言模型行为转变
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 行为转变 可解释AI 比较分析 模型安全
📋 核心要点
- 现有XAI方法难以解释大语言模型在不同阶段的行为差异,无法有效追踪内部变化。
- 论文提出比较XAI(Δ-XAI)框架,通过对比参考模型和干预模型来解释行为转变。
- 论文设计了多种Δ-XAI流程,并进行了实验验证,展示了该框架的有效性。
📝 摘要(中文)
大规模基础模型表现出行为转变:干预引发的行为变化,出现在模型扩展、微调、强化学习或上下文学习之后。虽然对这些现象的研究最近受到了关注,但解释它们的出现仍然被忽视。经典的可解释AI(XAI)方法可以揭示模型在单个检查点上的失败,但它们在结构上不适合证明不同检查点之间内部发生了什么变化,以及哪些解释性声明是关于该变化的。我们认为,行为转变应该以比较的方式来解释:核心目标应该是参考模型和干预模型之间干预引发的转变,而不是孤立的任何单个模型。为此,我们提出了一个比较XAI(Δ-XAI)框架,其中包含一组在设计适当的解释方法时要考虑的期望。为了突出Δ-XAI方法的工作方式,我们介绍了一组可能的流程,将它们与期望联系起来,并提供了一个具体的Δ-XAI实验。
🔬 方法详解
问题定义:论文旨在解决大语言模型行为转变的可解释性问题。现有XAI方法主要关注单个模型的解释,无法有效解释模型在不同训练阶段(如微调、强化学习)或受到特定干预后产生的行为变化。这些方法缺乏比较视角,难以揭示导致行为转变的内部机制和关键因素。现有方法的痛点在于无法回答“模型为什么会发生这样的变化?”这类比较性问题。
核心思路:论文的核心思路是将行为转变的解释视为一个比较问题。不是孤立地解释某个模型的行为,而是对比参考模型(未经过干预或处于初始状态的模型)和干预模型(经过干预或训练后的模型)的行为差异。通过分析这两个模型之间的差异,可以更清晰地识别导致行为转变的关键因素和内部变化。
技术框架:Δ-XAI框架的核心是比较分析。它包含以下主要阶段:1) 定义参考模型和干预模型;2) 选择合适的解释方法,用于分析两个模型的行为;3) 对比两个模型的解释结果,识别差异;4) 分析差异的原因,例如哪些参数发生了显著变化,哪些神经元被激活等;5) 根据分析结果,提出关于行为转变的解释性声明。论文还提出了一系列设计Δ-XAI方法的期望,例如解释的忠实性、完整性和可理解性。
关键创新:论文最重要的技术创新在于提出了比较XAI(Δ-XAI)的概念和框架。与传统的XAI方法不同,Δ-XAI关注的是模型之间的差异,而不是单个模型本身。这种比较视角能够更有效地解释行为转变,并揭示导致这些转变的内部机制。Δ-XAI框架为研究大语言模型的行为变化提供了一个新的思路和工具。
关键设计:论文提出了多种可能的Δ-XAI流程,具体的设计取决于所使用的解释方法和要解释的行为转变类型。例如,可以使用基于梯度的方法来分析两个模型的梯度差异,或者使用基于注意力的方法来比较两个模型的注意力权重。关键在于选择合适的解释方法,并设计合理的比较策略,以有效地识别和分析模型之间的差异。
🖼️ 关键图片
📊 实验亮点
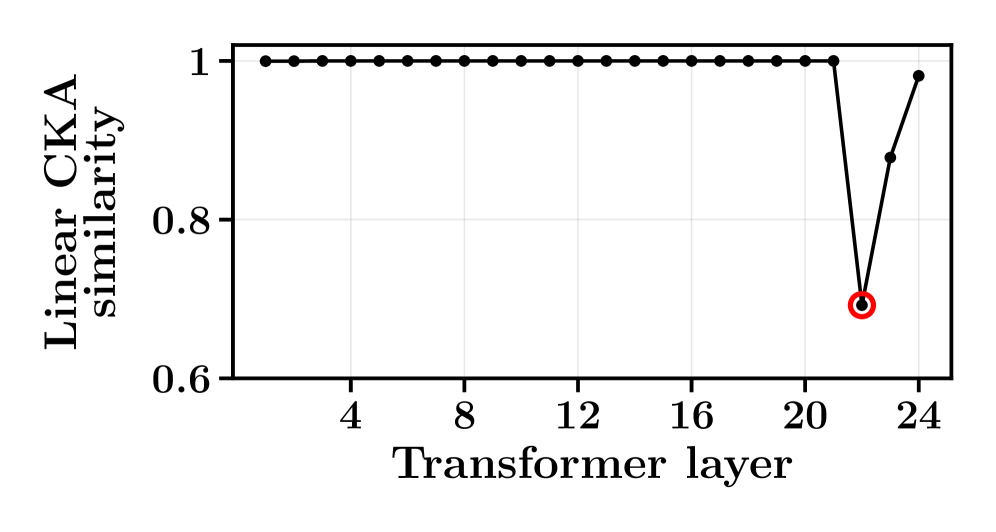
论文通过实验展示了Δ-XAI框架的有效性。实验结果表明,通过对比参考模型和干预模型的解释结果,可以清晰地识别导致行为转变的关键因素。例如,实验发现,在经过特定干预后,模型对某些关键词的注意力权重发生了显著变化,这解释了模型行为的转变。
🎯 应用场景
该研究成果可应用于大语言模型的安全性和可靠性评估,例如,可以用于分析微调或强化学习对模型行为的影响,识别潜在的有害行为转变,并采取相应的措施进行干预。此外,该方法还可以用于理解模型的学习过程,帮助研究人员更好地设计训练策略和模型架构。
📄 摘要(原文)
Large-scale foundation models exhibit behavioral shifts: intervention-induced behavioral changes that appear after scaling, fine-tuning, reinforcement learning or in-context learning. While investigating these phenomena have recently received attention, explaining their appearance is still overlooked. Classic explainable AI (XAI) methods can surface failures at a single checkpoint of a model, but they are structurally ill-suited to justify what changed internally across different checkpoints and which explanatory claims are warranted about that change. We take the position that behavioral shifts should be explained comparatively: the core target should be the intervention-induced shift between a reference model and an intervened model, rather than any single model in isolation. To this aim we formulate a Comparative XAI ($Δ$-XAI) framework with a set of desiderata to be taken into account when designing proper explaining methods. To highlight how $Δ$-XAI methods work, we introduce a set of possible pipelines, relate them to the desiderata, and provide a concrete $Δ$-XAI experiment.