More Than a Quick Glance: Overcoming the Greedy Bias in KV-Cache Compression
作者: Aryan Sood, Tanvi Sharma, Vansh Agrawal
分类: cs.AI, cs.CL
发布日期: 2026-02-02
💡 一句话要点
LASER-KV:通过精确LSH召回克服KV缓存压缩中的贪婪偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长文本处理 大型语言模型 注意力机制 局部敏感哈希
📋 核心要点
- 现有KV缓存压缩方法在长文本场景下,为了节省内存,过度依赖注意力分数进行剪枝,导致语义信息损失。
- LASER-KV采用分层累积选择策略,通过保护除数控制块大小,从而在压缩过程中更好地保留关键信息。
- 实验表明,LASER-KV在长文本任务中性能优于现有方法,在128k上下文长度下精度提升高达10%。
📝 摘要(中文)
大型语言模型(LLM)在理论上可以支持广泛的上下文窗口,但其实际部署受到键值(KV)缓存内存线性增长的限制。现有的压缩策略通过各种剪枝机制来缓解这个问题,但牺牲了语义召回率以换取内存效率。本文提出了LASER-KV(具有精确LSH召回的层累积选择),旨在严格的累积预算策略下测试KV压缩的极限。我们通过实现由保护除数(n)控制的分块累积策略,从而偏离了标准的固定摘要大小方法。这使我们能够将压缩的影响与滑动窗口伪影隔离开来。在Babilong基准测试上的实验表明,先前的压缩方法在各种长上下文任务上的性能下降了15-30%。LASER-KV保持了稳定的性能,在128k时达到了高达10%的卓越精度。这些发现挑战了当前认为注意力分数足以代表token效用的假设。
🔬 方法详解
问题定义:大型语言模型(LLM)的KV缓存大小随上下文长度线性增长,成为部署长上下文LLM的瓶颈。现有的KV缓存压缩方法通常采用贪婪策略,例如基于注意力分数进行剪枝,虽然降低了内存占用,但可能丢失重要的语义信息,导致长文本任务性能下降。
核心思路:LASER-KV的核心思路是通过一种分层累积选择策略,更精细地控制KV缓存的压缩过程,避免过度依赖注意力分数。它旨在通过更全面的token效用评估,在压缩过程中保留更多关键信息,从而提高长文本任务的性能。
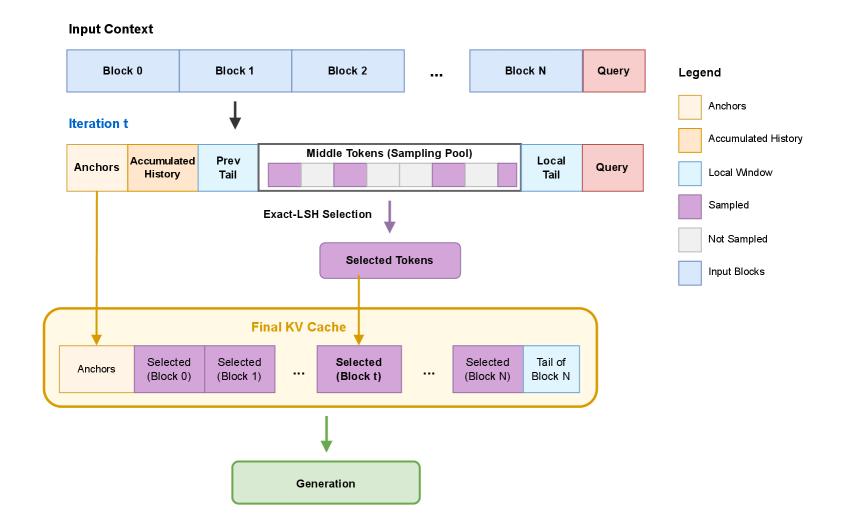
技术框架:LASER-KV框架包含以下主要步骤:1)将输入文本分成多个块;2)对每个块内的token进行效用评估(不完全依赖注意力分数,可能结合其他特征);3)根据保护除数(n)确定每个块需要保留的token数量;4)使用精确LSH(Locality Sensitive Hashing)进行高效的token召回和选择;5)将选择的token累积到KV缓存中。
关键创新:LASER-KV的关键创新在于其分层累积选择策略和精确LSH召回机制。与传统的固定摘要大小方法不同,LASER-KV允许根据块的重要性动态调整压缩比例。精确LSH的使用保证了高效的token召回,避免了因近似计算导致的精度损失。
关键设计:LASER-KV的关键设计包括:1)保护除数(n):控制每个块保留的token数量,避免过度压缩;2)token效用评估函数:除了注意力分数外,可能还包括其他token特征,例如词频、语义重要性等;3)精确LSH的参数设置:例如哈希函数的数量、哈希桶的大小等,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在Babilong基准测试中,LASER-KV在长上下文任务上显著优于现有的KV缓存压缩方法。具体而言,在128k上下文长度下,LASER-KV的精度提升高达10%,同时保持了稳定的性能。相比之下,先前的压缩方法性能下降了15-30%。这些结果表明,LASER-KV能够更有效地保留长文本中的关键信息。
🎯 应用场景
LASER-KV可应用于各种需要处理长文本的场景,例如长文档摘要、机器翻译、问答系统、代码生成等。通过更有效地压缩KV缓存,LASER-KV能够降低LLM的内存需求,使其能够在资源受限的设备上部署,并支持处理更长的上下文,从而提升相关应用的性能和用户体验。
📄 摘要(原文)
While Large Language Models (LLMs) can theoretically support extensive context windows, their actual deployment is constrained by the linear growth of Key-Value (KV) cache memory. Prevailing compression strategies mitigate this through various pruning mechanisms, yet trade-off semantic recall for memory efficiency. In this work, we present LASER-KV (Layer Accumulated Selection with Exact-LSH Recall), a framework designed to test the limits of KV compression under a strict accumulative budgeting policy. We deviate from the standard fixed summary size approach by implementing a block-wise accumulation strategy governed by a protection divisor (n). This allows us to isolate the effects of compression from sliding window artifacts. Our experiments on the Babilong benchmark reveal performance degradation in previous compression methods by 15-30% on various long context tasks. LASER-KV maintains stable performance, achieving superior accuracies by a margin of upto 10% at 128k. These findings challenge the prevailing assumption that attention scores alone are a sufficient proxy for token utility.