Understanding the Reversal Curse Mitigation in Masked Diffusion Models through Attention and Training Dynamics
作者: Sangwoo Shin, BumJun Kim, Kyelim Lee, Moongyu Jeon, Albert No
分类: cs.AI, cs.CL
发布日期: 2026-02-02
💡 一句话要点
通过注意力和训练动态理解掩码扩散模型中逆转诅咒的缓解
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 掩码扩散模型 逆转诅咒 注意力机制 训练动态 Transformer编码器
📋 核心要点
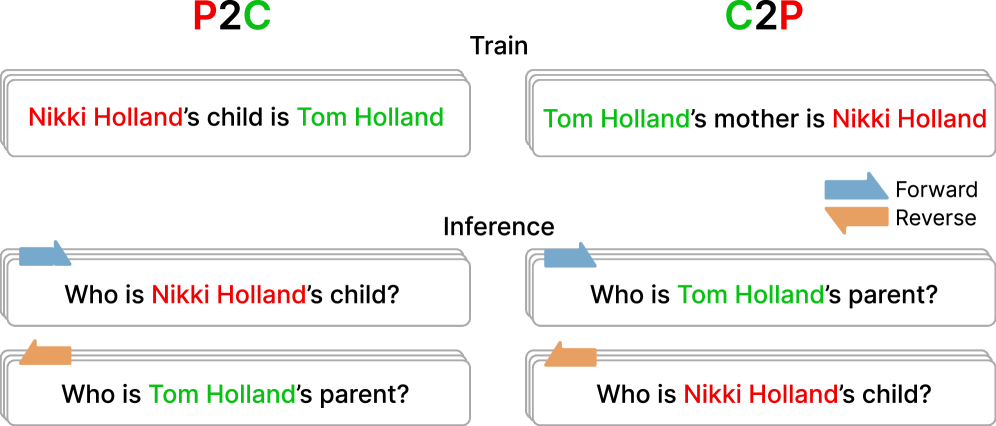
- 自回归模型在学习“A是B”后,难以回答“B是A”,即逆转诅咒,这是现有方法的显著不足。
- 论文核心思想是MDM缓解逆转诅咒并非仅因训练方式,而是架构和训练动态共同作用的结果。
- 实验表明,单层Transformer编码器中的权重共享和梯度对齐是MDM缓解逆转诅咒的关键机制。
📝 摘要(中文)
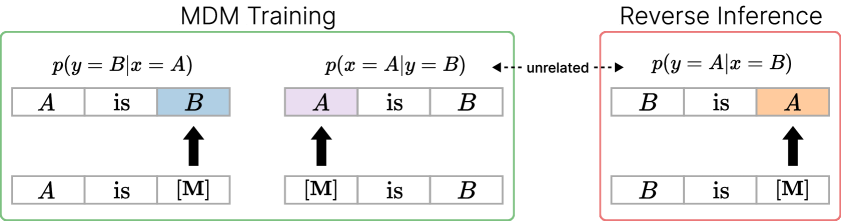
自回归语言模型(ARMs)存在逆转诅咒问题:在学习到“A是B”之后,它们通常无法回答反向查询“B是A”。基于掩码扩散的语言模型(MDMs)在较弱的程度上表现出这种失败,但其根本原因尚不清楚。一种常见的解释将这种缓解归因于任意顺序的训练目标。然而,在训练期间观察到“[MASK]是B”并不一定教会模型处理反向提示“B是[MASK]”。本文表明,这种缓解源于架构结构及其与训练的相互作用。在一个单层Transformer编码器中,权重共享通过使前向和反向注意力分数正相关来耦合两个方向。在相同的设置中,进一步表明相应的梯度是对齐的,因此最小化前向损失也会减少反向损失。在受控的玩具任务和大规模扩散语言模型上的实验都支持这些机制,解释了为什么MDMs部分克服了在强大的ARMs中仍然存在的失败模式。
🔬 方法详解
问题定义:论文旨在理解为什么掩码扩散模型(MDMs)比自回归模型(ARMs)更能缓解逆转诅咒。逆转诅咒是指模型在学习到“A是B”后,无法正确回答“B是A”的问题。现有研究认为MDMs的任意顺序训练是缓解的关键,但该论文认为这种解释并不充分,需要更深入的理解。
核心思路:论文的核心思路是分析MDMs的架构和训练动态,特别是Transformer编码器中的注意力机制和梯度更新。通过理论分析和实验验证,揭示了权重共享和梯度对齐在缓解逆转诅咒中的作用。论文认为,MDMs的架构设计使得前向和反向的注意力分数正相关,并且前向损失的梯度能够有效地减少反向损失。
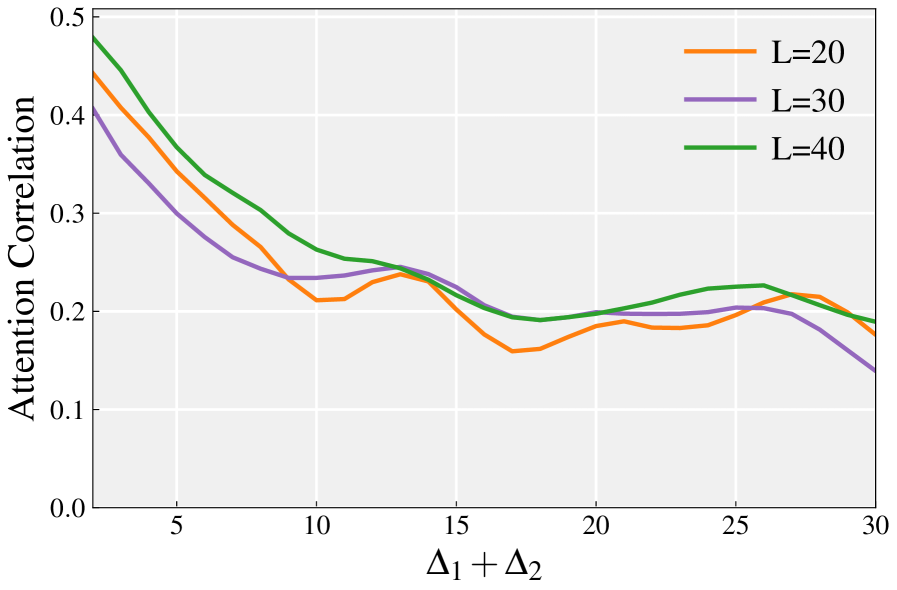
技术框架:论文主要研究单层Transformer编码器,分析其前向和反向注意力机制。通过数学推导,证明了在权重共享的情况下,前向和反向注意力分数之间存在正相关关系。同时,分析了前向和反向损失的梯度,证明了它们之间的对齐关系。论文还通过实验验证了这些理论分析的有效性。
关键创新:论文最重要的创新点在于揭示了MDMs缓解逆转诅咒的内在机制,即权重共享导致的注意力分数正相关和梯度对齐。这与以往认为的任意顺序训练是主要原因的观点不同,为理解MDMs的优势提供了新的视角。论文还通过理论分析和实验验证,为这些机制提供了有力的支持。
关键设计:论文的关键设计包括:1) 使用单层Transformer编码器进行理论分析,简化了模型复杂度,便于理解核心机制;2) 通过数学推导,证明了权重共享导致的前向和反向注意力分数之间的正相关关系;3) 分析了前向和反向损失的梯度,证明了它们之间的对齐关系;4) 使用受控的玩具任务和大规模扩散语言模型进行实验验证,验证了理论分析的有效性。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了理论分析的有效性。在受控的玩具任务中,验证了权重共享和梯度对齐对缓解逆转诅咒的作用。在大规模扩散语言模型上的实验表明,MDMs在逆转诅咒问题上的表现优于自回归模型,并且验证了注意力分数正相关和梯度对齐的现象。具体性能数据和提升幅度在论文中有详细描述。
🎯 应用场景
该研究成果有助于更好地理解和设计扩散语言模型,提升其在自然语言处理任务中的性能,例如问答系统、文本生成等。缓解逆转诅咒可以提高模型在知识推理和常识推理方面的能力,使其在实际应用中更加可靠和有效。此外,该研究也为其他类型的神经网络设计提供了借鉴,例如如何通过架构设计来提高模型的泛化能力。
📄 摘要(原文)
Autoregressive language models (ARMs) suffer from the reversal curse: after learning that "$A$ is $B$", they often fail on the reverse query "$B$ is $A$". Masked diffusion-based language models (MDMs) exhibit this failure in a much weaker form, but the underlying reason has remained unclear. A common explanation attributes this mitigation to the any-order training objective. However, observing "[MASK] is $B$" during training does not necessarily teach the model to handle the reverse prompt "$B$ is [MASK]". We show that the mitigation arises from architectural structure and its interaction with training. In a one-layer Transformer encoder, weight sharing couples the two directions by making forward and reverse attention scores positively correlated. In the same setting, we further show that the corresponding gradients are aligned, so minimizing the forward loss also reduces the reverse loss. Experiments on both controlled toy tasks and large-scale diffusion language models support these mechanisms, explaining why MDMs partially overcome a failure mode that persists in strong ARMs.