See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
作者: Ding Xia, Xinyue Gui, Mark Colley, Fan Gao, Zhongyi Zhou, Dongyuan Li, Renhe Jiang, Takeo Igarashi
分类: cs.HC, cs.AI
发布日期: 2026-02-02
备注: Under Review
💡 一句话要点
See2Refine:利用视觉-语言反馈提升LLM驱动的eHMI动作设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: eHMI设计 人机交互 自动驾驶 视觉-语言模型 大型语言模型
📋 核心要点
- 现有eHMI设计依赖人工,难以适应动态交通环境,且缺乏有效的自动优化方法。
- See2Refine利用VLM感知评估作为反馈,迭代优化LLM驱动的eHMI动作设计,无需人工干预。
- 实验表明,See2Refine在多种eHMI模式下均优于传统方法,且VLM评估与人类偏好一致。
📝 摘要(中文)
自动驾驶车辆缺乏与道路使用者的自然沟通渠道,因此外部人机界面(eHMI)对于传递意图和维持共享环境中的信任至关重要。然而,大多数eHMI研究依赖于开发者手工设计的消息-动作对,难以适应多样化和动态的交通环境。一个有前景的替代方案是使用大型语言模型(LLM)作为动作设计器,生成上下文相关的eHMI动作,但此类设计器缺乏感知验证,并且通常依赖于固定的提示或昂贵的人工标注反馈来改进。我们提出了See2Refine,一个无人参与的闭环框架,它使用视觉-语言模型(VLM)感知评估作为自动视觉反馈来改进基于LLM的eHMI动作设计器。给定驾驶环境和候选eHMI动作,VLM评估动作的感知适当性,并将此反馈用于迭代修改设计器的输出,从而在没有人为监督的情况下实现系统改进。我们在三种eHMI模式(灯条、眼睛和手臂)和多个LLM模型尺寸上评估了我们的框架。在各种设置中,我们的框架在基于VLM的指标和人类受试者评估中始终优于仅提示的LLM设计器和手动指定的基线。结果进一步表明,改进可以推广到各种模式,并且VLM评估与人类偏好高度一致,支持See2Refine在可扩展动作设计方面的鲁棒性和有效性。
🔬 方法详解
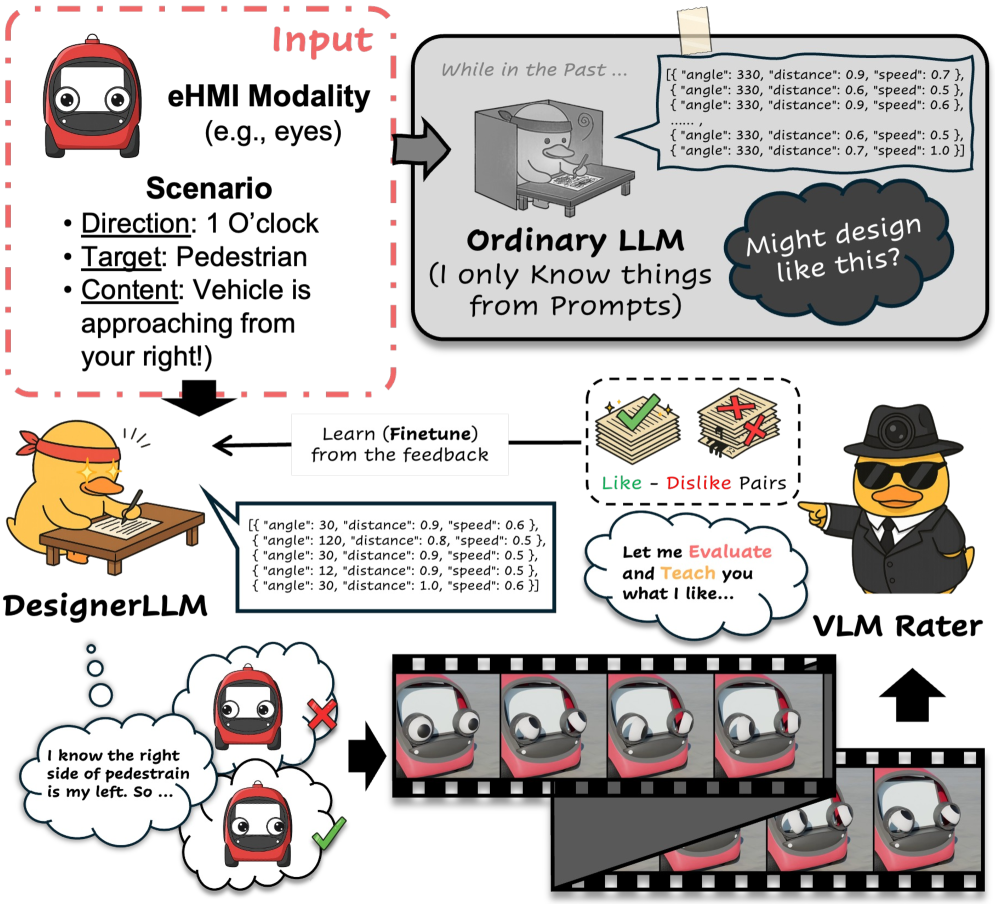
问题定义:现有eHMI设计方法依赖于人工设计,难以适应复杂和动态的交通环境。此外,基于LLM的eHMI动作设计器缺乏有效的感知验证机制,通常需要人工标注反馈或固定的提示来改进,成本高昂且效率低下。
核心思路:See2Refine的核心思路是利用视觉-语言模型(VLM)对eHMI动作的感知适当性进行自动评估,并将评估结果作为反馈信号,迭代优化LLM驱动的eHMI动作设计器。通过闭环反馈机制,实现无人参与的eHMI动作设计优化。
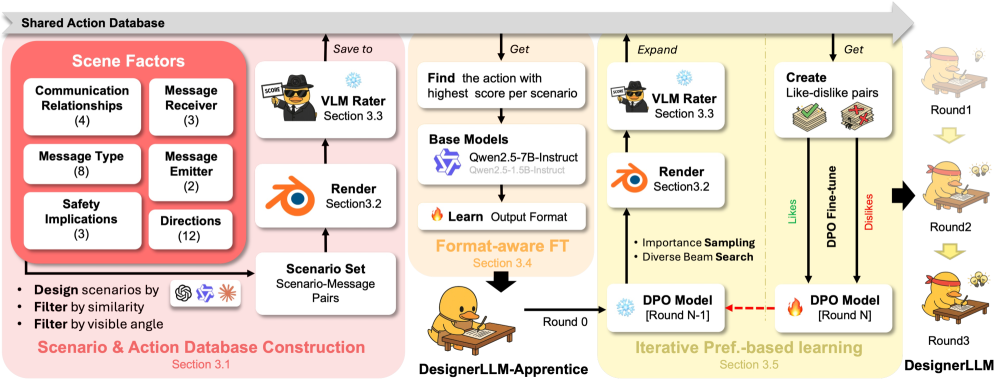
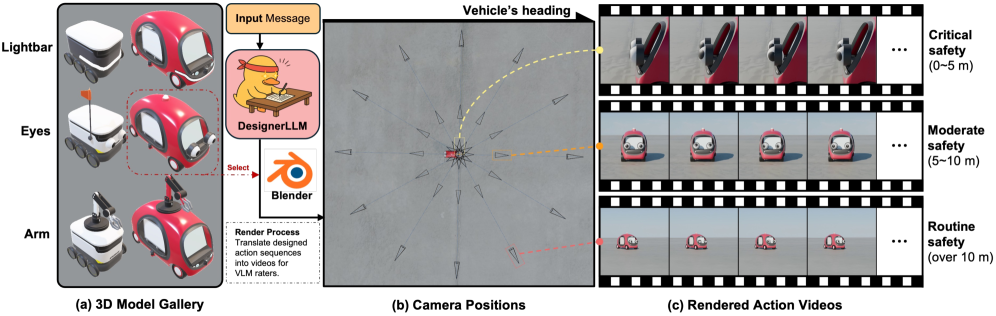
技术框架:See2Refine框架包含以下主要模块:1) LLM动作设计器:根据驾驶环境生成候选eHMI动作。2) VLM感知评估器:评估候选动作的感知适当性,生成反馈信号。3) 迭代优化器:根据VLM反馈,调整LLM动作设计器的输出,进行迭代优化。整个流程形成一个闭环,无需人工干预。
关键创新:See2Refine的关键创新在于使用VLM作为自动视觉反馈,替代了传统的人工标注反馈。这种方法降低了成本,提高了效率,并实现了eHMI动作设计的自动化优化。此外,该框架具有通用性,可以应用于不同的eHMI模式和LLM模型。
关键设计:VLM感知评估器的设计至关重要,论文中使用了预训练的VLM模型,并针对eHMI任务进行了微调。损失函数的设计需要考虑VLM评估结果与人类偏好之间的对齐。迭代优化器采用强化学习或梯度下降等方法,根据VLM反馈调整LLM的参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,See2Refine在三种eHMI模式(灯条、眼睛和手臂)下均优于prompt-only LLM设计器和手动指定的基线。在VLM-based指标和人类受试者评估中,See2Refine均取得了显著提升。此外,实验还验证了VLM评估与人类偏好高度一致,证明了See2Refine的有效性和鲁棒性。
🎯 应用场景
See2Refine可应用于自动驾驶车辆的eHMI设计,提升车辆与行人、骑行者等道路使用者的沟通效率和安全性。该研究成果有助于实现更加智能、安全和人性化的自动驾驶系统,并有望推广到其他需要人机交互的智能设备和机器人领域。
📄 摘要(原文)
Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.