Rethinking the Role of Entropy in Optimizing Tool-Use Behaviors for Large Language Model Agents
作者: Zeping Li, Hongru Wang, Yiwen Zhao, Guanhua Chen, Yixia Li, Keyang Chen, Yixin Cao, Guangnan Ye, Hongfeng Chai, Mengdi Wang, Zhenfei Yin
分类: cs.AI, cs.SE
发布日期: 2026-02-02
💡 一句话要点
利用熵减优化LLM智能体工具使用行为,提升效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 智能体 熵减 强化学习
📋 核心要点
- 现有LLM智能体工具使用中存在过多低质调用,导致延迟增加和性能下降,如何有效管理工具使用行为是核心问题。
- 论文提出利用熵减作为监督信号,设计稀疏结果奖励和密集过程奖励两种策略,分别提升效率和性能。
- 实验表明,稀疏奖励可减少72.07%的工具调用,密集奖励可提升22.27%的性能,验证了熵减的有效性。
📝 摘要(中文)
本文研究了基于大型语言模型(LLM)的工具使用智能体,这类智能体在数学推理和多跳问答等任务中表现出色。然而,在长轨迹中,智能体经常触发过多且低质量的工具调用,从而增加延迟并降低推理性能,使得管理工具使用行为充满挑战。本文通过基于熵的初步实验,观察到熵减与高质量工具调用之间存在很强的正相关性。基于此,我们提出使用熵减作为监督信号,并设计了两种奖励策略来满足优化工具使用行为的不同需求。稀疏结果奖励提供粗粒度的轨迹级指导以提高效率,而密集过程奖励提供细粒度的监督以提高性能。在不同领域的实验表明,两种奖励设计都改善了工具使用行为:前者与基线的平均水平相比,减少了72.07%的工具调用,而后者提高了22.27%的性能。这些结果表明,熵减是增强工具使用行为的关键机制,使智能体能够更适应实际应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)驱动的智能体在工具使用过程中,过度调用工具且调用质量不高的问题。现有方法往往难以有效控制工具的使用,导致推理效率低下,延迟增加,最终影响整体性能。痛点在于缺乏一种有效的机制来引导智能体进行高质量、高效率的工具调用。
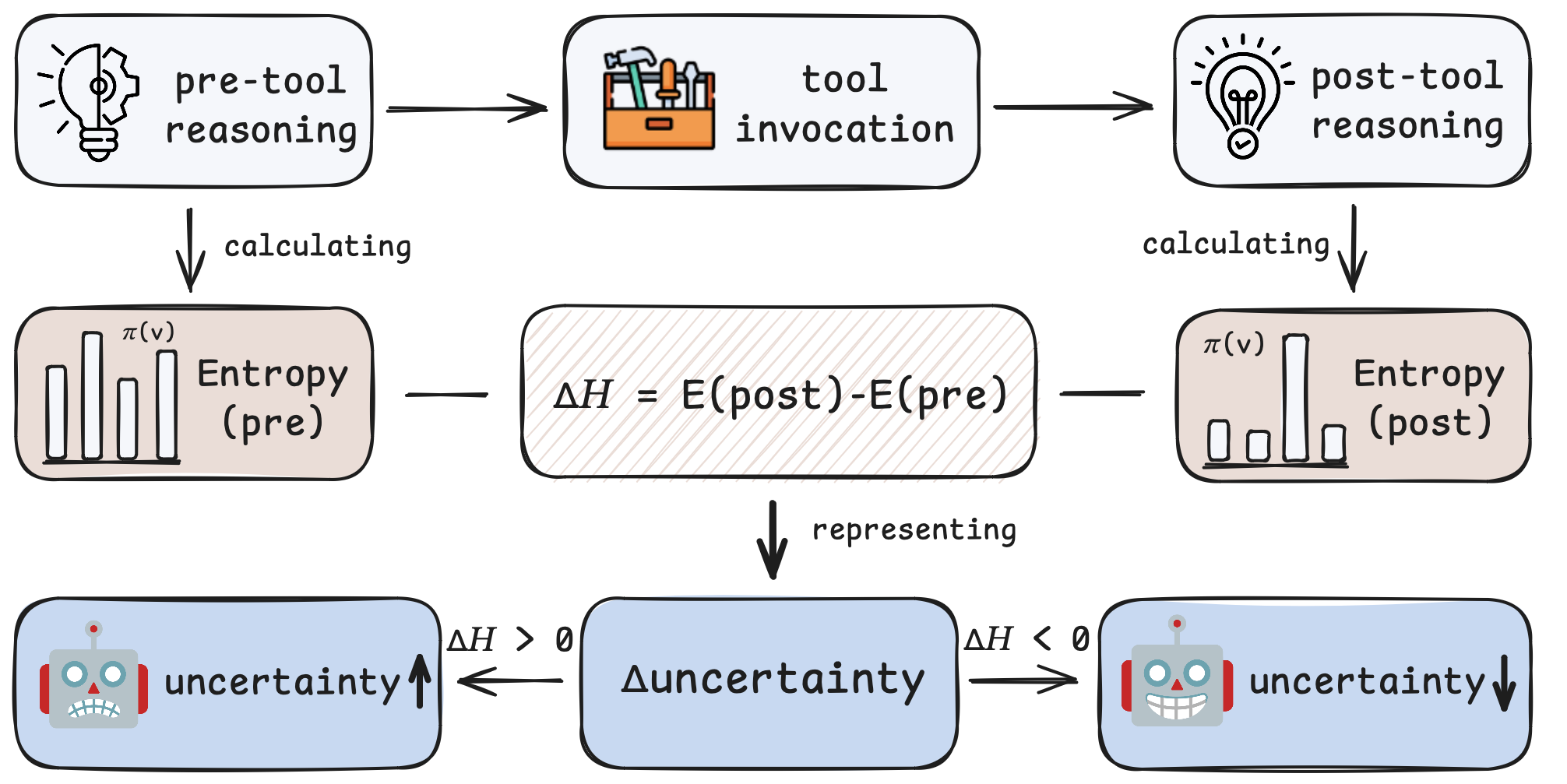
核心思路:论文的核心思路是利用熵减作为监督信号来优化智能体的工具使用行为。熵减反映了智能体决策的不确定性降低,意味着智能体更有把握地选择了合适的工具。通过奖励那些能够有效降低熵的工具调用行为,可以引导智能体学习更高效、更精准的工具使用策略。
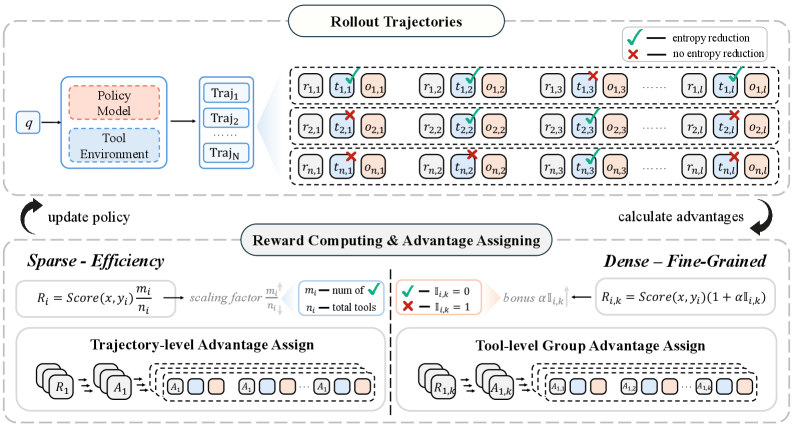
技术框架:整体框架包含以下几个主要阶段:1) 基于LLM的智能体与环境交互,生成工具调用轨迹;2) 计算每个时间步的熵值,并根据熵减情况生成奖励信号;3) 使用强化学习算法(如策略梯度)优化智能体的策略,使其倾向于选择能够带来更大熵减的工具调用;4) 通过稀疏结果奖励和密集过程奖励两种策略,分别从轨迹层面和步骤层面进行优化。
关键创新:论文的关键创新在于将熵减这一信息论概念引入到LLM智能体的工具使用优化中。与传统的基于结果的奖励方法不同,本文提出的方法关注工具调用过程中的信息增益,能够更有效地引导智能体学习高质量的工具使用策略。此外,两种奖励策略的设计也体现了对不同优化目标的关注,稀疏奖励侧重效率,密集奖励侧重性能。
关键设计:论文设计了两种奖励策略:1) 稀疏结果奖励:仅在轨迹结束时根据最终结果给予奖励,鼓励智能体以更少的工具调用次数完成任务;2) 密集过程奖励:在每个时间步根据熵减情况给予奖励,鼓励智能体选择能够带来更大信息增益的工具。具体实现中,熵的计算方式可能采用softmax输出的概率分布,奖励函数的设计需要仔细调整,以平衡探索和利用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于熵减的奖励策略能够显著改善LLM智能体的工具使用行为。具体而言,稀疏结果奖励策略能够减少72.07%的工具调用次数,从而提高效率;密集过程奖励策略能够提升22.27%的性能,从而提高准确性。这些结果表明,熵减是优化工具使用行为的有效手段。
🎯 应用场景
该研究成果可应用于各种需要LLM智能体进行工具使用的场景,例如智能客服、自动化报告生成、科学研究辅助等。通过优化工具使用行为,可以显著提升智能体的效率和准确性,降低运营成本,并为用户提供更优质的服务。未来,该方法有望推广到更复杂的任务和更广泛的智能体应用中。
📄 摘要(原文)
Tool-using agents based on Large Language Models (LLMs) excel in tasks such as mathematical reasoning and multi-hop question answering. However, in long trajectories, agents often trigger excessive and low-quality tool calls, increasing latency and degrading inference performance, making managing tool-use behavior challenging. In this work, we conduct entropy-based pilot experiments and observe a strong positive correlation between entropy reduction and high-quality tool calls. Building on this finding, we propose using entropy reduction as a supervisory signal and design two reward strategies to address the differing needs of optimizing tool-use behavior. Sparse outcome rewards provide coarse, trajectory-level guidance to improve efficiency, while dense process rewards offer fine-grained supervision to enhance performance. Experiments across diverse domains show that both reward designs improve tool-use behavior: the former reduces tool calls by 72.07% compared to the average of baselines, while the latter improves performance by 22.27%. These results position entropy reduction as a key mechanism for enhancing tool-use behavior, enabling agents to be more adaptive in real-world applications.