Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models
作者: Wei Liu, Peijie Yu, Michele Orini, Yali Du, Yulan He
分类: cs.AI, cs.CL, cs.DB, cs.LG
发布日期: 2026-02-02
备注: 14 pages, 7 tables, 8 figures
💡 一句话要点
提出DDR-Bench,评估LLM在开放数据分析中的自主探索能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自主探索 数据科学 研究智能 基准测试
📋 核心要点
- 现有Agentic LLM缺乏在开放数据分析中自主探索和发现关键信息的能力,限制了其在实际数据科学场景中的应用。
- 论文提出深度数据研究(DDR)任务,要求LLM自主从数据库中提取关键见解,模拟真实数据分析流程。
- 构建了大规模DDR-Bench基准,通过清单式评估,验证了现有模型在长期探索方面的挑战,并强调了内在策略的重要性。
📝 摘要(中文)
Agentic大型语言模型的能力不仅仅是正确回答问题,更需要自主设定目标并决定探索方向。我们将这种能力称为研究智能,以区别于仅完成分配任务的执行智能。数据科学提供了一个天然的试验场,因为实际分析从原始数据开始,而不是显式查询,但很少有基准关注它。为了解决这个问题,我们引入了深度数据研究(DDR),这是一个开放式任务,其中LLM自主地从数据库中提取关键见解,以及DDR-Bench,这是一个大规模的、基于清单的基准,可以实现可验证的评估。结果表明,虽然前沿模型显示出新兴的自主性,但长期探索仍然具有挑战性。我们的分析强调,有效的研究智能不仅取决于代理框架或简单的扩展,还取决于代理模型的内在策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在数据科学领域中,缺乏自主探索和发现数据洞见的能力。现有方法主要关注LLM的执行智能,即完成明确的任务,而忽略了其研究智能,即自主设定目标并探索数据。这导致LLM在处理真实世界的数据分析任务时,无法有效地从原始数据中提取有价值的信息。
核心思路:论文的核心思路是模拟真实数据科学家的工作流程,让LLM能够自主地从数据库中探索、分析并提取关键见解。通过构建一个开放式的任务(DDR),鼓励LLM设定自己的研究目标,并自主选择探索路径。这种方法旨在评估和提升LLM的研究智能,使其能够更好地适应真实世界的数据分析场景。
技术框架:DDR任务的整体框架包括以下几个主要阶段:1) 目标设定:LLM根据给定的数据库信息,自主设定研究目标。2) 数据探索:LLM根据设定的目标,自主选择和查询数据库中的相关数据。3) 分析推理:LLM对查询到的数据进行分析和推理,提取关键见解。4) 结果验证:使用DDR-Bench基准中的清单,对LLM提取的见解进行验证。整个流程强调LLM的自主性和探索能力。
关键创新:论文的关键创新在于提出了深度数据研究(DDR)任务和DDR-Bench基准。DDR任务是一个开放式的任务,旨在评估LLM在数据科学领域的自主探索能力。DDR-Bench基准提供了一个大规模的、基于清单的评估框架,可以对LLM提取的见解进行可验证的评估。与现有方法相比,DDR更侧重于评估LLM的研究智能,而不是执行智能。
关键设计:DDR-Bench基准的关键设计在于其基于清单的评估方法。清单包含一系列预定义的规则和标准,用于评估LLM提取的见解的质量和准确性。这些清单可以根据不同的研究目标进行定制,从而实现对LLM的全面评估。此外,DDR-Bench还提供了一个大规模的数据集,包含各种类型的数据库,可以用于训练和评估LLM。
🖼️ 关键图片

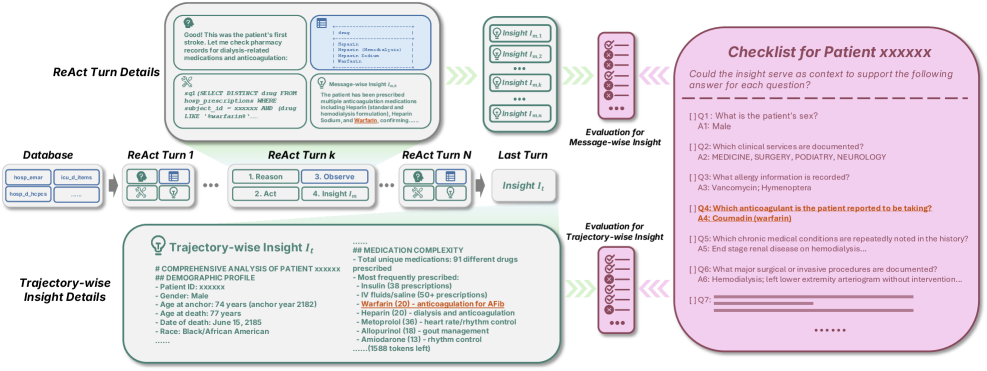
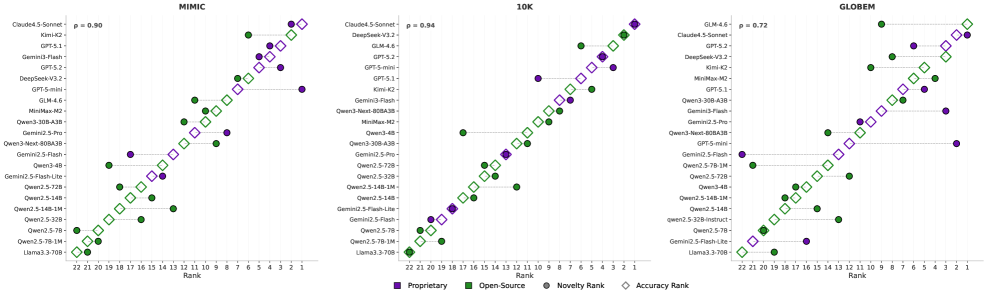
📊 实验亮点
实验结果表明,虽然现有前沿模型在DDR任务中显示出一定的自主探索能力,但在长期探索方面仍然面临挑战。分析发现,有效的研究智能不仅依赖于代理框架或模型规模,更取决于代理模型的内在策略。DDR-Bench的评估结果为未来研究提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于自动化数据分析、智能决策支持、科学发现等领域。通过提升LLM在数据探索和洞察提取方面的能力,可以帮助数据科学家更高效地完成数据分析任务,并为各行业提供更智能化的解决方案。未来,该研究有望推动LLM在数据科学领域的更广泛应用。
📄 摘要(原文)
The agency expected of Agentic Large Language Models goes beyond answering correctly, requiring autonomy to set goals and decide what to explore. We term this investigatory intelligence, distinguishing it from executional intelligence, which merely completes assigned tasks. Data Science provides a natural testbed, as real-world analysis starts from raw data rather than explicit queries, yet few benchmarks focus on it. To address this, we introduce Deep Data Research (DDR), an open-ended task where LLMs autonomously extract key insights from databases, and DDR-Bench, a large-scale, checklist-based benchmark that enables verifiable evaluation. Results show that while frontier models display emerging agency, long-horizon exploration remains challenging. Our analysis highlights that effective investigatory intelligence depends not only on agent scaffolding or merely scaling, but also on intrinsic strategies of agentic models.