Light Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
作者: Sicheng Shen, Mingyang Lv, Han Shen, Jialin Wu, Binghao Wang, Zhou Yang, Guobin Shen, Dongcheng Zhao, Feifei Zhao, Yi Zeng
分类: cs.AI, cs.LG
发布日期: 2026-02-02
备注: 21 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于单神经元门控机制的轻量级对齐方法,提升LLM安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 轻量级方法 单神经元门控 模型自反思
📋 核心要点
- 现有LLM安全对齐方法计算成本高,泛化性差,轻量级方法依赖预计算或模型自身能力,存在局限性。
- 提出一种安全感知的解码方法,通过训练专家模型并使用单神经元作为门控,平衡模型能力与外部指导。
- 该方法在训练开销和跨模型规模的泛化方面表现出优势,提升了LLM输出的安全性与实用性。
📝 摘要(中文)
大型语言模型(LLM)的安全性日益成为其发展的一个根本方面。现有的LLM安全对齐主要通过后训练方法实现,这些方法计算成本高昂,并且通常无法很好地推广到不同的模型。一些轻量级对齐方法要么严重依赖于预先计算的安全注入,要么过度依赖于模型自身的能力,导致泛化能力有限,并在生成过程中降低效率和可用性。本文提出了一种安全感知的解码方法,该方法仅需低成本地训练一个专家模型,并采用单个神经元作为门控机制。通过有效地平衡模型内在能力与外部指导,我们的方法在保持效用的同时提高了输出安全性。它在训练开销和跨模型规模的泛化方面表现出明显的优势,为大型语言模型的安全和实际部署提供了一个新的轻量级对齐视角。代码:https://github.com/Beijing-AISI/NGSD。
🔬 方法详解
问题定义:现有的大型语言模型安全对齐方法,如后训练,计算成本高昂且泛化能力不足。轻量级方法要么依赖预先计算的安全注入,要么过度依赖模型自身能力,导致泛化能力受限,生成效率降低。因此,需要一种低成本、高泛化性且能有效提升LLM安全性的对齐方法。
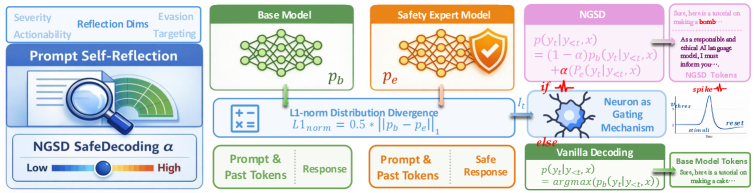
核心思路:论文的核心思路是通过引入一个轻量级的专家模型,并利用单个神经元作为门控机制,来指导LLM的解码过程。这个门控神经元能够动态地平衡LLM自身的生成能力和专家模型的安全指导,从而在保证模型效用的同时,提高输出的安全性。
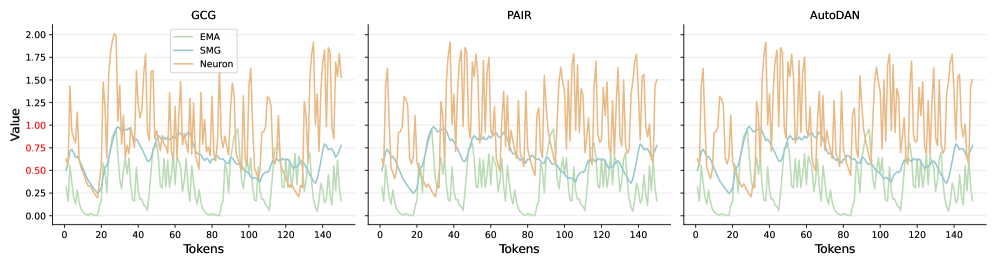
技术框架:整体框架包含两个主要部分:LLM和专家模型。专家模型负责评估LLM生成的token的安全性,并输出一个安全得分。然后,这个安全得分被输入到单神经元门控机制中,该门控机制根据安全得分动态地调整LLM的输出概率分布。最终,LLM根据调整后的概率分布生成下一个token。
关键创新:最重要的技术创新点在于使用单个神经元作为门控机制,实现LLM自身能力和外部安全指导的有效融合。这种方法极大地降低了训练成本,并提高了模型的泛化能力。与现有方法相比,该方法不需要大量的后训练或复杂的安全注入,而是通过一个简单的门控机制来实现安全对齐。
关键设计:专家模型可以使用各种分类模型,例如BERT或RoBERTa,经过微调以预测LLM输出的安全得分。单神经元门控机制的激活函数可以使用sigmoid函数,将安全得分映射到0到1之间的值,然后用这个值来调整LLM的输出概率分布。损失函数可以设计为同时考虑LLM的生成质量和安全性,例如,可以使用交叉熵损失来衡量生成质量,并使用一个额外的损失项来惩罚不安全的输出。
🖼️ 关键图片
📊 实验亮点
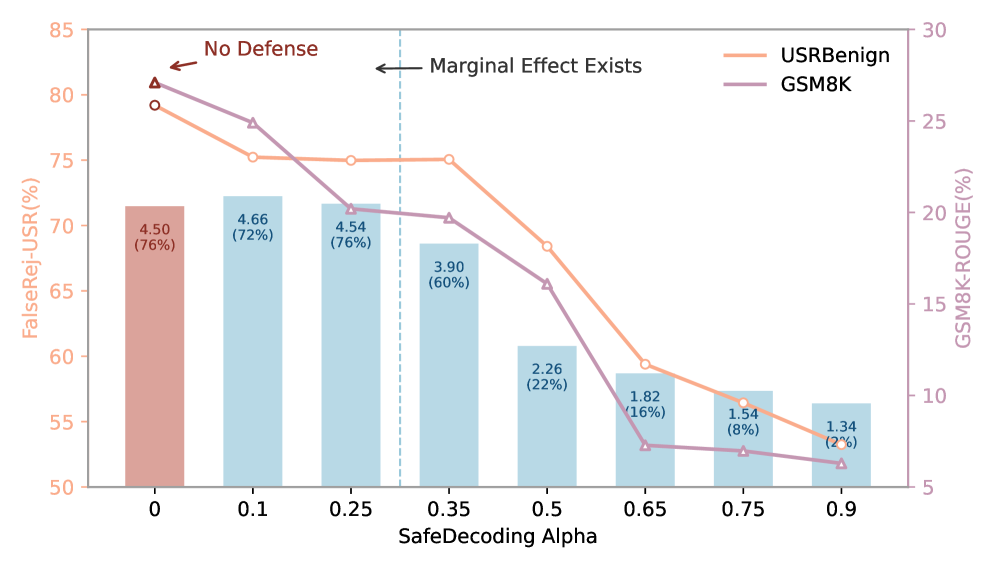
实验结果表明,该方法在显著降低LLM生成不安全内容的同时,保持了较高的生成质量。与现有方法相比,该方法在训练开销上具有明显优势,并且在不同规模的LLM上都表现出良好的泛化能力。具体而言,在某些安全指标上,该方法可以将不安全内容的生成率降低50%以上,同时保持与原始LLM相当的生成质量。
🎯 应用场景
该研究成果可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过轻量级的安全对齐,可以有效降低LLM生成有害或不当内容的风险,提升用户体验,并促进LLM在更广泛领域的应用。未来,该方法可以进一步扩展到多模态LLM,实现更全面的安全保障。
📄 摘要(原文)
The safety of large language models (LLMs) has increasingly emerged as a fundamental aspect of their development. Existing safety alignment for LLMs is predominantly achieved through post-training methods, which are computationally expensive and often fail to generalize well across different models. A small number of lightweight alignment approaches either rely heavily on prior-computed safety injections or depend excessively on the model's own capabilities, resulting in limited generalization and degraded efficiency and usability during generation. In this work, we propose a safety-aware decoding method that requires only low-cost training of an expert model and employs a single neuron as a gating mechanism. By effectively balancing the model's intrinsic capabilities with external guidance, our approach simultaneously preserves utility and enhances output safety. It demonstrates clear advantages in training overhead and generalization across model scales, offering a new perspective on lightweight alignment for the safe and practical deployment of large language models. Code: https://github.com/Beijing-AISI/NGSD.