Do I Really Know? Learning Factual Self-Verification for Hallucination Reduction
作者: Enes Altinisik, Masoomali Fatehkia, Fatih Deniz, Nadir Durrani, Majd Hawasly, Mohammad Raza, Husrev Taha Sencar
分类: cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出VeriFY框架,通过自验证学习减少大语言模型的事实性幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 事实性幻觉 自验证 一致性学习 损失掩蔽
📋 核心要点
- 大语言模型的事实性幻觉问题严重,现有方法要么依赖外部验证,要么直接拒绝回答,效果不佳。
- VeriFY框架通过训练模型进行一致性自验证,使其能够判断自身答案的事实不确定性并选择拒绝回答。
- 实验表明,VeriFY能显著降低事实性幻觉率,最高达53.3%,且对召回率的影响较小,并具有泛化能力。
📝 摘要(中文)
事实性幻觉是大语言模型(LLMs)面临的核心挑战。现有的缓解方法主要依赖于外部事后验证或直接将不确定性映射到微调期间的拒绝回答,但通常导致过于保守的行为。我们提出了VeriFY,这是一个训练时框架,它通过基于一致性的自验证来教导LLMs推理事实不确定性。VeriFY通过结构化的验证轨迹来增强训练,引导模型生成初始答案,生成并回答探测性验证查询,发布一致性判断,然后决定是否回答或拒绝回答。为了解决在增强轨迹上训练时强化幻觉内容的风险,我们引入了一种阶段级损失掩蔽方法,该方法将幻觉答案阶段从训练目标中排除,同时保留对验证行为的监督。在多个模型系列和规模上,VeriFY将事实性幻觉率降低了9.7%到53.3%,而召回率仅略有降低(0.4%到5.7%),并且在单个源上训练时可以跨数据集泛化。源代码、训练数据和训练后的模型检查点将在接受后发布。
🔬 方法详解
问题定义:大语言模型在生成文本时,经常出现与事实不符的“幻觉”现象。现有方法,如事后验证或直接拒绝回答,要么效率低,要么过于保守,无法有效解决幻觉问题,且影响模型的实用性。因此,如何让模型自身具备识别和避免生成幻觉内容的能力是关键。
核心思路:VeriFY的核心在于训练模型进行“自验证”。模型首先生成一个初始答案,然后生成一个用于验证该答案的探测性查询,并根据查询结果判断初始答案是否一致。如果判断不一致,则选择拒绝回答,从而避免生成幻觉内容。这种方法模拟了人类在回答问题时的自我检查过程。
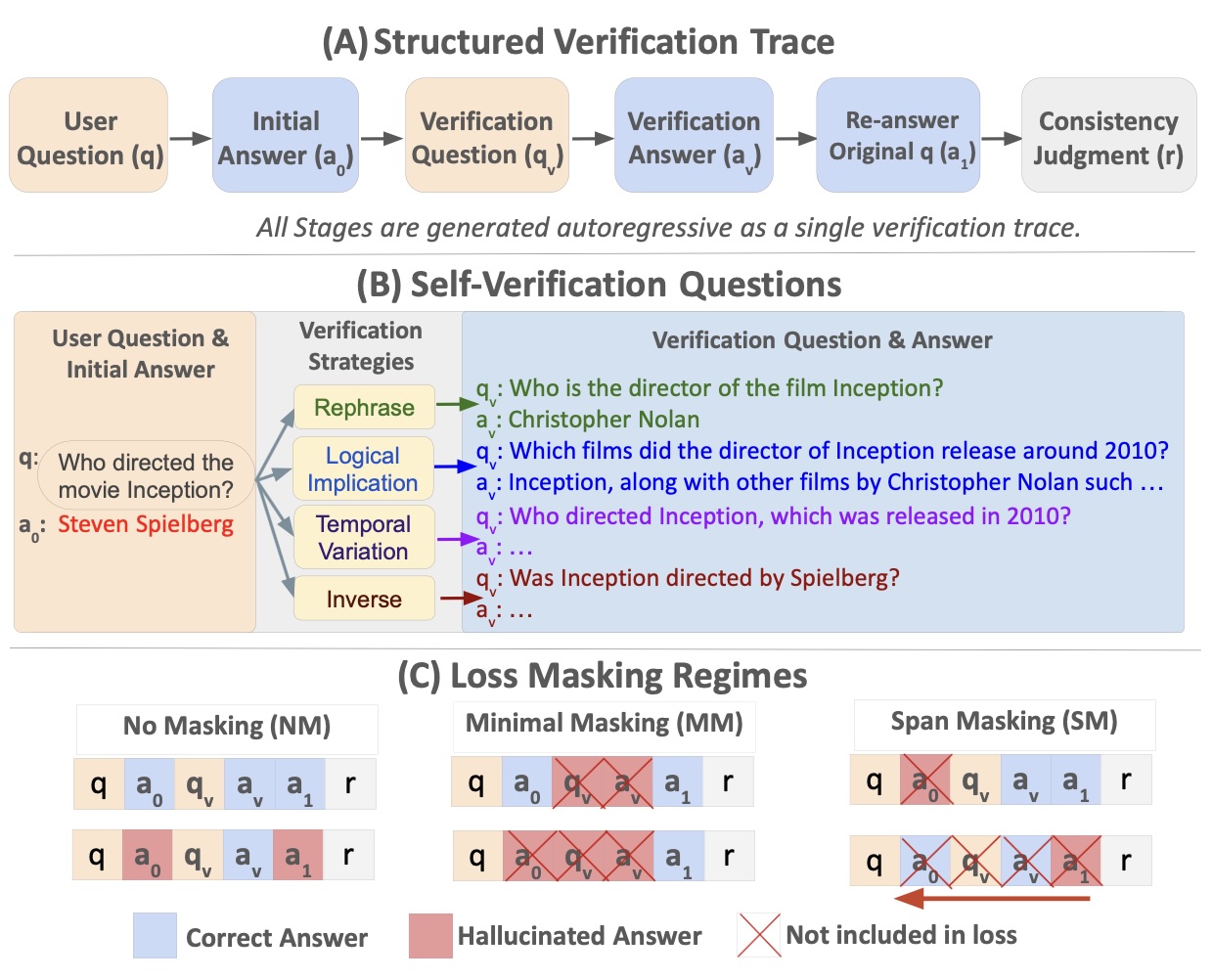
技术框架:VeriFY框架包含以下几个主要阶段:1) 初始答案生成:模型根据输入问题生成一个初始答案。2) 验证查询生成:模型根据初始答案生成一个探测性的验证查询,用于验证初始答案的真实性。3) 验证查询回答:模型回答生成的验证查询。4) 一致性判断:模型比较初始答案和验证查询的答案,判断两者是否一致。5) 最终决策:根据一致性判断结果,模型决定是输出初始答案还是选择拒绝回答。
关键创新:VeriFY的关键创新在于训练模型进行一致性自验证,而不是依赖外部信息或直接拒绝回答。此外,为了避免在训练过程中强化幻觉内容,该方法还引入了阶段级损失掩蔽,即在训练过程中忽略幻觉答案阶段的损失,只保留对验证行为的监督。
关键设计:VeriFY使用结构化的验证轨迹来增强训练数据,这些轨迹包含初始答案、验证查询、验证查询的答案以及一致性判断。在训练过程中,使用阶段级损失掩蔽来避免强化幻觉内容。具体的损失函数设计和网络结构选择取决于具体的模型架构,但核心思想是鼓励模型生成一致的答案,并在不确定时选择拒绝回答。
🖼️ 关键图片

📊 实验亮点
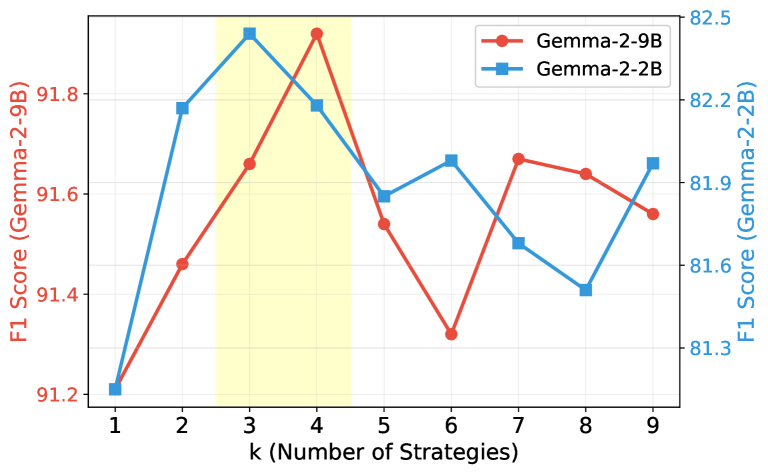
实验结果表明,VeriFY框架在多个模型系列和规模上均能有效降低事实性幻觉率,最高可降低53.3%,同时对召回率的影响较小(仅降低0.4%到5.7%)。此外,该方法在单个源上训练后,可以跨数据集泛化,表明其具有良好的泛化能力。
🎯 应用场景
VeriFY框架可应用于各种需要生成事实性文本的场景,例如问答系统、信息检索、内容生成等。通过降低大语言模型的事实性幻觉,可以提高生成文本的可靠性和可信度,从而增强用户体验,并减少错误信息的传播。该研究对于构建更安全、更可靠的人工智能系统具有重要意义。
📄 摘要(原文)
Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.