Small Generalizable Prompt Predictive Models Can Steer Efficient RL Post-Training of Large Reasoning Models
作者: Yun Qu, Qi Wang, Yixiu Mao, Heming Zou, Yuhang Jiang, Weijie Liu, Clive Bai, Kai Yang, Yangkun Chen, Saiyong Yang, Xiangyang Ji
分类: cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出GPS,通过小模型预测提示词难度,高效指导大模型强化学习后训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 提示词选择 贝叶斯推断 模型泛化
📋 核心要点
- 现有强化学习方法训练大模型推理能力时,rollout成本高昂,在线提示词选择方法缺乏跨提示词的泛化能力。
- GPS方法利用轻量级生成模型,基于共享优化历史进行贝叶斯推断,预测提示词难度,并优先选择信息量大的提示词。
- 实验表明,GPS在训练效率、最终性能和测试时效率方面均优于现有方法,证明了其有效性。
📝 摘要(中文)
强化学习可以提升大型语言模型的推理能力,但由于需要大量的rollout优化,计算成本通常很高。在线提示词选择提供了一个可行的解决方案,通过优先选择信息量大的提示词来提高训练效率。然而,目前的方法要么依赖于代价高昂的精确评估,要么构建特定于提示词的预测模型,缺乏跨提示词的泛化能力。本研究提出了通用预测提示词选择(GPS),它使用在共享优化历史记录上训练的轻量级生成模型,对提示词难度进行贝叶斯推断。中间难度优先排序和历史锚定的多样性被纳入批次获取原则,以选择信息量大的提示词批次。小型预测模型还在测试时进行泛化,以实现高效的计算分配。在不同的推理基准上的实验表明,与优秀的基线方法相比,GPS在训练效率、最终性能和测试时效率方面都有显著提高。
🔬 方法详解
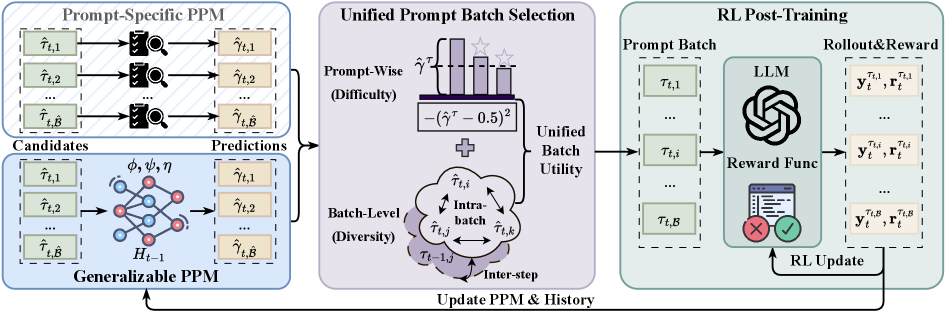
问题定义:现有方法在利用强化学习提升大型语言模型推理能力时,面临计算成本高昂的问题,尤其是在rollout阶段。在线提示词选择旨在通过优先选择信息量大的提示词来提高训练效率,但现有方法存在两个主要痛点:一是依赖于代价高昂的精确评估来判断提示词的信息量;二是构建特定于提示词的预测模型,这些模型缺乏跨提示词的泛化能力,导致需要为每个提示词单独训练模型,进一步增加了计算负担。
核心思路:GPS的核心思路是利用一个轻量级的、可泛化的预测模型来估计提示词的难度,从而指导强化学习过程。该模型基于共享的优化历史进行训练,能够学习到不同提示词之间的共性,从而实现跨提示词的泛化。通过贝叶斯推断,GPS能够对提示词的难度进行建模,并优先选择难度适中的提示词,因为这些提示词通常包含更多有价值的信息。此外,GPS还考虑了提示词的多样性,避免过度集中于某一类提示词,从而提高模型的泛化能力。
技术框架:GPS的整体框架包括以下几个主要模块:1) 轻量级生成模型:用于预测提示词的难度,该模型基于共享的优化历史进行训练。2) 贝叶斯推断:利用贝叶斯推断对提示词的难度进行建模,并估计其不确定性。3) 批次获取原则:基于提示词的难度和不确定性,选择信息量大的提示词批次进行训练。该原则结合了中间难度优先排序和历史锚定的多样性。4) 强化学习优化:利用选择的提示词批次,对大型语言模型进行强化学习优化。
关键创新:GPS的关键创新在于其轻量级、可泛化的预测模型。与现有方法相比,该模型不需要为每个提示词单独训练,而是能够基于共享的优化历史学习到不同提示词之间的共性,从而实现跨提示词的泛化。此外,GPS还引入了贝叶斯推断来对提示词的难度进行建模,并结合中间难度优先排序和历史锚定的多样性,从而更有效地选择信息量大的提示词。
关键设计:GPS的关键设计包括:1) 轻量级生成模型的结构:具体模型结构未知,但强调了其轻量性,以降低计算成本。2) 贝叶斯推断的先验分布和似然函数:具体形式未知,但需要根据具体的任务和数据进行选择。3) 中间难度优先排序的策略:需要定义一个合适的难度度量,并根据该度量对提示词进行排序。4) 历史锚定的多样性策略:需要定义一个合适的相似度度量,并根据该度量选择具有多样性的提示词。
🖼️ 关键图片

📊 实验亮点
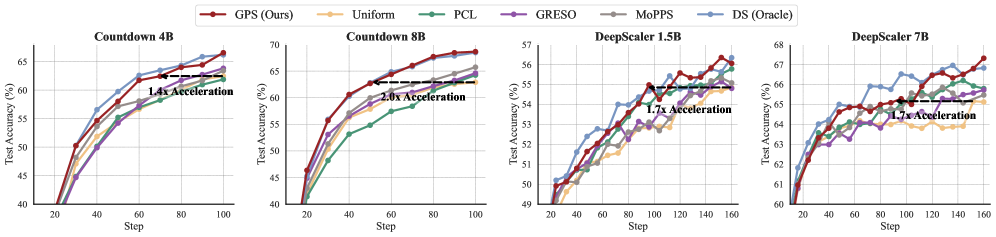
论文实验结果表明,GPS在多个推理基准测试中均取得了显著的性能提升。与现有最佳基线方法相比,GPS在训练效率、最终性能和测试时效率方面均有明显优势。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了GPS的有效性和优越性。
🎯 应用场景
GPS方法具有广泛的应用前景,可以应用于各种需要利用强化学习提升大型语言模型推理能力的场景,例如问答系统、对话系统、代码生成等。该方法可以显著提高训练效率,降低计算成本,并提升模型的最终性能。此外,GPS的轻量级预测模型还可以在测试时进行泛化,从而实现高效的计算分配。
📄 摘要(原文)
Reinforcement learning enhances the reasoning capabilities of large language models but often involves high computational costs due to rollout-intensive optimization. Online prompt selection presents a plausible solution by prioritizing informative prompts to improve training efficiency. However, current methods either depend on costly, exact evaluations or construct prompt-specific predictive models lacking generalization across prompts. This study introduces Generalizable Predictive Prompt Selection (GPS), which performs Bayesian inference towards prompt difficulty using a lightweight generative model trained on the shared optimization history. Intermediate-difficulty prioritization and history-anchored diversity are incorporated into the batch acquisition principle to select informative prompt batches. The small predictive model also generalizes at test-time for efficient computational allocation. Experiments across varied reasoning benchmarks indicate GPS's substantial improvements in training efficiency, final performance, and test-time efficiency over superior baseline methods.