Geometric Analysis of Token Selection in Multi-Head Attention
作者: Timur Mudarisov, Mikhal Burtsev, Tatiana Petrova, Radu State
分类: cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出多头注意力几何分析框架,揭示Token选择机制与头部的专门化行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多头注意力 几何分析 Token选择 可解释性 大型语言模型 头部专门化 Value-State空间 非渐近界
📋 核心要点
- 现有方法缺乏对LLM中多头注意力机制token选择的深入理解,难以解释其行为。
- 论文提出几何分析框架,通过定义几何指标量化token选择的可分离性,揭示其内在机制。
- 实验验证了理论预测,发现头部存在专门化行为,为注意力机制的优化提供指导。
📝 摘要(中文)
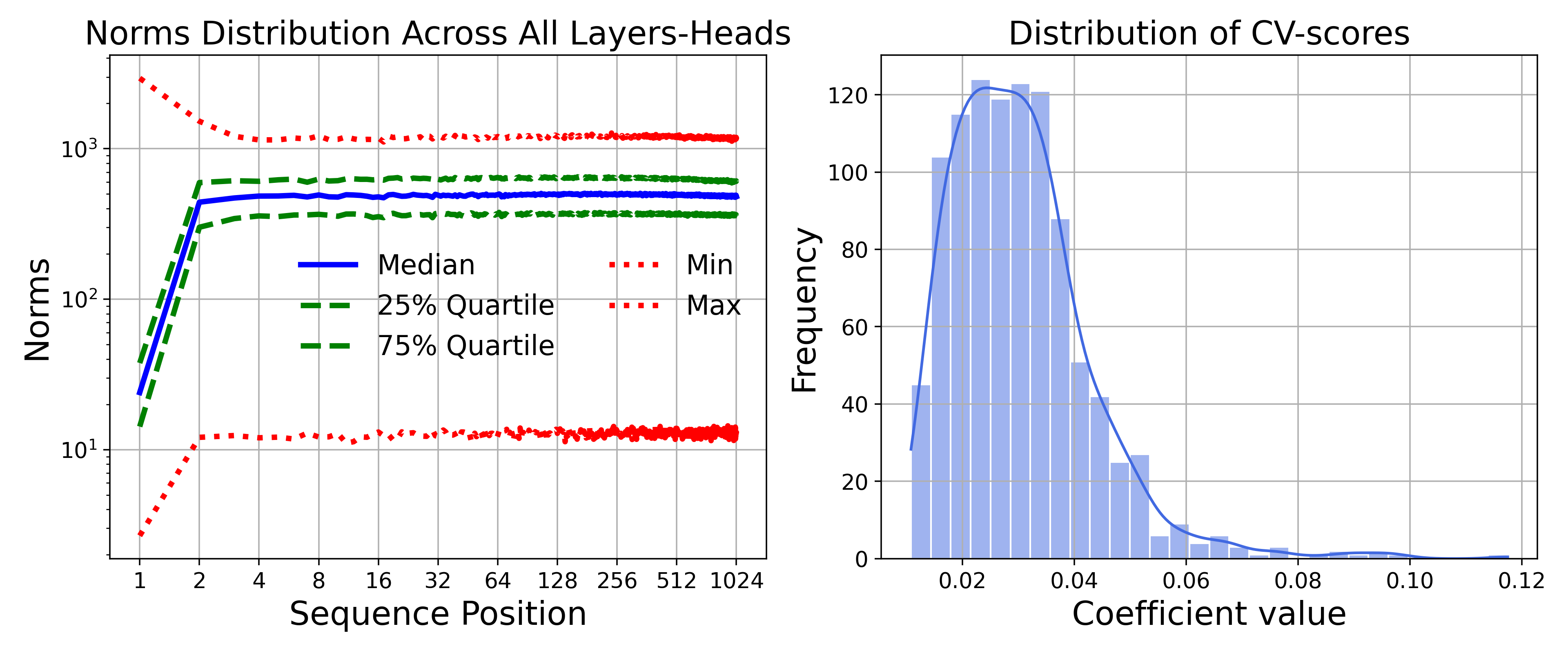
本文提出了一个用于分析大型语言模型(LLMs)中多头注意力的几何框架。在不改变注意力机制的前提下,我们将标准注意力视为一种top-N选择,并在value-state空间中直接研究其行为。我们定义了几何指标——精确率(Precision)、召回率(Recall)和F-score——来量化被选择和未被选择的token之间的可分离性,并在经验驱动的假设(具有压缩sink token的稳定value范数、指数相似性衰减和分段注意力权重分布)下,推导出具有维度和margin显式依赖性的非渐近界。理论预测了一个最强非平凡可分离性的小N操作区域,并阐明了序列长度和sink相似性如何影响这些指标。在LLaMA-2-7B、Gemma-7B和Mistral-7B上的实验测量结果与理论包络密切吻合:top-N选择提高了可分离性,sink相似性与召回率相关。我们还发现,在LLaMA-2-7B中,头部专门化为三种模式——检索器(Retriever)、混合器(Mixer)、重置器(Reset)——具有不同的几何特征。总而言之,注意力表现为一个结构化的几何分类器,具有可测量的token选择标准,为头部级别的可解释性提供了可能,并为LLM中注意力的几何感知稀疏化和设计提供了信息。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中多头注意力机制的token选择问题。现有方法通常将注意力视为黑盒,缺乏对其内部工作机制的理解,特别是如何选择重要的token以及不同head之间的差异。这限制了模型的可解释性和优化潜力。
核心思路:论文的核心思路是将多头注意力机制视为一种top-N选择过程,并在value-state空间中对其进行几何分析。通过定义几何指标(Precision, Recall, F-score)来量化被选择和未被选择的token之间的可分离性,从而揭示注意力机制的token选择行为。这种几何视角能够提供对注意力机制更直观和可解释的理解。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 将标准注意力机制视为top-N选择;2) 在value-state空间中定义几何指标(Precision, Recall, F-score)来量化token选择的可分离性;3) 在经验驱动的假设下,推导出几何指标的非渐近界,并分析其与序列长度、sink相似性等因素的关系;4) 通过实验验证理论预测,并分析不同head的专门化行为。
关键创新:论文的关键创新在于提出了一个用于分析多头注意力机制的几何框架。该框架通过定义几何指标,将注意力机制的token选择行为与value-state空间的几何性质联系起来,从而提供了一种新的理解和分析注意力机制的视角。此外,论文还发现了不同head的专门化行为,为注意力机制的优化提供了新的思路。
关键设计:论文的关键设计包括:1) 定义了Precision, Recall, F-score等几何指标来量化token选择的可分离性;2) 提出了经验驱动的假设,包括具有压缩sink token的稳定value范数、指数相似性衰减和分段注意力权重分布;3) 推导出了几何指标的非渐近界,并分析了其与序列长度、sink相似性等因素的关系;4) 通过实验验证了理论预测,并分析了不同head的专门化行为。
🖼️ 关键图片


📊 实验亮点
实验结果表明,理论预测与LLaMA-2-7B、Gemma-7B和Mistral-7B的实际测量结果高度吻合。Top-N选择能够提高token的可分离性,sink相似性与召回率密切相关。此外,研究发现LLaMA-2-7B中的头部专门化为检索器、混合器和重置器三种模式,具有不同的几何特征。
🎯 应用场景
该研究成果可应用于大型语言模型的优化和改进,例如通过几何感知的稀疏化方法来减少计算量,或者设计更有效的注意力机制。此外,该研究提供的头部级别可解释性,有助于理解模型的行为,并为模型的调试和改进提供指导。该方法还可能推广到其他Transformer模型和相关领域。
📄 摘要(原文)
We present a geometric framework for analysing multi-head attention in large language models (LLMs). Without altering the mechanism, we view standard attention through a top-N selection lens and study its behaviour directly in value-state space. We define geometric metrics - Precision, Recall, and F-score - to quantify separability between selected and non-selected tokens, and derive non-asymptotic bounds with explicit dependence on dimension and margin under empirically motivated assumptions (stable value norms with a compressed sink token, exponential similarity decay, and piecewise attention weight profiles). The theory predicts a small-N operating regime of strongest non-trivial separability and clarifies how sequence length and sink similarity shape the metrics. Empirically, across LLaMA-2-7B, Gemma-7B, and Mistral-7B, measurements closely track the theoretical envelopes: top-N selection sharpens separability, sink similarity correlates with Recall. We also found that in LLaMA-2-7B heads specialize into three regimes - Retriever, Mixer, Reset - with distinct geometric signatures. Overall, attention behaves as a structured geometric classifier with measurable criteria for token selection, offering head level interpretability and informing geometry-aware sparsification and design of attention in LLMs.