Entropy-Guided Data-Efficient Training for Multimodal Reasoning Reward Models
作者: Shidong Yang, Tongwen Huang, Hao Wen, Yong Wang, Li Chen, Xiangxiang Chu
分类: cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出熵引导训练(EGT)方法,提升多模态推理奖励模型的训练效率与性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 奖励模型 熵引导训练 数据清洗 课程学习 大型语言模型 偏好对齐
📋 核心要点
- 现有方法在训练多模态奖励模型时,易受偏好数据集中噪声干扰,导致模型性能下降。
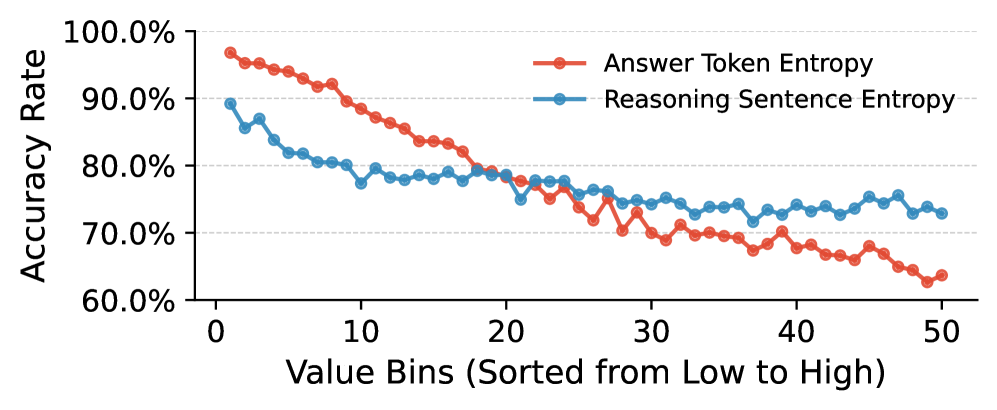
- 论文提出熵引导训练(EGT)方法,利用响应熵作为样本难度和噪声的代理指标,指导数据选择和训练过程。
- 实验结果表明,EGT方法在多个基准测试中显著优于现有最先进的多模态奖励模型,提升了模型性能。
📝 摘要(中文)
多模态奖励模型对于将多模态大型语言模型与人类偏好对齐至关重要。最近的研究已将推理能力融入这些模型,取得了可喜的成果。然而,训练这些模型面临两个关键挑战:(1)偏好数据集中固有的噪声会降低模型性能,(2)传统的训练方法效率低下,忽略了样本难度的差异。本文发现响应熵与准确率之间存在很强的相关性,表明熵可以作为注释噪声和样本难度的可靠且无监督的代理。基于这一洞察,我们提出了一种新颖的熵引导训练(EGT)方法,用于多模态推理奖励模型,该方法结合了两种策略:(1)熵引导的数据管理,以减轻不可靠样本的影响,(2)一种熵引导的训练策略,逐步引入更复杂的示例。在三个基准测试中进行的大量实验表明,经过EGT训练的模型始终优于最先进的多模态奖励模型。
🔬 方法详解
问题定义:论文旨在解决多模态推理奖励模型训练过程中,由于偏好数据集噪声和传统训练方法效率低下导致的模型性能下降问题。现有方法未能有效区分样本难度和数据质量,导致模型训练不稳定且效率不高。
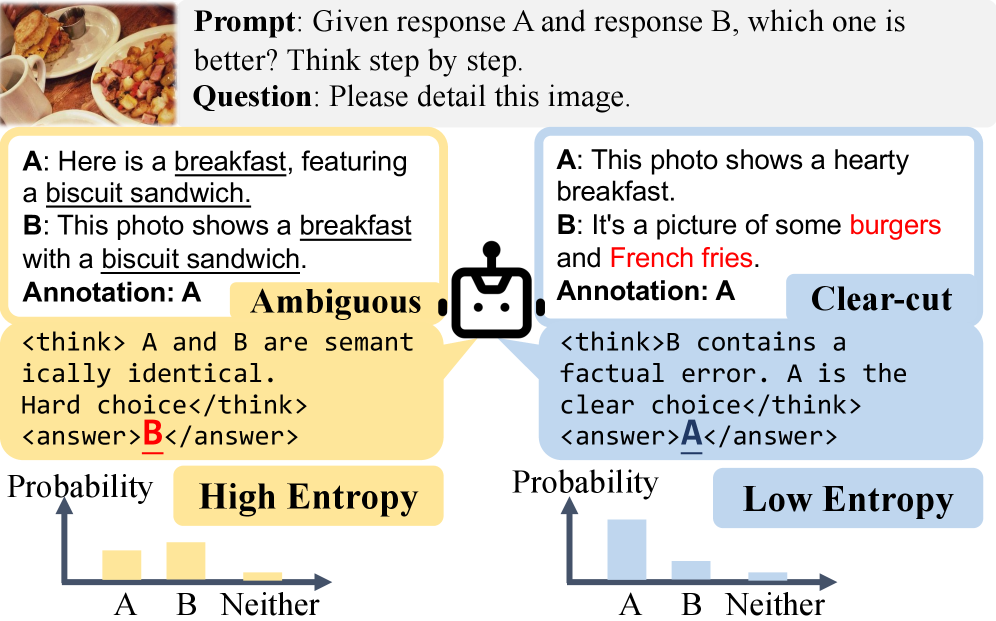
核心思路:论文的核心思路是利用模型输出的响应熵作为样本难度和数据质量的无监督代理指标。高熵通常意味着模型对该样本的不确定性较高,可能源于样本本身难度较大或标注存在噪声。通过分析熵值,可以指导数据选择和训练策略,从而提高模型训练的效率和鲁棒性。
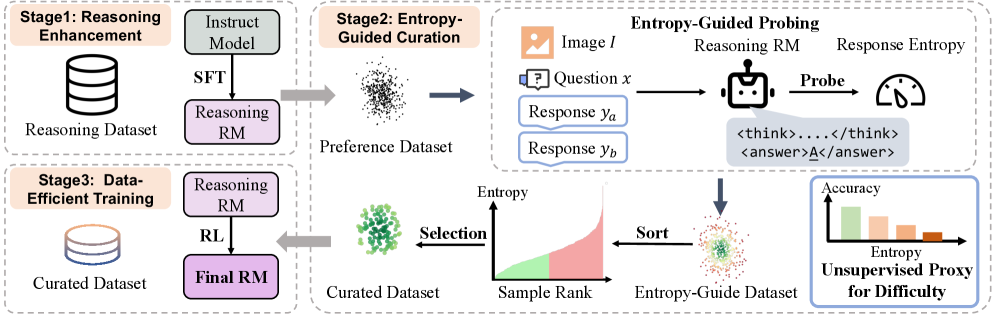
技术框架:EGT方法包含两个主要阶段:熵引导的数据管理和熵引导的训练策略。首先,利用熵值对训练数据进行筛选,去除高熵的不可靠样本,从而减少噪声的影响。然后,在训练过程中,根据样本的熵值逐步引入更复杂的示例,类似于课程学习的思想,使模型能够从易到难地学习。
关键创新:该方法最关键的创新在于将响应熵作为样本难度和数据质量的无监督代理指标,并将其应用于多模态奖励模型的训练过程中。与现有方法相比,EGT无需额外的标注信息,即可有效地识别和处理噪声数据,并根据样本难度调整训练策略。
关键设计:在数据管理阶段,设定一个熵阈值,高于该阈值的样本将被过滤掉。在训练阶段,采用课程学习策略,根据样本熵值从小到大进行排序,并逐步增加训练样本的难度。损失函数采用标准的pairwise ranking loss,用于优化奖励模型,使其能够更好地区分人类偏好的排序。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EGT方法在三个基准测试中均优于现有最先进的多模态奖励模型。具体而言,EGT在某些指标上实现了显著的性能提升,表明其能够有效地减轻噪声影响并提高训练效率。这些结果验证了响应熵作为样本难度和数据质量代理指标的有效性,并证明了EGT方法在多模态奖励模型训练中的优越性。
🎯 应用场景
该研究成果可广泛应用于多模态大型语言模型的对齐训练,尤其是在需要高质量奖励模型的场景下。例如,可以用于训练更符合人类偏好的多模态对话系统、图像生成模型和视频理解模型,从而提升用户体验和模型实用性。此外,该方法也可以推广到其他需要数据清洗和课程学习的机器学习任务中。
📄 摘要(原文)
Multimodal reward models are crucial for aligning multimodal large language models with human preferences. Recent works have incorporated reasoning capabilities into these models, achieving promising results. However, training these models suffers from two critical challenges: (1) the inherent noise in preference datasets, which degrades model performance, and (2) the inefficiency of conventional training methods, which ignore the differences in sample difficulty. In this paper, we identify a strong correlation between response entropy and accuracy, indicating that entropy can serve as a reliable and unsupervised proxy for annotation noise and sample difficulty. Based on this insight, we propose a novel Entropy-Guided Training (EGT) approach for multimodal reasoning reward models, which combines two strategies: (1) entropy-guided data curation to mitigate the impact of unreliable samples, and (2) an entropy-guided training strategy that progressively introduces more complex examples. Extensive experiments across three benchmarks show that the EGT-trained model consistently outperforms state-of-the-art multimodal reward models.