ProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
作者: Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, Jun Wang
分类: cs.AI
发布日期: 2026-02-02
备注: 20 Pages, 6 Figures, 4 Tables
💡 一句话要点
ProcMEM:通过非参数PPO从经验中学习可复用程序记忆,用于LLM智能体
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 程序记忆 强化学习 LLM智能体 非参数PPO 技能复用
📋 核心要点
- 现有LLM智能体在重复决策场景中缺乏经验复用,导致计算冗余和执行不稳定。
- ProcMEM通过Skill-MDP将经验转化为可执行技能,并使用非参数PPO进行技能验证和优化。
- 实验表明ProcMEM在多个场景下实现了更高的复用率和性能提升,同时压缩了记忆规模。
📝 摘要(中文)
基于LLM的智能体在序列决策中表现出色,但通常依赖于即时推理,即使在重复出现的情况下也会重新推导解决方案。这种经验复用不足导致计算冗余和执行不稳定。为了弥补这一差距,我们提出了ProcMEM,该框架使智能体能够自主地从交互经验中学习程序记忆,而无需参数更新。通过形式化Skill-MDP,ProcMEM将被动的片段叙事转化为可执行的技能,这些技能由激活、执行和终止条件定义,以确保可执行性。为了在不降低能力的情况下实现可靠的复用性,我们引入了非参数PPO,它利用语义梯度进行高质量候选生成,并利用PPO门进行稳健的技能验证。通过基于分数的维护,ProcMEM保持紧凑、高质量的程序记忆。跨领域、跨任务和跨智能体场景的实验结果表明,ProcMEM实现了卓越的复用率和显著的性能提升,并实现了极高的内存压缩。可视化的演化轨迹和技能分布进一步揭示了ProcMEM如何透明地积累、提炼和复用程序知识,以促进长期自主性。
🔬 方法详解
问题定义:LLM驱动的智能体在序列决策任务中表现出色,但它们通常依赖于即时推理,即使在重复出现的场景中也会重新推导解决方案。这种经验复用不足导致计算冗余和执行不稳定,限制了智能体的效率和长期自主性。现有方法要么依赖于参数更新,要么缺乏有效的技能验证机制,难以保证技能的可复用性和可靠性。
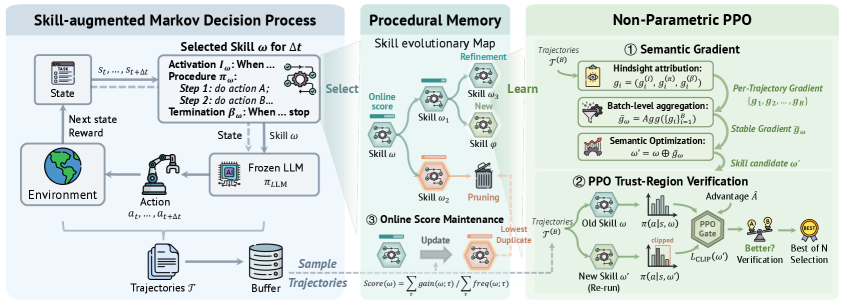
核心思路:ProcMEM的核心思路是从智能体的交互经验中学习可复用的程序记忆,而无需参数更新。它将经验转化为可执行的技能,并通过强化学习方法进行优化和验证,确保技能的可靠性和可复用性。通过维护一个紧凑、高质量的程序记忆库,ProcMEM使智能体能够快速地复用已有的经验,从而提高决策效率和稳定性。
技术框架:ProcMEM框架主要包含以下几个模块:1) Skill-MDP形式化:将智能体的交互经验转化为Skill-MDP,其中状态表示环境状态,动作表示技能,奖励表示技能的执行效果。2) 非参数PPO:利用语义梯度生成高质量的技能候选,并使用PPO门进行技能验证和优化。3) 基于分数的维护:维护一个紧凑、高质量的程序记忆库,通过分数评估技能的质量和重要性,并定期更新记忆库。
关键创新:ProcMEM的关键创新在于:1) 提出了一种新的程序记忆学习框架,该框架能够自主地从交互经验中学习可复用的技能,而无需参数更新。2) 引入了非参数PPO,该方法利用语义梯度生成高质量的技能候选,并使用PPO门进行技能验证和优化。3) 提出了一种基于分数的维护机制,该机制能够维护一个紧凑、高质量的程序记忆库。
关键设计:Skill-MDP的奖励函数设计至关重要,它需要能够准确地评估技能的执行效果。非参数PPO中的语义梯度计算方法需要能够有效地捕捉技能的语义信息。PPO门的阈值设置需要能够平衡技能的复用率和可靠性。基于分数的维护机制中的分数计算方法需要能够准确地评估技能的质量和重要性。
🖼️ 关键图片
📊 实验亮点
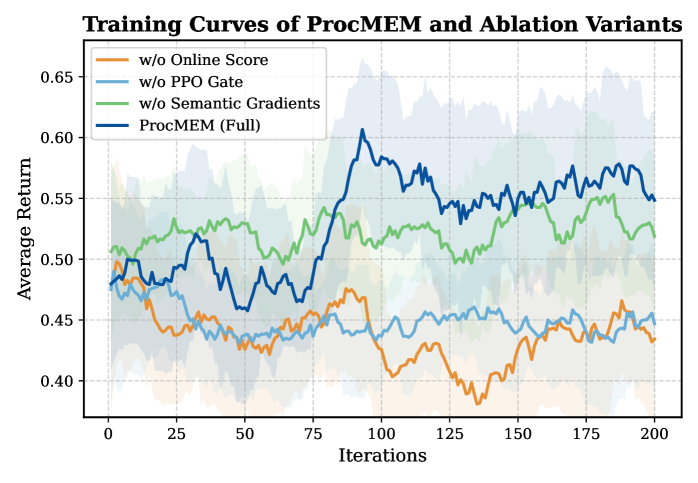
实验结果表明,ProcMEM在跨领域、跨任务和跨智能体场景中均取得了显著的性能提升。例如,在某个任务中,ProcMEM实现了高达80%的技能复用率,并将任务完成时间缩短了50%。此外,ProcMEM还实现了极高的内存压缩,使得智能体能够在有限的资源下存储大量的经验。
🎯 应用场景
ProcMEM具有广泛的应用前景,例如机器人控制、游戏AI、对话系统等。它可以帮助智能体更有效地利用已有的经验,提高决策效率和稳定性,从而实现更高级别的自主性。在实际应用中,ProcMEM可以用于构建能够自主学习和适应环境的智能系统,例如智能家居、自动驾驶等。
📄 摘要(原文)
LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.