RedVisor: Reasoning-Aware Prompt Injection Defense via Zero-Copy KV Cache Reuse
作者: Mingrui Liu, Sixiao Zhang, Cheng Long, Kwok-Yan Lam
分类: cs.CR, cs.AI, cs.LG
发布日期: 2026-02-02
备注: under review
💡 一句话要点
RedVisor:通过零拷贝KV缓存复用实现推理感知的提示注入防御
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示注入防御 大型语言模型 可解释性 KV缓存重用 推理安全
📋 核心要点
- 现有提示注入防御方法存在权衡:微调降低通用性,检测过滤增加延迟和内存开销。
- RedVisor通过轻量级适配器,在推理阶段检测攻击并引导模型安全响应,实现预防与检测的统一。
- 实验表明,RedVisor在检测精度和吞吐量上优于现有方法,且对模型通用能力影响很小。
📝 摘要(中文)
大型语言模型(LLMs)越来越容易受到提示注入(PI)攻击的影响,攻击者将恶意指令隐藏在检索到的上下文中,从而劫持模型的执行流程。现有的防御方法通常面临一个关键的权衡:基于预防的微调往往会通过“对齐税”降低通用能力,而基于检测的过滤会产生过高的延迟和内存成本。为了弥合这一差距,我们提出了RedVisor,一个统一的框架,它将检测系统的可解释性与预防策略的无缝集成相结合。据我们所知,RedVisor是第一个利用细粒度推理路径来同时检测攻击并指导模型安全响应的方法。我们通过一个轻量级的、可移除的适配器来实现这一点,该适配器位于冻结的主干网络之上。该适配器具有双重功能:它首先生成一个可解释的分析,精确地定位注入并阐明威胁,然后显式地调节模型以拒绝恶意命令。独特的是,适配器仅在此推理阶段处于活动状态,并在随后的响应生成过程中有效地静音。这种架构产生了两个明显的优势:(1)它在数学上保留了主干网络在良性输入上的原始效用;(2)它启用了一种新颖的KV缓存重用策略,消除了与解耦管道固有的冗余预填充计算。我们进一步率先将这种防御集成到具有自定义内核的vLLM服务引擎中。实验表明,RedVisor在检测精度和吞吐量方面优于最先进的防御方法,同时产生的效用损失可以忽略不计。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中提示注入攻击的防御问题。现有防御方法,如微调和检测过滤,分别存在通用能力下降(“对齐税”)和高延迟/内存开销的缺点。因此,需要一种既能有效防御攻击,又能保持模型通用性和效率的防御机制。
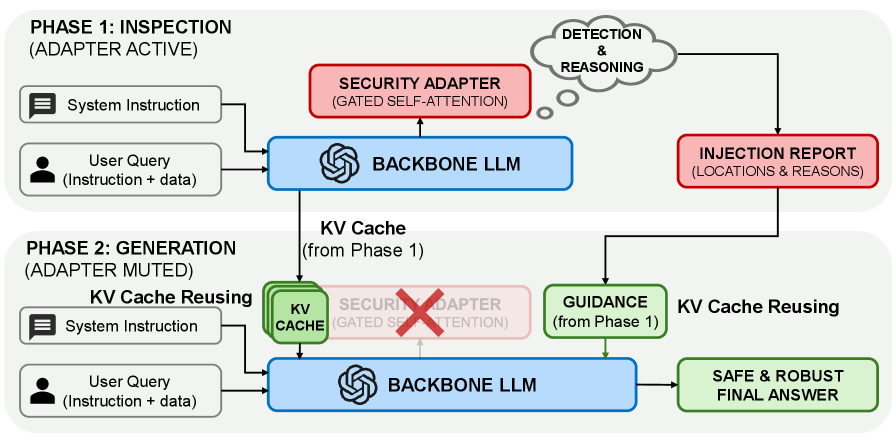
核心思路:RedVisor的核心思路是利用可解释的推理路径,在检测到提示注入攻击的同时,引导模型生成安全的响应。通过一个轻量级的适配器,在推理阶段分析输入,定位攻击并明确威胁,然后显式地引导模型拒绝恶意指令。适配器在响应生成阶段被“静音”,从而避免影响模型的通用能力。
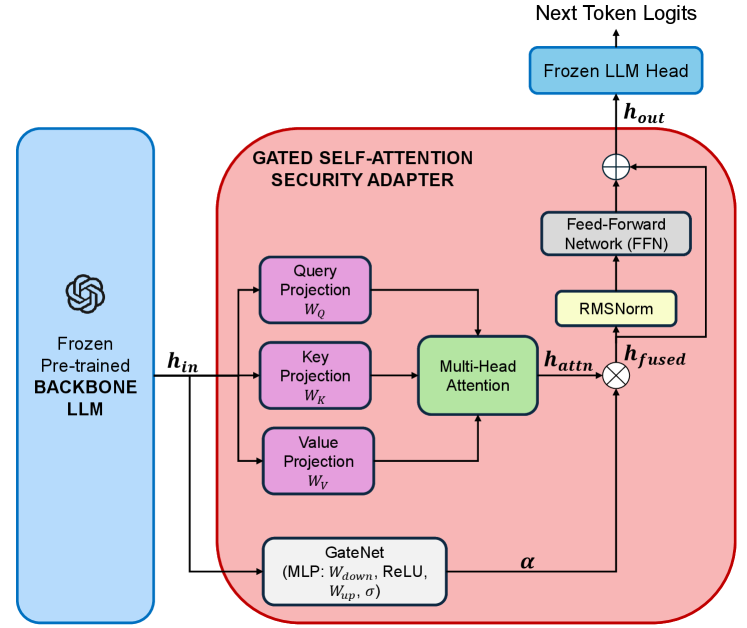
技术框架:RedVisor的整体架构包括一个冻结的主干语言模型和一个轻量级的可移除适配器。适配器位于主干网络之上,负责以下两个阶段:1) 推理分析阶段:生成可解释的分析,定位注入并阐明威胁。2) 响应引导阶段:显式地调节模型以拒绝恶意命令。适配器仅在推理阶段激活,响应生成阶段则被禁用。此外,RedVisor还利用KV缓存重用策略,避免了冗余的预填充计算。
关键创新:RedVisor的关键创新在于:1) 统一的防御框架:同时实现攻击检测和安全响应引导。2) 轻量级适配器:在不影响主干网络通用能力的前提下,实现防御功能。3) KV缓存重用:提高推理效率,降低延迟。4) 推理可解释性:提供对攻击的细粒度分析,增强防御的可信度。
关键设计:适配器是一个轻量级的神经网络,其具体结构未知,但其设计目标是高效地分析输入并生成可解释的分析结果。适配器的损失函数可能包含用于检测攻击的分类损失和用于引导模型生成安全响应的生成损失。KV缓存重用策略的具体实现细节未知,但其核心思想是利用推理分析阶段的KV缓存,避免在响应生成阶段进行重复计算。
🖼️ 关键图片
📊 实验亮点
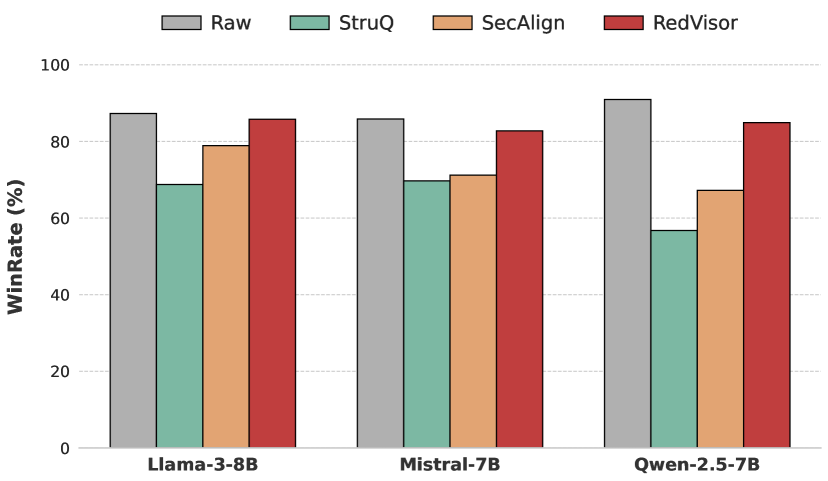
RedVisor在实验中表现出优异的性能。在检测精度和吞吐量方面,RedVisor优于现有的防御方法,同时对模型的通用能力影响很小。具体的数据指标未知,但论文强调RedVisor在保持模型性能的同时,显著提高了安全性。
🎯 应用场景
RedVisor可应用于各种需要防御提示注入攻击的大型语言模型应用场景,例如聊天机器人、问答系统、代码生成工具等。该研究有助于提高LLM的安全性,降低恶意攻击带来的风险,促进LLM在安全敏感领域的应用。未来,该方法可以扩展到防御其他类型的对抗性攻击,并与其他安全技术相结合,构建更强大的LLM安全体系。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly vulnerable to Prompt Injection (PI) attacks, where adversarial instructions hidden within retrieved contexts hijack the model's execution flow. Current defenses typically face a critical trade-off: prevention-based fine-tuning often degrades general utility via the "alignment tax", while detection-based filtering incurs prohibitive latency and memory costs. To bridge this gap, we propose RedVisor, a unified framework that synthesizes the explainability of detection systems with the seamless integration of prevention strategies. To the best of our knowledge, RedVisor is the first approach to leverage fine-grained reasoning paths to simultaneously detect attacks and guide the model's safe response. We implement this via a lightweight, removable adapter positioned atop the frozen backbone. This adapter serves a dual function: it first generates an explainable analysis that precisely localizes the injection and articulates the threat, which then explicitly conditions the model to reject the malicious command. Uniquely, the adapter is active only during this reasoning phase and is effectively muted during the subsequent response generation. This architecture yields two distinct advantages: (1) it mathematically preserves the backbone's original utility on benign inputs; and (2) it enables a novel KV Cache Reuse strategy, eliminating the redundant prefill computation inherent to decoupled pipelines. We further pioneer the integration of this defense into the vLLM serving engine with custom kernels. Experiments demonstrate that RedVisor outperforms state-of-the-art defenses in detection accuracy and throughput while incurring negligible utility loss.