PRISM: Parametrically Refactoring Inference for Speculative Sampling Draft Models
作者: Xuliang Wang, Yuetao Chen, Maochan Zhen, Fang Liu, Xinzhou Zheng, Xingwu Liu, Hong Xu, Ming Li
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-02
💡 一句话要点
PRISM:通过参数化重构推理解耦模型容量与推理成本,加速推测采样
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 模型加速 参数化重构 推理优化
📋 核心要点
- 现有推测解码方法为提升草稿质量而增大模型参数,导致计算开销显著增加,如何在准确性和延迟间平衡是核心问题。
- PRISM的核心思想是将每个预测步骤的计算分解到不同的参数集中,从而解耦模型容量与推理成本,实现高效推测解码。
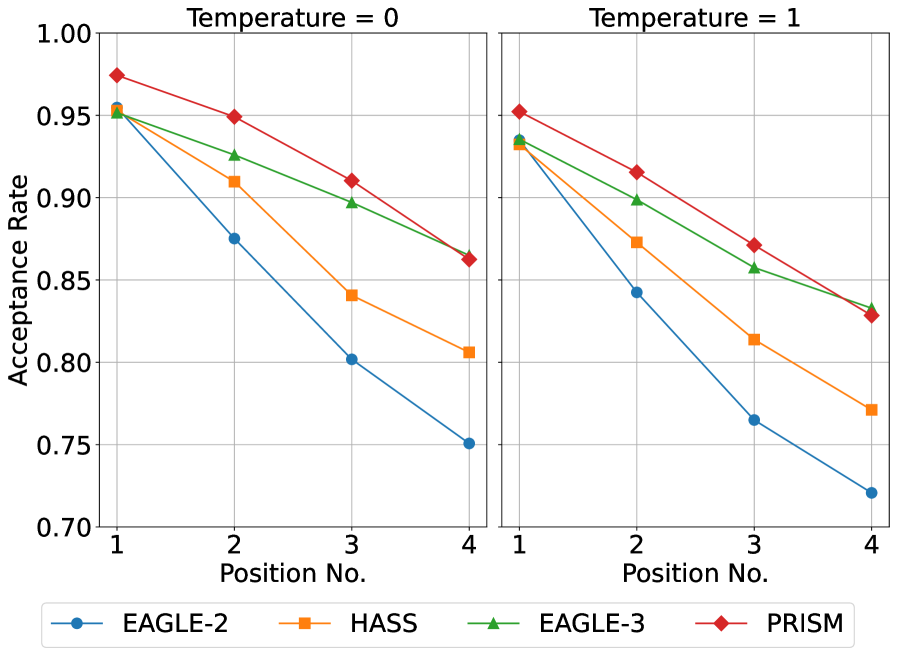
- 实验表明,PRISM在保持低延迟的同时,显著提升了接受长度,端到端加速效果优于现有草稿架构,解码吞吐量提升超过2.6倍。
📝 摘要(中文)
大型语言模型(LLMs)受限于其自回归特性,解码速度较慢。推测解码方法作为一种有前景的加速LLM解码的解决方案,受到了系统和AI研究界的关注。最近,对更好草稿质量的追求推动了参数更大的草稿模型的发展趋势,这不可避免地带来了巨大的计算开销。虽然现有的工作试图平衡预测准确性和计算延迟之间的权衡,但我们通过架构创新解决了这个根本困境。我们提出了PRISM,它将每个预测步骤的计算分解到不同的参数集中,重构了草稿模型的计算路径,从而成功地将模型容量与推理成本解耦。通过广泛的实验,我们证明PRISM优于所有现有的草稿架构,在保持最小草稿延迟的同时实现了卓越的接受长度,从而实现了卓越的端到端加速。我们还使用PRISM重新审视了缩放定律,揭示了PRISM比其他草稿架构更有效地随着数据量的扩展而扩展。通过严格和公平的比较,我们表明PRISM将已经高度优化的推理引擎的解码吞吐量提高了2.6倍以上。
🔬 方法详解
问题定义:现有的大型语言模型解码速度慢,推测解码是一种加速方法。为了提高推测解码中草稿模型的质量,现有方法倾向于使用更大的模型,但这会带来巨大的计算开销,如何在保证草稿质量的同时降低计算延迟是一个关键问题。
核心思路:PRISM的核心思路是通过参数化重构推理解耦模型容量与推理成本。具体来说,它将每个预测步骤的计算分解到不同的参数集中,使得可以使用较小的参数集进行快速的初步预测,然后使用更大的参数集进行更精确的验证,从而在不显著增加计算成本的情况下提高草稿质量。
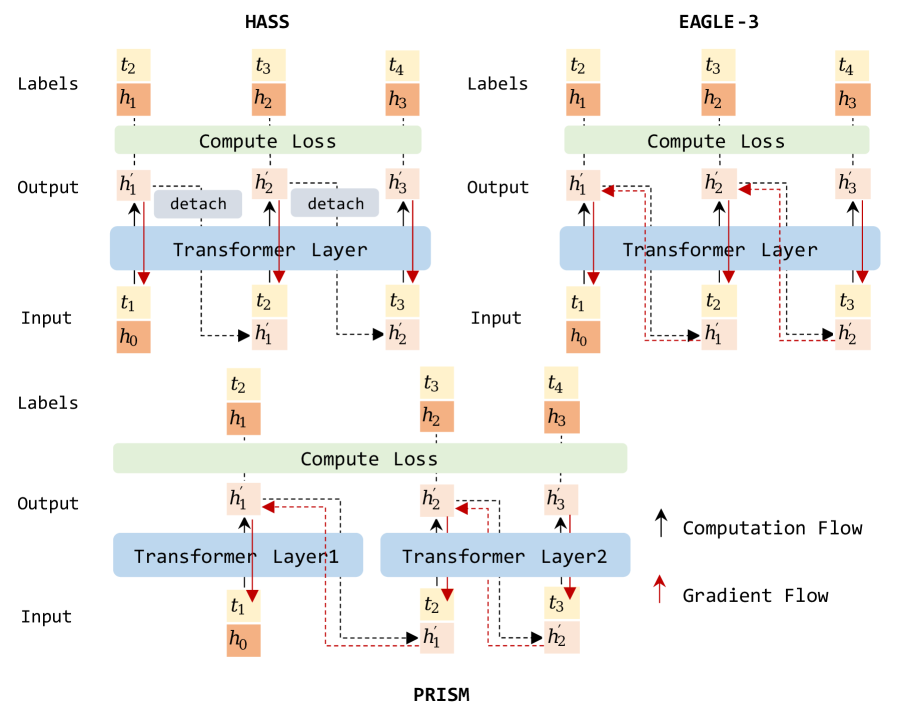
技术框架:PRISM的整体框架包括一个主模型和一个草稿模型。草稿模型被分解为多个参数集,每个参数集负责预测序列中的一个或多个token。推理过程首先使用较小的参数集生成草稿序列,然后使用主模型验证草稿序列,接受或拒绝每个token。PRISM的关键在于如何有效地分配计算资源到不同的参数集,以最大化接受长度并最小化延迟。
关键创新:PRISM最重要的创新在于其参数化重构推理机制,它打破了模型容量和推理成本之间的传统联系。通过将计算分解到不同的参数集中,PRISM可以在不增加整体模型大小的情况下,提高草稿模型的预测能力。这与现有方法中简单地增加草稿模型的大小形成了鲜明对比。
关键设计:PRISM的关键设计包括:1) 参数集的数量和大小;2) 如何将计算分配到不同的参数集;3) 如何有效地训练这些参数集。论文可能涉及了特定的损失函数或训练策略,以优化参数集的性能。具体的网络结构可能也进行了调整,以适应参数化重构推理的需求。这些细节需要参考论文的具体实现部分。
🖼️ 关键图片

📊 实验亮点
PRISM在实验中表现出色,显著优于现有草稿架构。它在保持最小草稿延迟的同时实现了卓越的接受长度,从而实现了卓越的端到端加速。具体而言,PRISM将已经高度优化的推理引擎的解码吞吐量提高了2.6倍以上,证明了其在加速LLM推理方面的巨大潜力。此外,PRISM在扩展数据量时表现出比其他草稿架构更好的缩放性能。
🎯 应用场景
PRISM技术可广泛应用于需要加速LLM推理的场景,例如在线对话系统、文本生成、机器翻译等。通过降低推理延迟,可以提升用户体验,并降低部署成本。此外,PRISM的参数化重构思想也可以应用于其他类型的深度学习模型,以提高计算效率。
📄 摘要(原文)
Large Language Models (LLMs), constrained by their auto-regressive nature, suffer from slow decoding. Speculative decoding methods have emerged as a promising solution to accelerate LLM decoding, attracting attention from both systems and AI research communities. Recently, the pursuit of better draft quality has driven a trend toward parametrically larger draft models, which inevitably introduces substantial computational overhead. While existing work attempts to balance the trade-off between prediction accuracy and compute latency, we address this fundamental dilemma through architectural innovation. We propose PRISM, which disaggregates the computation of each predictive step across different parameter sets, refactoring the computational pathways of draft models to successfully decouple model capacity from inference cost. Through extensive experiments, we demonstrate that PRISM outperforms all existing draft architectures, achieving exceptional acceptance lengths while maintaining minimal draft latency for superior end-to-end speedup. We also re-examine scaling laws with PRISM, revealing that PRISM scales more effectively with expanding data volumes than other draft architectures. Through rigorous and fair comparison, we show that PRISM boosts the decoding throughput of an already highly optimized inference engine by more than 2.6x.