Optimizing Prompts for Large Language Models: A Causal Approach
作者: Wei Chen, Yanbin Fang, Shuran Fu, Fasheng Xu, Xuan Wei
分类: cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出因果提示优化(CPO)框架,解决大语言模型提示工程中的泛化性和成本问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 提示工程 因果推断 自动提示优化 双重机器学习 企业应用 鲁棒性 查询优化
📋 核心要点
- 现有自动提示优化方法难以适应不同查询,且依赖的离线奖励模型存在偏差,影响优化效果。
- CPO框架将提示设计视为因果估计问题,通过双重机器学习(DML)学习无偏的离线奖励模型。
- 实验表明,CPO在数学推理、可视化和数据分析等任务上优于现有方法,尤其在困难查询上表现更佳。
📝 摘要(中文)
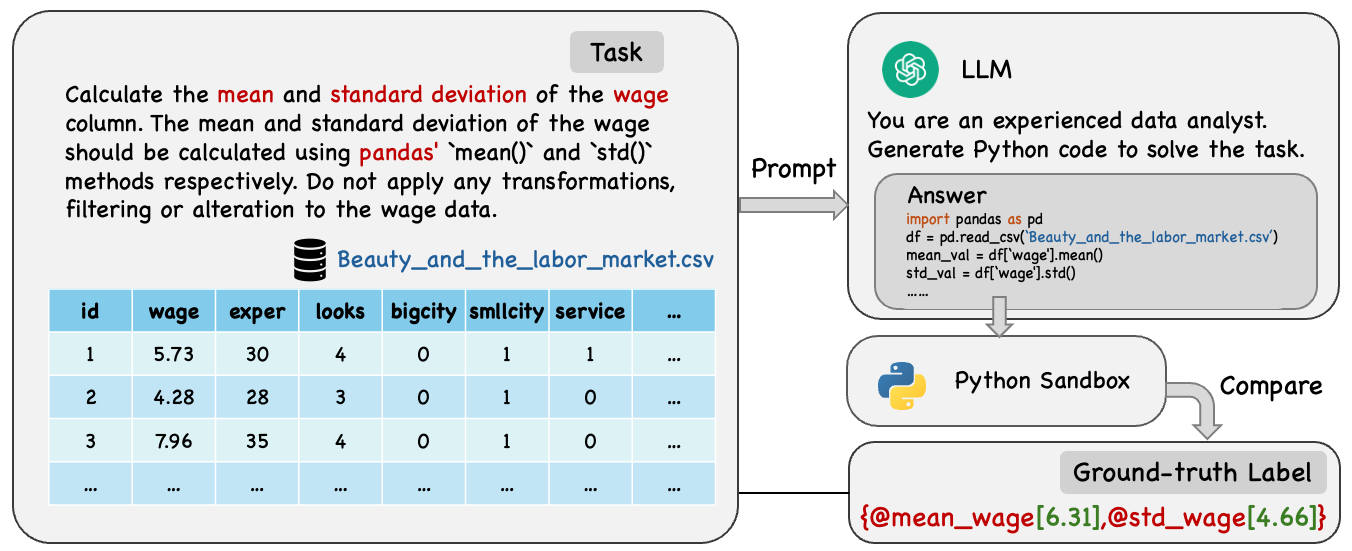
大型语言模型(LLM)越来越多地嵌入到企业工作流程中,但其性能仍然对提示设计高度敏感。自动提示优化(APO)旨在缓解这种不稳定性,但现有方法面临两个持续的挑战。首先,常用的提示策略依赖于静态指令,这些指令平均表现良好,但无法适应异构查询。其次,更动态的方法依赖于根本上是相关的离线奖励模型,将提示有效性与查询特征混淆。我们提出了因果提示优化(CPO),该框架将提示设计重新定义为因果估计问题。CPO分两个阶段运行。首先,它通过将双重机器学习(DML)应用于提示和查询的语义嵌入,学习离线因果奖励模型,从而将提示变化的因果效应与混淆查询属性隔离开来。其次,它利用这种无偏奖励信号来指导资源高效的查询特定提示搜索,而无需依赖昂贵的在线评估。我们在数学推理、可视化和数据分析的基准测试中评估了CPO。CPO始终优于人工设计的提示和最先进的自动优化器。收益主要来自在困难查询上的鲁棒性提高,现有方法往往会在这些查询上恶化。除了性能之外,CPO从根本上改变了提示优化的经济性:通过将评估从实时模型执行转移到离线因果模型,它能够以在线方法所需的一小部分推理成本实现高精度、每个查询的定制。总之,这些结果确立了因果推断作为企业LLM部署中可靠且经济高效的提示优化的可扩展基础。
🔬 方法详解
问题定义:现有自动提示优化方法,如基于静态指令的方法,无法很好地适应不同类型的查询,导致泛化能力不足。而依赖离线奖励模型的方法,由于奖励模型是基于相关性学习的,会混淆提示的有效性和查询的固有属性,导致优化结果存在偏差。因此,需要一种能够适应不同查询,并且能够消除混淆因素的提示优化方法。
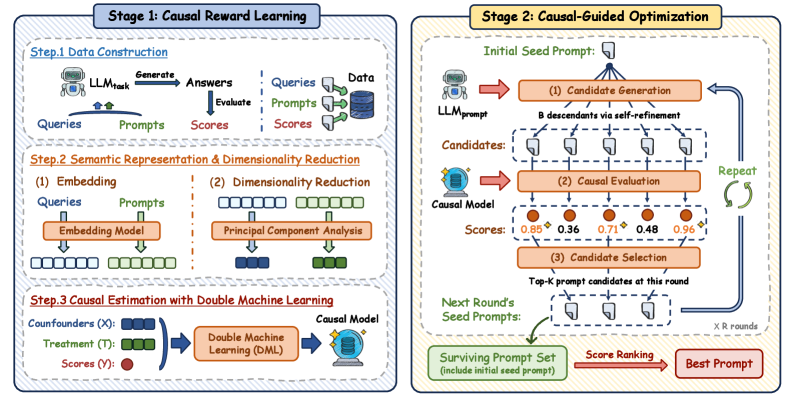
核心思路:CPO的核心思路是将提示优化问题视为一个因果推断问题。通过识别和消除查询属性对提示效果的混淆影响,从而得到提示的真实因果效应。具体来说,CPO使用双重机器学习(DML)来估计提示的因果效应,并利用这个无偏的估计来指导提示的搜索和优化。
技术框架:CPO框架包含两个主要阶段:1) 离线因果奖励模型学习:使用双重机器学习(DML)从提示和查询的语义嵌入中学习因果奖励模型,消除查询属性的混淆影响。2) 在线提示搜索:利用学习到的无偏奖励信号,指导资源高效的查询特定提示搜索,无需昂贵的在线评估。
关键创新:CPO的关键创新在于将因果推断引入到提示优化中。通过使用双重机器学习(DML)来估计提示的因果效应,从而消除了查询属性的混淆影响,得到了更准确的奖励信号。这使得CPO能够更有效地搜索和优化提示,从而提高LLM的性能。与现有方法相比,CPO能够更好地适应不同类型的查询,并且能够避免由于奖励模型偏差而导致的优化问题。
关键设计:CPO使用预训练语言模型(如BERT)来提取提示和查询的语义嵌入。双重机器学习(DML)的具体实现包括两个回归模型:一个用于预测提示对结果的影响,另一个用于预测查询属性对结果的影响。DML通过交叉拟合的方式来消除偏差。奖励函数基于DML估计的因果效应。提示搜索算法可以是任何资源高效的搜索算法,例如进化算法或梯度下降。
🖼️ 关键图片

📊 实验亮点
CPO在数学推理、可视化和数据分析等基准测试中,始终优于人工设计的提示和最先进的自动优化器。尤其在困难查询上,CPO的鲁棒性显著提高,克服了现有方法性能下降的问题。CPO通过离线因果模型,大幅降低了提示优化的计算成本,使得高精度、每个查询的定制成为可能。
🎯 应用场景
CPO可广泛应用于企业级LLM部署,提升模型在各种任务中的性能和鲁棒性,例如客户服务、数据分析、内容生成等。通过降低提示优化的成本,CPO使得为每个查询定制提示成为可能,从而显著提高LLM在实际应用中的价值。该方法还有助于提高LLM的可解释性和可控性。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly embedded in enterprise workflows, yet their performance remains highly sensitive to prompt design. Automatic Prompt Optimization (APO) seeks to mitigate this instability, but existing approaches face two persistent challenges. First, commonly used prompt strategies rely on static instructions that perform well on average but fail to adapt to heterogeneous queries. Second, more dynamic approaches depend on offline reward models that are fundamentally correlational, confounding prompt effectiveness with query characteristics. We propose Causal Prompt Optimization (CPO), a framework that reframes prompt design as a problem of causal estimation. CPO operates in two stages. First, it learns an offline causal reward model by applying Double Machine Learning (DML) to semantic embeddings of prompts and queries, isolating the causal effect of prompt variations from confounding query attributes. Second, it utilizes this unbiased reward signal to guide a resource-efficient search for query-specific prompts without relying on costly online evaluation. We evaluate CPO across benchmarks in mathematical reasoning, visualization, and data analytics. CPO consistently outperforms human-engineered prompts and state-of-the-art automated optimizers. The gains are driven primarily by improved robustness on hard queries, where existing methods tend to deteriorate. Beyond performance, CPO fundamentally reshapes the economics of prompt optimization: by shifting evaluation from real-time model execution to an offline causal model, it enables high-precision, per-query customization at a fraction of the inference cost required by online methods. Together, these results establish causal inference as a scalable foundation for reliable and cost-efficient prompt optimization in enterprise LLM deployments.