What LLMs Think When You Don't Tell Them What to Think About?
作者: Yongchan Kwon, James Zou
分类: cs.AI, cs.LG
发布日期: 2026-02-02
备注: NA
💡 一句话要点
研究揭示:在无主题引导下,大语言模型展现出显著且系统性的主题偏好
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 生成行为 主题偏好 无约束生成 模型评估 AI安全 内容生成 LLM分析
📋 核心要点
- 现有LLM分析依赖于特定主题提示,限制了对模型生成行为的全面理解,无法充分揭示其潜在偏好。
- 该研究通过提供最小化的、主题中立的输入,探索LLM在近乎无约束条件下的生成行为,揭示其内在偏好。
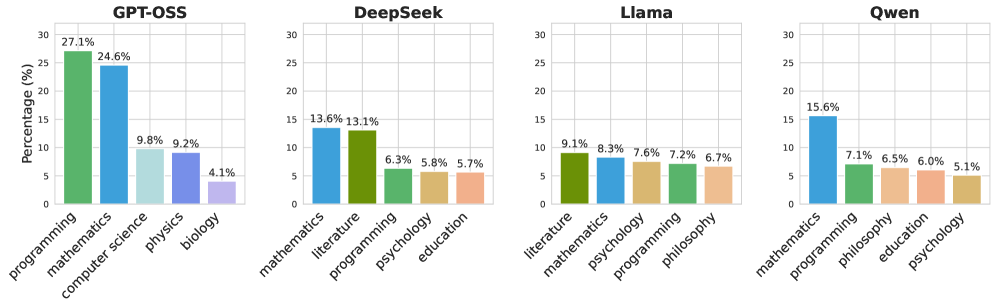
- 实验结果表明,不同LLM家族在无主题引导下表现出强烈且系统性的主题偏好,并存在内容专业化和深度差异。
📝 摘要(中文)
为了可靠地监控和保障人工智能安全,全面刻画大语言模型(LLM)在不同场景下的行为至关重要。然而,现有的大部分分析依赖于特定主题或任务的提示,这大大限制了可观察到的内容。本文研究了LLM在接受最少的、主题中立的输入时所生成的内容,从而探究其近乎无约束的生成行为。尽管缺乏明确的主题,模型输出覆盖了广泛的语义空间。令人惊讶的是,每个模型家族都表现出强烈且系统性的主题偏好。例如,GPT-OSS主要生成编程(27.1%)和数学内容(24.6%),而Llama最常生成文学内容(9.1%)。DeepSeek经常生成宗教内容,而Qwen则频繁生成多项选择题。除了主题偏好之外,我们还观察到内容专业化和深度方面的差异:与其他模型(例如,基础Python)相比,GPT-OSS通常生成技术上更高级的内容(例如,动态编程)。此外,我们发现近乎无约束的生成经常退化为重复的短语,揭示了每个模型家族独有的有趣行为。例如,Llama的退化输出包括指向个人Facebook和Instagram帐户的多个URL。我们发布了来自16个LLM的256,000个样本的完整数据集,以及可复现的代码库。
🔬 方法详解
问题定义:现有的大语言模型评估方法通常依赖于特定任务或主题的提示,这限制了我们对模型真实生成能力的理解,也难以发现模型潜在的偏好和弱点。因此,如何设计一种更通用的评估方法,在尽可能少的约束下探究LLM的生成行为,成为了一个重要的研究问题。
核心思路:本研究的核心思路是采用最小化的、主题中立的输入作为提示,让LLM在近乎无约束的条件下自由生成文本。通过分析这些生成的文本,可以揭示模型内在的主题偏好、内容专业化程度以及潜在的生成退化行为。这种方法旨在更全面地了解LLM的生成能力和潜在风险。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个具有代表性的大语言模型(例如GPT-OSS, Llama, DeepSeek, Qwen等);2) 设计最小化的、主题中立的输入提示(例如空字符串或简单的指令);3) 使用这些提示让LLM生成大量的文本样本;4) 对生成的文本样本进行分析,包括主题分类、内容深度评估和重复性检测;5) 比较不同LLM家族之间的生成行为差异,并总结其各自的特点。
关键创新:该研究的关键创新在于其评估方法的通用性和无约束性。与传统的基于特定任务的评估方法相比,该研究采用的最小化提示可以更全面地揭示LLM的内在偏好和生成能力。此外,该研究还首次系统地比较了不同LLM家族在无约束条件下的生成行为差异,为LLM的安全性评估和改进提供了新的视角。
关键设计:在实验设计方面,研究者选择了16个具有代表性的LLM,并为每个模型生成了大量的文本样本(总共256,000个样本)。为了保证评估的客观性,研究者采用了自动化的主题分类方法,并结合人工评估来验证结果的准确性。此外,研究者还设计了一系列指标来评估生成文本的内容深度和重复性,从而更全面地刻画LLM的生成行为。
🖼️ 关键图片

📊 实验亮点
研究发现,即使在没有明确主题引导的情况下,不同LLM家族也表现出显著的主题偏好。例如,GPT-OSS倾向于生成编程和数学内容(占比超过50%),而Llama则更倾向于生成文学内容。此外,研究还发现GPT-OSS生成的内容在技术深度上通常高于其他模型,而Llama则容易生成指向个人社交媒体账户的重复性内容。
🎯 应用场景
该研究成果可应用于大语言模型的安全评估、模型优化和风险控制。通过了解模型在无约束条件下的生成偏好和潜在风险,可以更好地设计安全策略,避免模型生成有害或不当内容。此外,该研究还可以帮助开发者优化模型,提高其生成能力和泛化性能。
📄 摘要(原文)
Characterizing the behavior of large language models (LLMs) across diverse settings is critical for reliable monitoring and AI safety. However, most existing analyses rely on topic- or task-specific prompts, which can substantially limit what can be observed. In this work, we study what LLMs generate from minimal, topic-neutral inputs and probe their near-unconstrained generative behavior. Despite the absence of explicit topics, model outputs cover a broad semantic space, and surprisingly, each model family exhibits strong and systematic topical preferences. GPT-OSS predominantly generates programming (27.1%) and mathematical content (24.6%), whereas Llama most frequently generates literary content (9.1%). DeepSeek often generates religious content, while Qwen frequently generates multiple-choice questions. Beyond topical preferences, we also observe differences in content specialization and depth: GPT-OSS often generates more technically advanced content (e.g., dynamic programming) compared with other models (e.g., basic Python). Furthermore, we find that the near-unconstrained generation often degenerates into repetitive phrases, revealing interesting behaviors unique to each model family. For instance, degenerate outputs from Llama include multiple URLs pointing to personal Facebook and Instagram accounts. We release the complete dataset of 256,000 samples from 16 LLMs, along with a reproducible codebase.