The Strategic Foresight of LLMs: Evidence from a Fully Prospective Venture Tournament
作者: Felipe A. Csaszar, Aticus Peterson, Daniel Wilde
分类: econ.GN, cs.AI
发布日期: 2026-02-02
备注: 60 pages, 11 figures, 4 tables
💡 一句话要点
大型语言模型在战略预测中超越人类专家,尤其在众筹项目成功预测方面
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 战略预测 众筹项目 风险投资 人工智能 预测模型 文本分析
📋 核心要点
- 现有战略预测方法依赖人类专家,但主观性强且效率低,难以应对快速变化的市场。
- 利用大型语言模型(LLM)的文本理解和推理能力,直接预测高风险事件的结果,无需人工干预。
- 实验表明,前沿LLM在预测众筹项目成功率方面显著优于人类专家,尤其Gemini 2.5 Pro模型表现突出。
📝 摘要(中文)
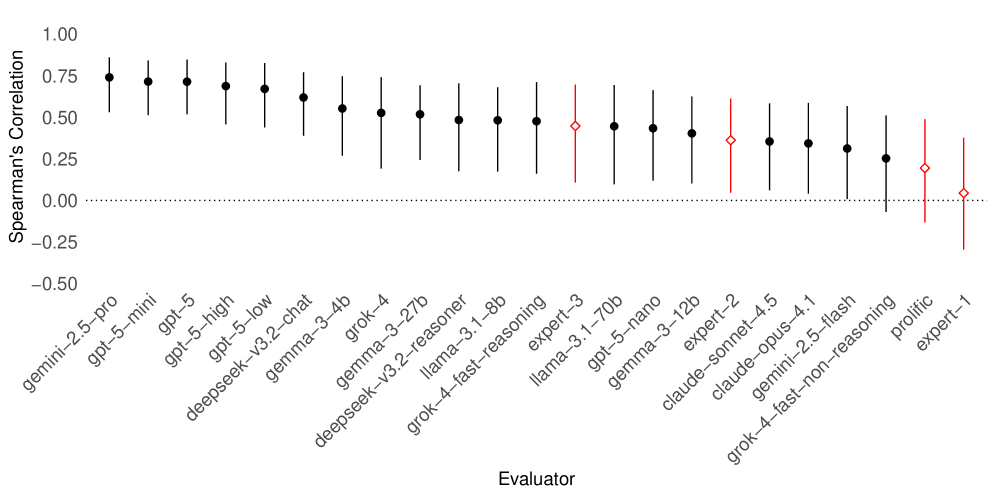
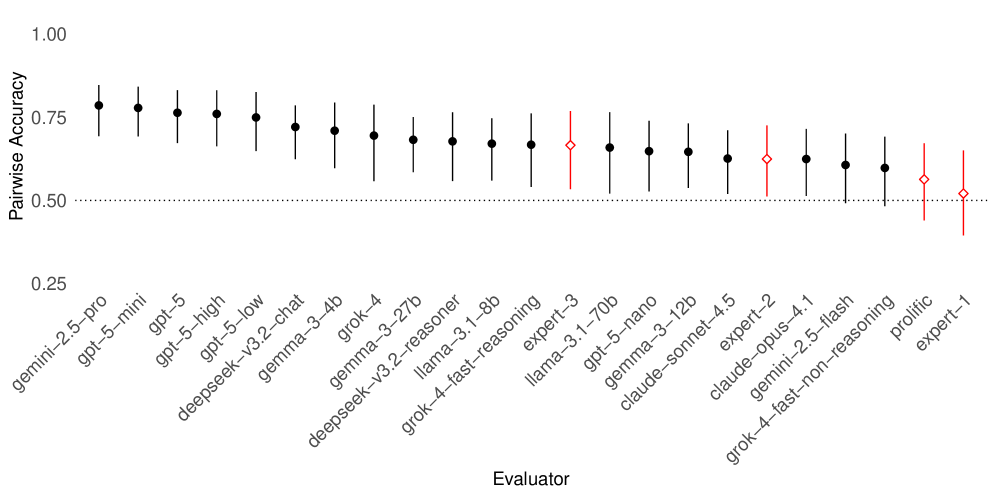
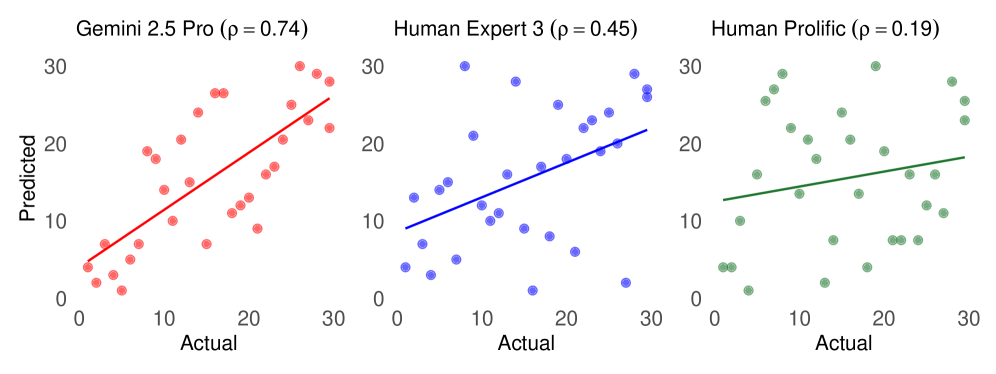
本文通过一个完全前瞻性的风险投资竞赛,探讨了人工智能在战略预测方面的能力,即在不确定的高风险结果发生之前做出准确判断的能力。研究使用了真实的Kickstarter众筹项目,评估了30个在美国成立的科技企业。这些企业在所有研究模型的训练截止日期之后启动,并在筹款仍在进行、结果未知的情况下接受评估。一系列前沿和开放权重的大型语言模型(LLM)完成了870次成对比较,生成了预测筹款成功的完整排名。研究将这些预测与通过Prolific招募的346名经验丰富的管理者以及在监控条件下工作的3名接受过MBA培训的投资者进行了对比。结果表明,人类评估者的排名相关性在0.04到0.45之间,而几个前沿LLM超过了0.60,其中最佳模型(Gemini 2.5 Pro)达到了0.74,正确排序了近五分之四的风险投资对。这些差异在多个性能指标和稳健性检查中持续存在。无论是群体智慧集成还是人机混合团队,都未能超越最佳的独立模型。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在战略预测方面的能力,具体来说,就是预测Kickstarter众筹项目的成功与否。现有方法主要依赖于人类专家,但人类专家的预测容易受到主观偏见的影响,且成本较高,难以规模化应用。因此,如何利用AI模型实现更准确、更高效的战略预测是本文要解决的核心问题。
核心思路:论文的核心思路是利用LLM对众筹项目的相关文本信息进行分析,从而预测项目的筹款成功率。这种方法的核心在于,LLM能够从大量的文本数据中学习到与项目成功相关的模式和特征,从而做出更准确的预测。此外,通过成对比较的方式,可以更有效地评估LLM的预测能力。
技术框架:整体框架包括以下几个阶段:1) 数据收集:收集Kickstarter平台上30个科技众筹项目的相关信息,包括项目描述、发起人信息等。2) 模型预测:利用一系列前沿和开放权重的大型语言模型(LLM)对这些项目进行成对比较,生成预测筹款成功的完整排名。3) 人类评估:招募经验丰富的管理者和MBA培训的投资者作为人类评估者,对这些项目进行评估并排名。4) 结果对比:将LLM的预测结果与人类评估者的结果进行对比,评估LLM的预测准确性。
关键创新:论文的关键创新在于:1) 首次将LLM应用于战略预测领域,并证明了其在预测众筹项目成功率方面的优越性。2) 通过完全前瞻性的预测竞赛,在真实场景下评估了LLM的预测能力,避免了后见之明偏差。3) 详细对比了LLM与人类专家在战略预测方面的表现,揭示了LLM在某些方面超越人类专家的潜力。
关键设计:论文的关键设计包括:1) 使用成对比较的方式评估LLM的预测能力,这种方法可以更有效地捕捉模型之间的细微差异。2) 选择Kickstarter众筹项目作为研究对象,因为这些项目具有明确的成功标准和丰富的文本信息。3) 招募不同背景的人类评估者,以减少主观偏见的影响。4) 使用多种性能指标(如Spearman秩相关系数)来评估LLM的预测准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,前沿LLM在预测众筹项目成功率方面显著优于人类专家。其中,最佳模型Gemini 2.5 Pro的Spearman秩相关系数达到了0.74,而人类评估者的相关系数仅在0.04到0.45之间。这意味着Gemini 2.5 Pro能够正确排序近五分之四的风险投资对。此外,无论是群体智慧集成还是人机混合团队,都未能超越最佳的独立模型。
🎯 应用场景
该研究成果可应用于风险投资、市场预测、政策制定等领域。通过利用LLM进行战略预测,可以帮助投资者更准确地评估投资项目的潜力,降低投资风险。同时,也可以为企业提供市场趋势预测,辅助企业制定更有效的营销策略。此外,政府部门也可以利用LLM进行政策效果评估,提高政策制定的科学性。
📄 摘要(原文)
Can artificial intelligence outperform humans at strategic foresight -- the capacity to form accurate judgments about uncertain, high-stakes outcomes before they unfold? We address this question through a fully prospective prediction tournament using live Kickstarter crowdfunding projects. Thirty U.S.-based technology ventures, launched after the training cutoffs of all models studied, were evaluated while fundraising remained in progress and outcomes were unknown. A diverse suite of frontier and open-weight large language models (LLMs) completed 870 pairwise comparisons, producing complete rankings of predicted fundraising success. We benchmarked these forecasts against 346 experienced managers recruited via Prolific and three MBA-trained investors working under monitored conditions. The results are striking: human evaluators achieved rank correlations with actual outcomes between 0.04 and 0.45, while several frontier LLMs exceeded 0.60, with the best (Gemini 2.5 Pro) reaching 0.74 -- correctly ordering nearly four of every five venture pairs. These differences persist across multiple performance metrics and robustness checks. Neither wisdom-of-the-crowd ensembles nor human-AI hybrid teams outperformed the best standalone model.