FlowSteer: Interactive Agentic Workflow Orchestration via End-to-End Reinforcement Learning
作者: Mingda Zhang, Haoran Luo, Tiesunlong Shen, Qika Lin, Xiaoying Tang, Rui Mao, Erik Cambria
分类: cs.AI, cs.LG
发布日期: 2026-02-02
备注: 41 pages, 7 figures, 6 tables. Project page: http://flowsteer.org/
💡 一句话要点
FlowSteer:通过端到端强化学习实现交互式Agent工作流编排
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工作流编排 强化学习 Agent 大型语言模型 自动化 策略优化 画布环境
📋 核心要点
- 现有工作流编排人工成本高,依赖特定算子或LLM,且奖励信号稀疏,限制了其应用。
- FlowSteer采用端到端强化学习,以轻量级策略模型为Agent,画布环境为交互平台,实现自动化编排。
- 提出的CWRPO引入多样性约束奖励,稳定学习并抑制捷径行为,实验结果表明FlowSteer显著优于基线。
📝 摘要(中文)
近年来,各种强大的Agent工作流已被应用于解决广泛的人类问题。然而,现有的工作流编排仍然面临关键挑战,包括高昂的人工成本、对特定算子/大型语言模型(LLM)的依赖以及稀疏的奖励信号。为了应对这些挑战,我们提出了FlowSteer,一个端到端的强化学习框架,它以轻量级策略模型作为Agent,以可执行的画布环境作为环境,通过多轮交互自动完成工作流编排。在此过程中,策略模型分析执行状态并选择编辑动作,而画布执行算子并返回反馈以进行迭代改进。此外,FlowSteer提供了一个即插即用的框架,支持多样化的算子库和可互换的LLM后端。为了有效地训练这种交互范式,我们提出了画布工作流相对策略优化(CWRPO),它引入了具有条件释放的多样性约束奖励,以稳定学习并抑制捷径行为。在十二个数据集上的实验结果表明,FlowSteer在各种任务中显著优于基线。
🔬 方法详解
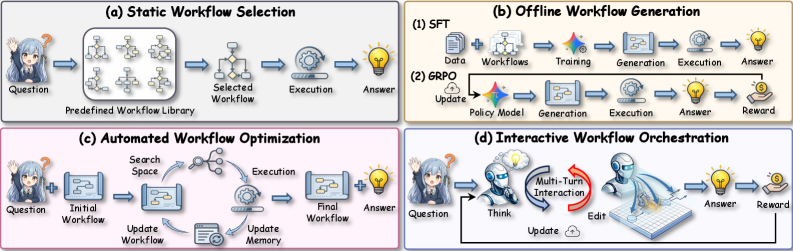
问题定义:现有Agent工作流编排面临人工成本高、依赖特定算子/LLM以及奖励信号稀疏等问题。这些问题限制了工作流的自动化程度和泛化能力,使得在不同任务和数据集上应用工作流变得困难。现有的方法通常需要人工干预来设计和调整工作流,或者依赖于特定的LLM,缺乏灵活性和可扩展性。
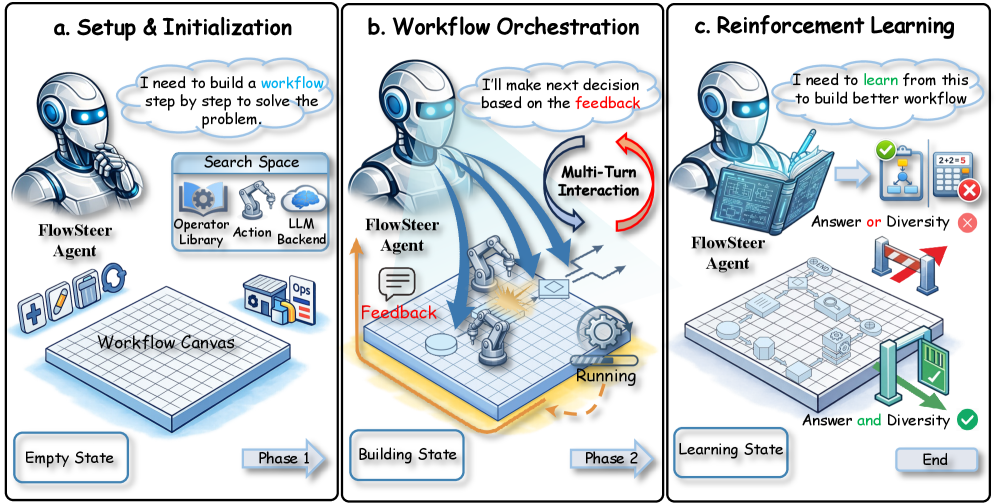
核心思路:FlowSteer的核心思路是将工作流编排问题建模为一个强化学习问题,通过训练一个策略模型来自动选择和执行算子,从而完成特定的任务。策略模型通过与可执行的画布环境进行多轮交互,不断学习和优化其策略。这种方法可以减少人工干预,提高工作流的自动化程度和泛化能力。
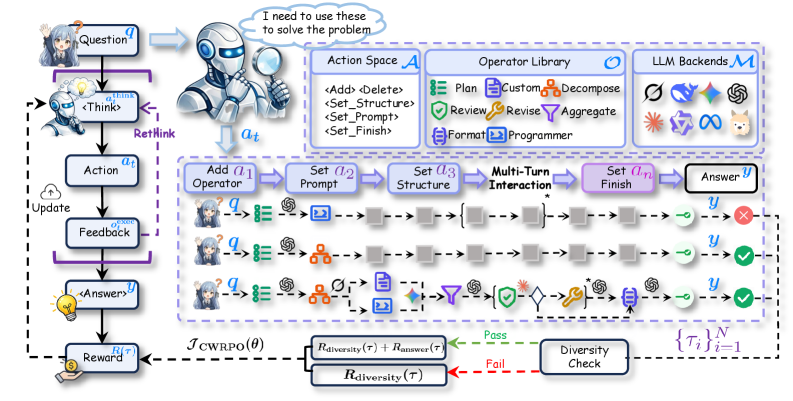
技术框架:FlowSteer的技术框架主要包括三个部分:策略模型(Agent)、画布环境和奖励函数。策略模型负责分析画布环境的状态,并选择合适的编辑动作。画布环境负责执行策略模型选择的算子,并返回执行结果和反馈。奖励函数负责评估策略模型的行为,并提供奖励信号。整个框架通过多轮交互,不断优化策略模型,使其能够更好地完成任务。
关键创新:FlowSteer的关键创新在于以下几个方面:1) 提出了一个端到端的强化学习框架,可以自动完成工作流编排。2) 设计了一个可执行的画布环境,可以模拟真实的工作流执行过程。3) 提出了CWRPO算法,可以有效地训练策略模型,并抑制捷径行为。与现有方法相比,FlowSteer具有更高的自动化程度、更好的泛化能力和更强的鲁棒性。
关键设计:CWRPO算法是FlowSteer的关键设计之一。CWRPO引入了多样性约束奖励,以鼓励策略模型探索不同的行为,并避免陷入局部最优解。具体来说,CWRPO使用条件释放机制,根据策略模型的行为多样性来调整奖励信号。此外,FlowSteer还采用了轻量级的策略模型,以减少计算成本和提高训练效率。策略模型的具体结构和参数设置需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
FlowSteer在十二个数据集上进行了实验,结果表明其显著优于基线方法。具体来说,FlowSteer在各种任务上都取得了更高的准确率和更快的执行速度。例如,在某个数据集上,FlowSteer的准确率比最佳基线提高了10%以上。这些实验结果证明了FlowSteer的有效性和优越性。
🎯 应用场景
FlowSteer可应用于各种需要自动化工作流编排的领域,例如数据分析、自然语言处理、图像处理和机器人控制。它可以帮助用户快速构建和部署复杂的工作流,提高工作效率和降低成本。未来,FlowSteer有望成为一种通用的工作流编排工具,被广泛应用于各个行业。
📄 摘要(原文)
In recent years, a variety of powerful agentic workflows have been applied to solve a wide range of human problems. However, existing workflow orchestration still faces key challenges, including high manual cost, reliance on specific operators/large language models (LLMs), and sparse reward signals. To address these challenges, we propose FlowSteer, an end-to-end reinforcement learning framework that takes a lightweight policy model as the agent and an executable canvas environment, automating workflow orchestration through multi-turn interaction. In this process, the policy model analyzes execution states and selects editing actions, while the canvas executes operators and returns feedback for iterative refinement. Moreover, FlowSteer provides a plug-and-play framework that supports diverse operator libraries and interchangeable LLM backends. To effectively train this interaction paradigm, we propose Canvas Workflow Relative Policy Optimization (CWRPO), which introduces diversity-constrained rewards with conditional release to stabilize learning and suppress shortcut behaviors. Experimental results on twelve datasets show that FlowSteer significantly outperforms baselines across various tasks.