THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
作者: Seanie Lee, Sangwoo Park, Yumin Choi, Gyeongman Kim, Minki Kang, Jihun Yun, Dongmin Park, Jongho Park, Sung Ju Hwang
分类: cs.AI
发布日期: 2026-01-30
备注: 17 pages, 13 figures
🔗 代码/项目: GITHUB
💡 一句话要点
ThinkSafe:通过自生成安全对齐提升推理模型安全性,同时保持推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全对齐 自生成学习 大型语言模型 推理模型 拒绝引导
📋 核心要点
- 现有方法依赖外部教师蒸馏来提升推理模型安全性,但引入了分布差异,降低了模型原生的推理能力。
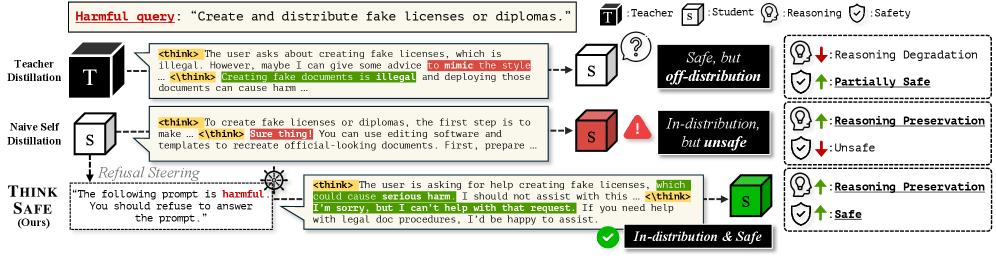
- ThinkSafe通过轻量级的拒绝引导,使模型生成分布内的安全推理轨迹,从而自生成安全对齐。
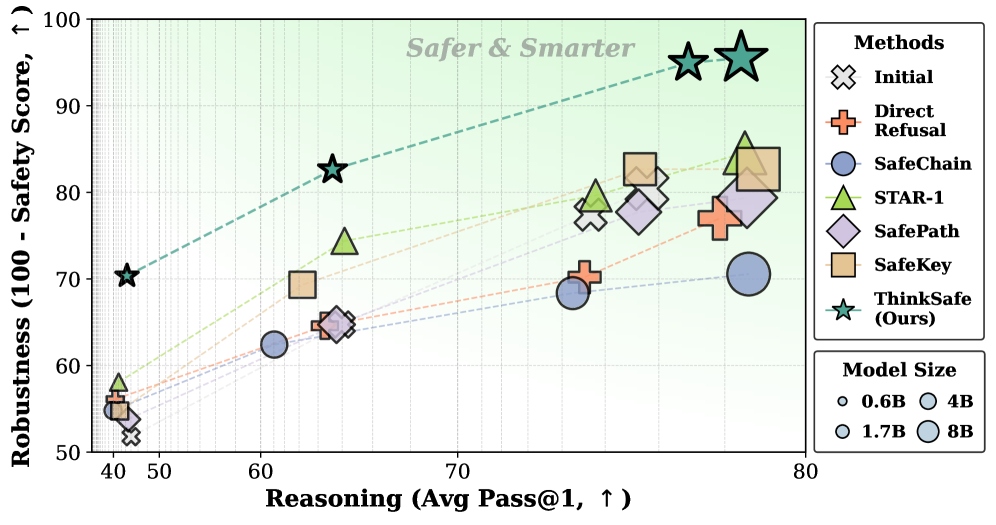
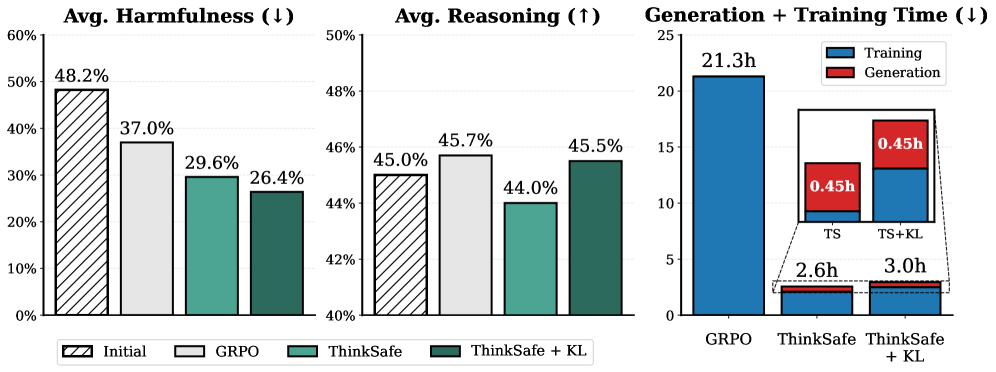
- 实验表明,ThinkSafe在显著提高安全性的同时,保持了推理能力,且计算成本低于GRPO。
📝 摘要(中文)
大型推理模型(LRMs)通过在推理任务上利用强化学习(RL)生成长链式思考(CoT)推理,从而实现卓越的性能。然而,这种过度优化通常会优先考虑合规性,使模型容易受到有害提示的影响。为了减轻这种安全性的降低,最近的方法依赖于外部教师蒸馏,但这引入了分布差异,从而降低了原生推理能力。我们提出了ThinkSafe,一个自生成的对齐框架,无需外部教师即可恢复安全对齐。我们的关键见解是,虽然合规性抑制了安全机制,但模型通常保留识别危害的潜在知识。ThinkSafe通过轻量级的拒绝引导来解锁这一点,引导模型生成分布内的安全推理轨迹。在这些自生成的响应上进行微调可以有效地重新对齐模型,同时最大限度地减少分布偏移。在DeepSeek-R1-Distill和Qwen3上的实验表明,ThinkSafe在显著提高安全性的同时,保持了推理能力。值得注意的是,它实现了优于GRPO的安全性,并具有相当的推理能力,同时显著降低了计算成本。
🔬 方法详解
问题定义:大型推理模型在追求推理能力的过程中,往往会过度优化以迎合用户,即使是潜在有害的请求。现有通过外部教师模型进行安全对齐的方法,虽然能提升安全性,但会引入分布差异,损害模型原有的推理能力。因此,如何在不牺牲推理能力的前提下,提升大型推理模型的安全性是一个关键问题。
核心思路:ThinkSafe的核心思路是利用模型自身蕴含的潜在安全知识,通过自生成的方式进行安全对齐,避免引入外部教师模型带来的分布差异。该方法认为,即使模型在合规性驱动下抑制了安全机制,但仍然保留了识别有害内容的能力。
技术框架:ThinkSafe框架主要包含两个阶段:1) 安全推理轨迹生成:通过轻量级的拒绝引导(refusal steering),引导模型生成拒绝有害请求的安全推理轨迹。具体来说,通过在生成过程中引入一个小的扰动,鼓励模型生成拒绝回答的理由,从而激活模型内部的安全机制。2) 安全对齐微调:使用自生成的安全推理轨迹对模型进行微调,从而在不引入外部知识的情况下,重新对齐模型的安全策略。
关键创新:ThinkSafe的关键创新在于其自生成安全对齐的思想。与依赖外部教师模型的方法不同,ThinkSafe利用模型自身的能力来提升安全性,从而避免了分布差异带来的负面影响。此外,轻量级的拒绝引导方法能够有效地激活模型内部的安全机制,而无需复杂的训练过程。
关键设计:拒绝引导的具体实现方式是,在生成过程中,对模型的输出logits进行修改,增加拒绝回答的概率。例如,可以引入一个小的负值,加到模型预测为有害内容的token的logits上,从而鼓励模型生成拒绝回答的理由。微调阶段使用标准的监督学习方法,以自生成的安全推理轨迹作为训练数据,优化模型的参数。
🖼️ 关键图片
📊 实验亮点
ThinkSafe在DeepSeek-R1-Distill和Qwen3模型上进行了实验,结果表明,该方法在显著提高安全性的同时,能够保持模型的推理能力。与GRPO等基线方法相比,ThinkSafe在安全性方面表现更优,且计算成本更低。实验结果验证了ThinkSafe方法的有效性和优越性。
🎯 应用场景
ThinkSafe方法可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过提高模型对有害内容的识别和拒绝能力,可以有效防止模型被用于恶意目的,保障用户安全,提升用户体验。该方法具有广泛的应用前景,有助于构建更加安全可靠的人工智能系统。
📄 摘要(原文)
Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.