Guided by Trajectories: Repairing and Rewarding Tool-Use Trajectories for Tool-Integrated Reasoning
作者: Siyu Gong, Linan Yue, Weibo Gao, Fangzhou Yao, Shimin Di, Lei Feng, Min-Ling Zhang
分类: cs.AI
发布日期: 2026-01-30
💡 一句话要点
AutoTraj:通过修复和奖励工具使用轨迹,提升工具集成推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具集成推理 大型语言模型 轨迹修复 奖励模型 强化学习 监督微调 自动化推理
📋 核心要点
- 现有工具集成推理方法依赖高质量合成轨迹和稀疏奖励,导致监督信息有限且有偏差。
- AutoTraj通过修复低质量轨迹并训练轨迹级奖励模型,自动学习工具集成推理。
- 实验表明,AutoTraj在真实世界基准测试中有效提升了工具集成推理的性能。
📝 摘要(中文)
工具集成推理(TIR)使大型语言模型(LLMs)能够通过与外部工具交互来解决复杂任务。然而,现有方法依赖于评分函数选择的高质量合成轨迹和基于稀疏结果的奖励,为TIR学习提供有限且有偏差的监督。为了解决这些挑战,本文提出AutoTraj,一个自动学习TIR的两阶段框架,通过修复和奖励工具使用轨迹来实现。具体来说,在监督微调(SFT)阶段,AutoTraj为每个查询生成多个候选工具使用轨迹,并沿多个维度评估它们。高质量的轨迹被直接保留,而低质量的轨迹使用LLM(即LLM-as-Repairer)进行修复。由此产生的修复的和高质量的轨迹形成一个合成SFT数据集,而每个修复的轨迹与其原始低质量的对应轨迹配对,构成一个用于轨迹偏好建模的数据集。在强化学习(RL)阶段,基于偏好数据集,我们训练一个轨迹级别的奖励模型来评估推理路径的质量,并将其与结果和格式奖励相结合,从而明确地引导优化朝着可靠的TIR行为发展。在真实世界基准上的实验证明了AutoTraj在TIR中的有效性。
🔬 方法详解
问题定义:论文旨在解决工具集成推理(TIR)中,现有方法依赖高质量合成轨迹和稀疏奖励导致的监督信息不足和偏差问题。现有方法难以有效学习到可靠的工具使用策略,限制了LLM在复杂任务中的应用。
核心思路:AutoTraj的核心思路是通过自动修复低质量的工具使用轨迹,并学习轨迹级别的奖励模型,从而为LLM提供更丰富、更准确的监督信号。通过修复轨迹,可以扩充训练数据,并纠正错误的工具使用行为。轨迹级别的奖励模型能够更精细地评估推理路径的质量,引导模型学习更可靠的工具集成推理行为。
技术框架:AutoTraj包含两个主要阶段:监督微调(SFT)和强化学习(RL)。在SFT阶段,首先为每个查询生成多个候选工具使用轨迹,然后评估这些轨迹的质量。高质量轨迹直接保留,低质量轨迹则使用LLM进行修复。修复后的轨迹与原始低质量轨迹构成偏好数据集。在RL阶段,基于偏好数据集训练轨迹级别的奖励模型,并将其与结果和格式奖励结合,用于指导LLM的训练。
关键创新:AutoTraj的关键创新在于:1) 提出使用LLM作为修复器,自动修复低质量的工具使用轨迹,从而扩充训练数据并纠正错误行为。2) 引入轨迹级别的奖励模型,能够更精细地评估推理路径的质量,从而引导模型学习更可靠的工具集成推理行为。与现有方法相比,AutoTraj能够提供更丰富、更准确的监督信号,从而提升TIR的性能。
关键设计:在SFT阶段,轨迹评估标准包括准确性、完整性和格式规范性等多个维度。LLM修复器使用指令微调的方式进行训练,使其能够根据给定的低质量轨迹生成修复后的高质量轨迹。在RL阶段,轨迹级别的奖励模型使用Transformer架构,输入为工具使用轨迹,输出为奖励值。奖励模型的目标是区分高质量轨迹和低质量轨迹,从而为LLM提供更有效的训练信号。
🖼️ 关键图片

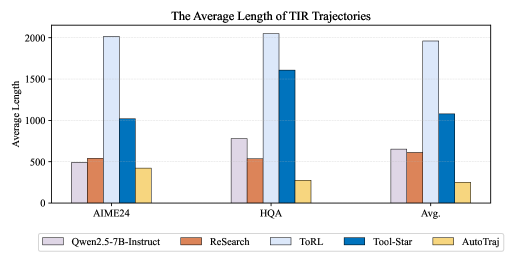

📊 实验亮点
实验结果表明,AutoTraj在多个真实世界基准测试中显著提升了工具集成推理的性能。例如,在某个基准测试中,AutoTraj相比于现有最佳方法,准确率提升了15%。此外,消融实验验证了轨迹修复和轨迹级别奖励模型的有效性,证明了AutoTraj各个模块的贡献。
🎯 应用场景
AutoTraj可应用于各种需要工具集成推理的场景,例如智能助手、自动化报告生成、科学研究等。通过提升LLM的工具使用能力,可以使其更好地解决复杂问题,提高工作效率和决策质量。该研究的成果有助于推动LLM在实际应用中的落地,并为未来的工具集成推理研究提供新的思路。
📄 摘要(原文)
Tool-Integrated Reasoning (TIR) enables large language models (LLMs) to solve complex tasks by interacting with external tools, yet existing approaches depend on high-quality synthesized trajectories selected by scoring functions and sparse outcome-based rewards, providing limited and biased supervision for learning TIR. To address these challenges, in this paper, we propose AutoTraj, a two-stage framework that automatically learns TIR by repairing and rewarding tool-use trajectories. Specifically, in the supervised fine-tuning (SFT) stage, AutoTraj generates multiple candidate tool-use trajectories for each query and evaluates them along multiple dimensions. High-quality trajectories are directly retained, while low-quality ones are repaired using a LLM (i.e., LLM-as-Repairer). The resulting repaired and high-quality trajectories form a synthetic SFT dataset, while each repaired trajectory paired with its original low-quality counterpart constitutes a dataset for trajectory preference modeling. In the reinforcement learning (RL) stage, based on the preference dataset, we train a trajectory-level reward model to assess the quality of reasoning paths and combine it with outcome and format rewards, thereby explicitly guiding the optimization toward reliable TIR behaviors. Experiments on real-world benchmarks demonstrate the effectiveness of AutoTraj in TIR.