Protecting Private Code in IDE Autocomplete using Differential Privacy
作者: Evgeny Grigorenko, David Stanojević, David Ilić, Egor Bogomolov, Kostadin Cvejoski
分类: cs.CR, cs.AI
发布日期: 2026-01-30
备注: 6 pages
💡 一句话要点
利用差分隐私保护IDE代码自动补全中的私有代码
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 代码自动补全 集成开发环境 大型语言模型 隐私保护
📋 核心要点
- 现有IDE的代码自动补全功能依赖于大型语言模型,但直接使用用户代码训练存在隐私泄露风险。
- 论文提出使用差分隐私(DP)来训练代码自动补全的语言模型,以保护用户代码的隐私。
- 实验表明,使用DP训练的模型在提供隐私保护的同时,性能损失很小,甚至在少量数据上也能达到可比效果。
📝 摘要(中文)
现代集成开发环境(IDE)越来越多地利用大型语言模型(LLM)来提供代码自动补全等高级功能。然而,在用户编写的代码上训练这些模型会带来显著的隐私风险,使模型本身成为一种新型的数据漏洞。恶意行为者可以通过发起攻击来重建敏感的训练数据,或推断特定的代码片段是否被用于训练。本文研究了使用差分隐私(DP)作为一种强大的防御机制,用于训练用于Kotlin代码补全的LLM。我们使用DP微调了一个\texttt{Mellum}模型,并对其隐私性和效用进行了全面的评估。结果表明,DP为抵御成员推理攻击(MIA)提供了强大的防御,将攻击的成功率降低到接近随机猜测(AUC从0.901降至0.606)。此外,我们表明,这种隐私保证以最小的模型性能代价为代价,即使在100倍更少的数据上训练,DP训练的模型也能获得与非私有模型相当的效用分数。我们的研究结果表明,DP是构建私有和可信的AI驱动的IDE功能的实用且有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决IDE代码自动补全功能中,使用用户私有代码训练大型语言模型所带来的隐私泄露问题。现有方法缺乏有效的隐私保护机制,容易受到成员推理攻击等隐私攻击,导致敏感代码信息泄露。
核心思路:论文的核心思路是利用差分隐私(DP)技术,在模型训练过程中添加噪声,从而限制模型对训练集中特定样本的记忆能力,防止攻击者通过模型推断出训练数据的信息。通过控制噪声的添加量,在隐私保护和模型效用之间进行权衡。
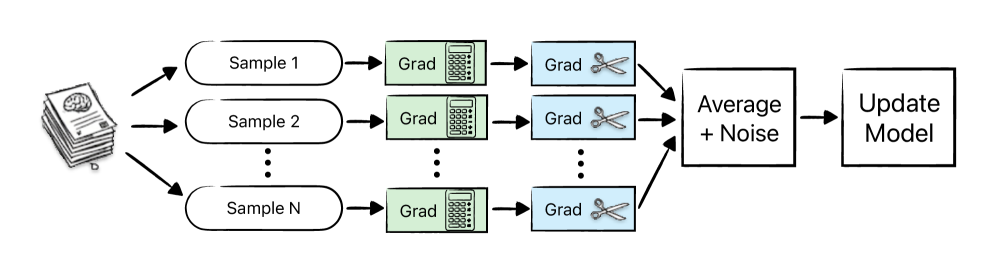
技术框架:论文采用微调(fine-tuning)的方式,在一个预训练的语言模型(\texttt{Mellum})上进行训练。在训练过程中,使用差分隐私随机梯度下降(DP-SGD)算法,对梯度进行裁剪和噪声添加,以保证训练过程的差分隐私性。整体流程包括数据预处理、模型微调、隐私参数设置和模型评估等步骤。
关键创新:论文的关键创新在于将差分隐私技术应用于代码自动补全的语言模型训练中,并证明了在保证隐私性的前提下,模型仍然可以保持较高的实用性。通过实验验证了DP在抵御成员推理攻击方面的有效性,并分析了隐私预算和模型性能之间的关系。
关键设计:论文的关键设计包括:1) 使用DP-SGD算法进行模型训练,需要设置合适的隐私预算(epsilon和delta)和噪声乘数;2) 对梯度进行裁剪,以限制梯度的大小,从而控制噪声的添加量;3) 选择合适的预训练模型(\texttt{Mellum})作为基础模型,并进行微调;4) 使用成员推理攻击(MIA)作为评估隐私性的指标,并使用代码补全的准确率等指标评估模型效用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用差分隐私训练的模型能够有效抵御成员推理攻击,将攻击的AUC从0.901降低到0.606,接近随机猜测水平。同时,该模型在代码自动补全任务上的性能损失很小,即使在100倍更少的数据上训练,也能达到与非私有模型相当的效用分数。这表明差分隐私是一种在隐私保护和模型效用之间取得良好平衡的有效方法。
🎯 应用场景
该研究成果可应用于各种需要保护用户代码隐私的IDE和代码自动补全工具中。通过使用差分隐私技术,可以构建更加安全和可信的AI驱动的开发工具,提升用户对代码自动补全功能的信任度,并促进更广泛的应用。此外,该方法也可以推广到其他涉及敏感数据处理的机器学习任务中,例如医疗数据分析和金融风险评估等。
📄 摘要(原文)
Modern Integrated Development Environments (IDEs) increasingly leverage Large Language Models (LLMs) to provide advanced features like code autocomplete. While powerful, training these models on user-written code introduces significant privacy risks, making the models themselves a new type of data vulnerability. Malicious actors can exploit this by launching attacks to reconstruct sensitive training data or infer whether a specific code snippet was used for training. This paper investigates the use of Differential Privacy (DP) as a robust defense mechanism for training an LLM for Kotlin code completion. We fine-tune a \texttt{Mellum} model using DP and conduct a comprehensive evaluation of its privacy and utility. Our results demonstrate that DP provides a strong defense against Membership Inference Attacks (MIAs), reducing the attack's success rate close to a random guess (AUC from 0.901 to 0.606). Furthermore, we show that this privacy guarantee comes at a minimal cost to model performance, with the DP-trained model achieving utility scores comparable to its non-private counterpart, even when trained on 100x less data. Our findings suggest that DP is a practical and effective solution for building private and trustworthy AI-powered IDE features.