Eroding the Truth-Default: A Causal Analysis of Human Susceptibility to Foundation Model Hallucinations and Disinformation in the Wild
作者: Alexander Loth, Martin Kappes, Marc-Oliver Pahl
分类: cs.CY, cs.AI, cs.CL, cs.HC
发布日期: 2026-01-30
备注: Accepted at ACM TheWebConf '26 Companion
💡 一句话要点
提出JudgeGPT和RogueGPT双轴框架,分析人类对大型模型幻觉和虚假信息的易感性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型模型 虚假信息检测 因果分析 人类易感性 来源监控 认知偏差 信息生态系统
📋 核心要点
- 现有方法难以区分大型模型生成的虚假信息,对网络信息生态构成威胁。
- 论文提出JudgeGPT和RogueGPT双轴框架,解耦真实性与归因,分析人类易感性。
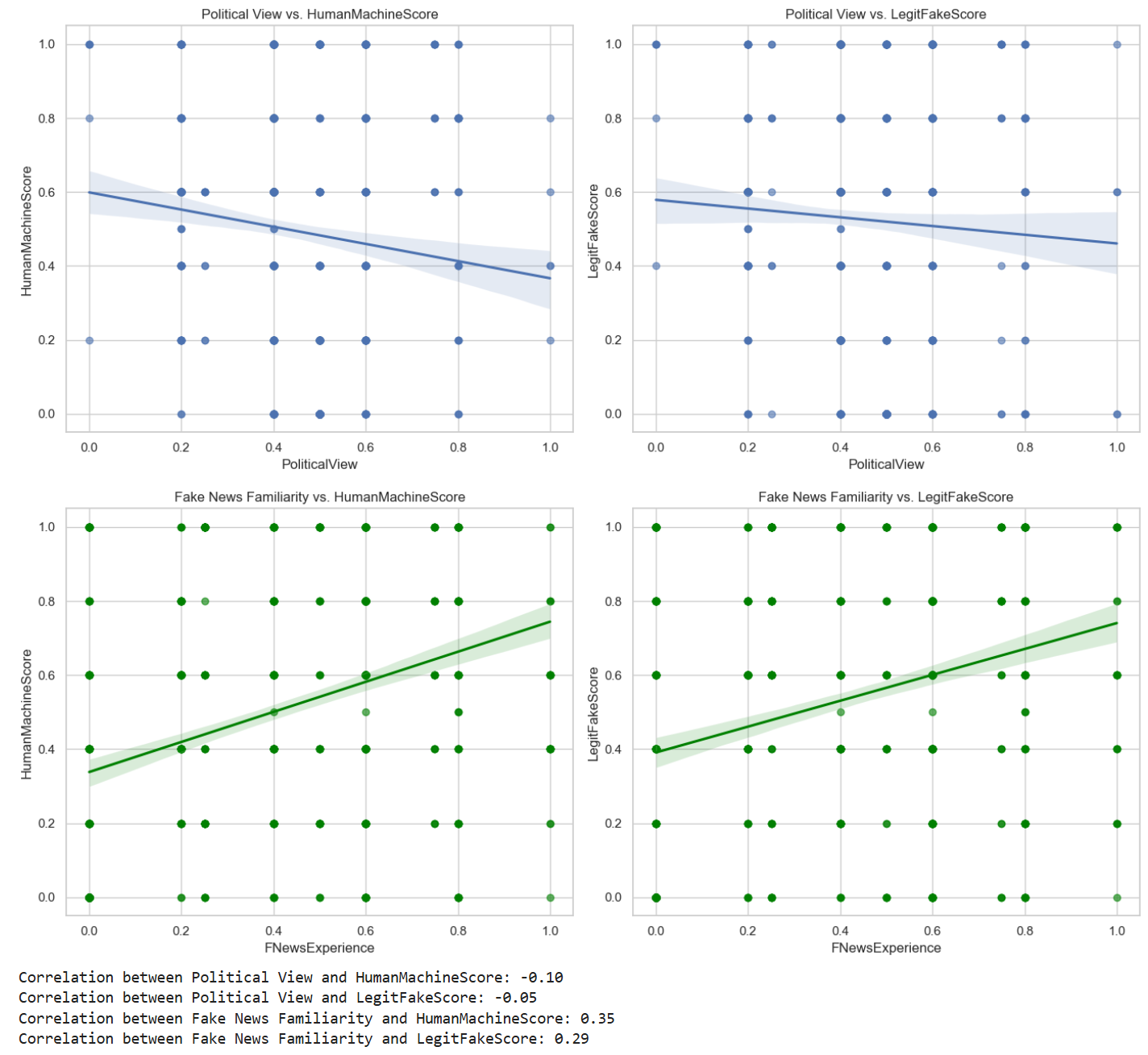
- 实验表明政治倾向影响不大,假新闻熟悉度是关键因素,GPT-4流畅性构成“陷阱”。
📝 摘要(中文)
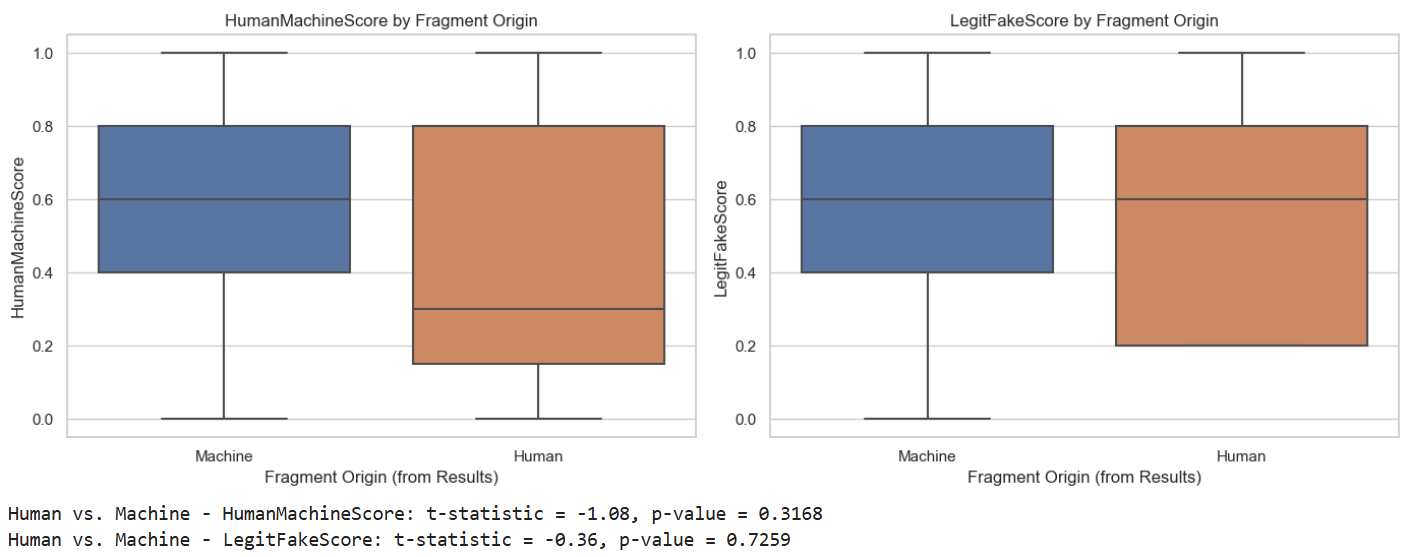
随着大型模型(FMs)在流畅性上接近人类水平,区分合成内容和自然内容已成为可信网络智能的关键挑战。本文提出了JudgeGPT和RogueGPT,一个双轴框架,将“真实性”与“归因”解耦,以研究人类易感性的机制。通过分析五个大型模型(包括GPT-4和Llama-2)的918个评估,我们采用结构因果模型(SCMs)作为主要框架,用于制定关于检测准确性的可测试因果假设。与党派叙事相反,我们发现政治倾向与检测性能的相关性可以忽略不计(r=-0.10)。相反,“假新闻熟悉度”成为一个候选的中介(r=0.35),表明接触可能作为人类鉴别器的对抗训练。我们发现了一个“流畅性陷阱”,其中GPT-4的输出(HumanMachineScore: 0.20)绕过了来源监控机制,使其与人类文本无法区分。这些发现表明,“预先揭穿”干预措施应针对认知来源监控,而不是人口统计细分,以确保可信的信息生态系统。
🔬 方法详解
问题定义:论文旨在解决人类难以区分大型模型(如GPT-4)生成的虚假信息的问题。现有方法的痛点在于,它们无法有效解释人类对不同类型虚假信息的易感性差异,也难以区分内容本身的真实性与来源的可信度。
核心思路:论文的核心思路是将“真实性”与“归因”解耦,通过JudgeGPT评估内容真实性,RogueGPT评估内容来源可信度,从而更细致地分析人类的判断过程。这种解耦允许研究人员独立地操纵和评估这两个因素对人类判断的影响。
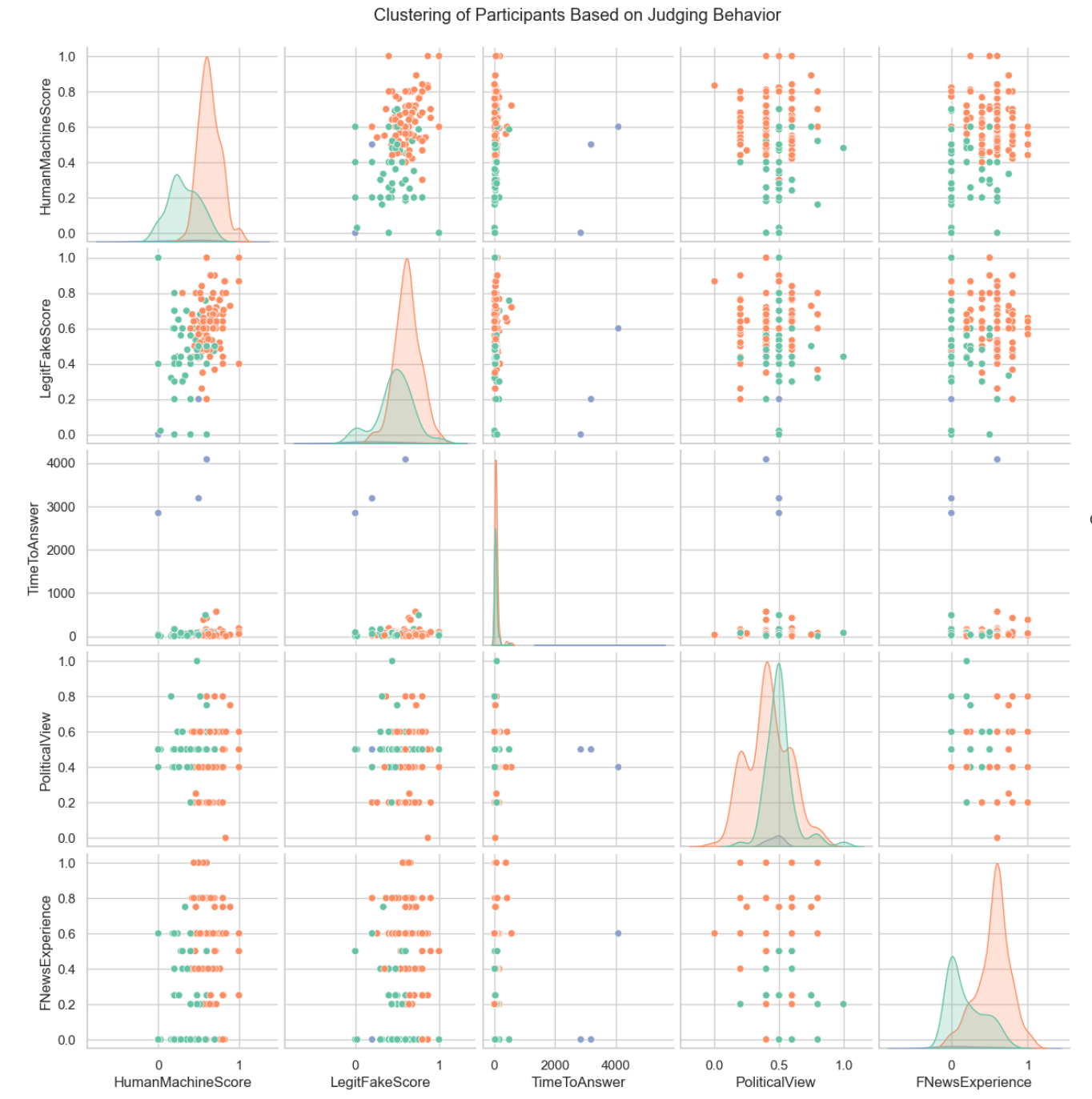
技术框架:论文采用JudgeGPT和RogueGPT双轴框架。JudgeGPT负责生成不同真实度的文本,RogueGPT负责模拟不同可信度的信息来源。然后,通过实验收集人类对这些文本的判断,并使用结构因果模型(SCMs)分析影响判断准确性的因素。整体流程包括:1) 使用JudgeGPT和RogueGPT生成文本;2) 收集人类对文本真实性和来源的判断;3) 构建SCMs模型,分析因果关系。
关键创新:论文最重要的技术创新点在于提出了JudgeGPT和RogueGPT双轴框架,将真实性与归因解耦。这与现有方法不同,现有方法通常将两者混为一谈,难以深入理解人类判断虚假信息的机制。此外,使用SCMs进行因果分析,能够更准确地识别影响人类判断的关键因素。
关键设计:论文的关键设计包括:1) JudgeGPT和RogueGPT的prompt设计,确保生成的文本在真实性和来源可信度上具有可控的差异;2) 实验参与者的招募和筛选,确保样本的多样性和代表性;3) SCMs模型的构建和验证,确保模型的准确性和可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,政治倾向与虚假信息检测性能关联不大(r=-0.10),而“假新闻熟悉度”是更重要的影响因素(r=0.35)。GPT-4生成的文本由于其高流畅性,更容易绕过人类的来源监控机制(HumanMachineScore: 0.20),使其难以与人类文本区分。这些发现强调了针对认知来源监控的干预措施的重要性。
🎯 应用场景
该研究成果可应用于开发更有效的虚假信息检测工具和预警系统,提升公众对AI生成内容的辨别能力。通过针对认知来源监控的干预措施,可以构建更值得信赖的信息生态系统,减少虚假信息对社会的影响。此外,该框架可用于评估不同大型模型生成内容的欺骗性,指导模型开发者提升模型的安全性。
📄 摘要(原文)
As foundation models (FMs) approach human-level fluency, distinguishing synthetic from organic content has become a key challenge for Trustworthy Web Intelligence. This paper presents JudgeGPT and RogueGPT, a dual-axis framework that decouples "authenticity" from "attribution" to investigate the mechanisms of human susceptibility. Analyzing 918 evaluations across five FMs (including GPT-4 and Llama-2), we employ Structural Causal Models (SCMs) as a principal framework for formulating testable causal hypotheses about detection accuracy. Contrary to partisan narratives, we find that political orientation shows a negligible association with detection performance ($r=-0.10$). Instead, "fake news familiarity" emerges as a candidate mediator ($r=0.35$), suggesting that exposure may function as adversarial training for human discriminators. We identify a "fluency trap" where GPT-4 outputs (HumanMachineScore: 0.20) bypass Source Monitoring mechanisms, rendering them indistinguishable from human text. These findings suggest that "pre-bunking" interventions should target cognitive source monitoring rather than demographic segmentation to ensure trustworthy information ecosystems.