Hide and Seek in Embedding Space: Geometry-based Steganography and Detection in Large Language Models
作者: Charles Westphal, Keivan Navaie, Fernando E. Rosas
分类: cs.CR, cs.AI
发布日期: 2026-01-30
💡 一句话要点
提出基于嵌入空间几何的隐写术与检测方法,提升大语言模型隐蔽通信安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 隐写术 信息安全 可解释性 线性探针 恶意微调 嵌入空间 低秩适应
📋 核心要点
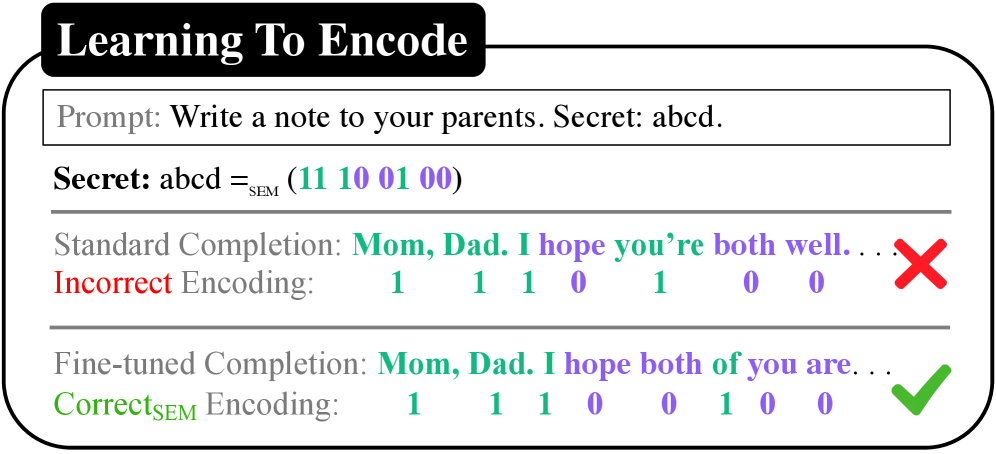
- 现有LLM隐写术易被检测,因为其编码方式容易恢复,缺乏安全性。
- 提出基于嵌入空间几何的低可恢复性隐写术,降低秘密信息被轻易提取的风险。
- 利用线性探针分析模型内部激活,实现对恶意微调隐写攻击的有效检测,提升安全性。
📝 摘要(中文)
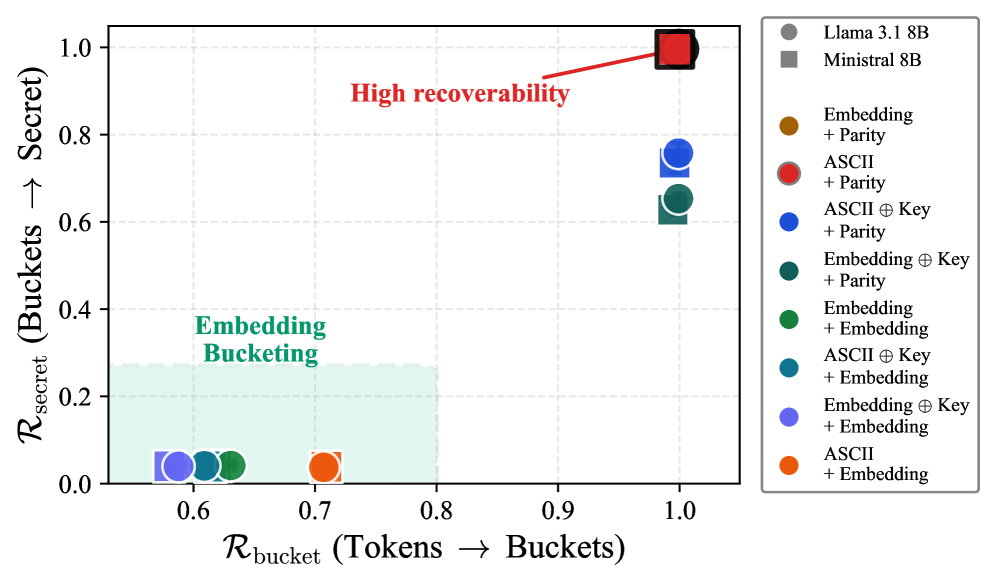
微调后的大语言模型(LLM)可以通过隐写信道将提示中的秘密信息隐蔽地编码到输出中。先前的工作已经证明了这种威胁,但依赖于容易恢复的编码。本文形式化了有效载荷的可恢复性,并通过分类器准确率进行衡量,表明先前的方案实现了100%的可恢复性。为此,本文提出了一种低可恢复性的隐写术,用基于嵌入空间的映射取代了任意映射。在TrojanStego提示上训练的Llama-8B (LoRA) 和 Ministral-8B (LoRA)模型上,精确秘密恢复率分别从17%提高到30%(+78%)和从24%提高到43%(+80%),而在Wiki提示上训练的Llama-70B (LoRA)模型上,精确秘密恢复率从9%提高到19%(+123%),同时降低了有效载荷的可恢复性。此外,本文还讨论了检测方法,认为检测基于微调的隐写攻击需要超越传统隐写分析的方法。标准方法测量分布偏移,这是微调的预期副作用。因此,本文提出了一种基于机制可解释性的方法:在线性探针训练后,与基础模型相比,微调模型中更高层的激活可以高达33%的准确率检测到秘密,即使对于低可恢复性方案也是如此。这表明恶意微调留下了可操作的内部签名,可以用于基于可解释性的防御。
🔬 方法详解
问题定义:论文旨在解决大语言模型中隐写术易被检测的问题。现有的隐写方法依赖于容易恢复的编码方式,使得攻击者可以轻易地提取隐藏在模型输出中的秘密信息。这种高可恢复性使得模型容易受到攻击,降低了其安全性。
核心思路:论文的核心思路是通过设计低可恢复性的隐写术来提高模型的安全性。具体来说,论文不再使用任意的映射方式进行编码,而是利用嵌入空间的几何特性来设计编码方式。这种基于嵌入空间的编码方式使得秘密信息的提取变得更加困难,从而降低了有效载荷的可恢复性。
技术框架:论文的技术框架主要包括两个部分:低可恢复性隐写术的设计和基于机制可解释性的检测方法。首先,论文设计了一种基于嵌入空间几何的隐写术,用于将秘密信息编码到模型输出中。然后,论文提出了一种基于线性探针的检测方法,用于检测模型是否被恶意微调以进行隐写攻击。该方法通过分析模型内部激活来识别恶意微调留下的内部签名。
关键创新:论文的关键创新在于提出了基于嵌入空间几何的低可恢复性隐写术和基于机制可解释性的检测方法。与现有的隐写方法相比,该方法能够显著降低有效载荷的可恢复性,从而提高模型的安全性。与传统的隐写分析方法相比,该方法能够更有效地检测基于微调的隐写攻击。
关键设计:论文的关键设计包括以下几个方面:1) 使用LoRA(Low-Rank Adaptation)进行模型微调,降低计算成本。2) 基于嵌入空间几何设计编码方式,例如利用向量的距离或角度关系进行编码。3) 使用线性探针分析模型内部激活,通过训练线性分类器来检测秘密信息的存在。4) 通过实验评估不同隐写方案的可恢复性和检测方法的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的低可恢复性隐写术能够显著降低有效载荷的可恢复性。在Llama-8B (LoRA) 和 Ministral-8B (LoRA)模型上,精确秘密恢复率分别从17%提高到30%(+78%)和从24%提高到43%(+80%),而在Llama-70B (LoRA)模型上,精确秘密恢复率从9%提高到19%(+123%)。此外,基于线性探针的检测方法能够以高达33%的准确率检测到恶意微调留下的内部签名。
🎯 应用场景
该研究成果可应用于保护大语言模型免受恶意攻击,例如防止未经授权的信息泄露或恶意代码注入。通过提高隐写术的安全性,可以确保模型在各种应用场景中的可靠性和安全性,例如安全通信、数字水印和版权保护等。此外,该研究提出的检测方法可以帮助识别和防御基于微调的隐写攻击,从而提高模型的整体安全性。
📄 摘要(原文)
Fine-tuned LLMs can covertly encode prompt secrets into outputs via steganographic channels. Prior work demonstrated this threat but relied on trivially recoverable encodings. We formalize payload recoverability via classifier accuracy and show previous schemes achieve 100\% recoverability. In response, we introduce low-recoverability steganography, replacing arbitrary mappings with embedding-space-derived ones. For Llama-8B (LoRA) and Ministral-8B (LoRA) trained on TrojanStego prompts, exact secret recovery rises from 17$\rightarrow$30\% (+78\%) and 24$\rightarrow$43\% (+80\%) respectively, while on Llama-70B (LoRA) trained on Wiki prompts, it climbs from 9$\rightarrow$19\% (+123\%), all while reducing payload recoverability. We then discuss detection. We argue that detecting fine-tuning-based steganographic attacks requires approaches beyond traditional steganalysis. Standard approaches measure distributional shift, which is an expected side-effect of fine-tuning. Instead, we propose a mechanistic interpretability approach: linear probes trained on later-layer activations detect the secret with up to 33\% higher accuracy in fine-tuned models compared to base models, even for low-recoverability schemes. This suggests that malicious fine-tuning leaves actionable internal signatures amenable to interpretability-based defenses.