CVeDRL: An Efficient Code Verifier via Difficulty-aware Reinforcement Learning
作者: Ji Shi, Peiming Guo, Meishan Zhang, Miao Zhang, Xuebo Liu, Min Zhang, Weili Guan
分类: cs.AI, cs.SE
发布日期: 2026-01-30
备注: 17 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出CVeDRL:一种基于难度感知强化学习的高效代码验证器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 代码验证 强化学习 单元测试生成 难度感知 奖励塑造
📋 核心要点
- 现有代码验证的监督微调方法受限于数据不足、验证失败率高以及推理效率低下等问题。
- 论文提出一种难度感知的强化学习方法CVeDRL,通过设计语法和功能感知的奖励,并结合分支和样本难度信息来优化模型。
- 实验结果表明,CVeDRL在代码验证任务上取得了显著提升,在通过率和分支覆盖率上均优于GPT-3.5,并大幅提升了推理速度。
📝 摘要(中文)
代码验证器在基于LLM的代码生成后验证中起着关键作用,但现有的监督微调方法面临数据稀缺、高失败率和推理效率低下的问题。强化学习(RL)通过执行驱动的奖励来优化模型,无需标签监督,提供了一种有前景的替代方案。然而,初步结果表明,仅使用功能奖励的朴素RL无法为困难的分支和样本生成有效的单元测试。本文首先从理论上分析了分支覆盖率、样本难度、语法和功能正确性可以联合建模为RL奖励,优化这些信号可以提高基于单元测试的验证的可靠性。在此分析的指导下,我们设计了语法和功能感知的奖励,并进一步提出了使用指数奖励塑造和静态分析指标的分支和样本难度感知的RL方法。通过这种公式化,CVeDRL仅使用0.6B参数就实现了最先进的性能,与GPT-3.5相比,通过率提高了28.97%,分支覆盖率提高了15.08%,同时提供了比竞争基线快20倍以上的推理速度。代码可在https://github.com/LIGHTCHASER1/CVeDRL.git 获取。
🔬 方法详解
问题定义:现有基于LLM的代码生成后验证依赖代码验证器,但现有监督微调的代码验证方法存在数据稀缺,验证失败率高,推理效率低的问题。如何提升代码验证的准确性和效率是一个关键问题。
核心思路:论文的核心思路是将代码验证问题建模为强化学习任务,并设计合适的奖励函数来指导模型的学习。通过奖励函数来衡量代码的语法正确性、功能正确性、分支覆盖率以及样本难度,从而使模型能够生成更有效的单元测试,提高代码验证的可靠性。
技术框架:CVeDRL的整体框架包括以下几个主要部分:1) 代码生成器:用于生成待验证的代码片段。2) 强化学习Agent:负责生成单元测试,并根据执行结果获得奖励。3) 奖励函数:用于评估生成的单元测试的质量,包括语法奖励、功能奖励、分支覆盖奖励和难度奖励。4) 执行环境:用于执行生成的单元测试,并返回执行结果。
关键创新:论文的关键创新在于提出了难度感知的强化学习方法。具体来说,论文通过静态分析指标来估计分支和样本的难度,并根据难度调整奖励函数,从而使模型能够更加关注困难的分支和样本,提高代码验证的覆盖率和准确性。此外,论文还设计了语法和功能感知的奖励函数,从而使模型能够生成更符合语法和语义规则的单元测试。
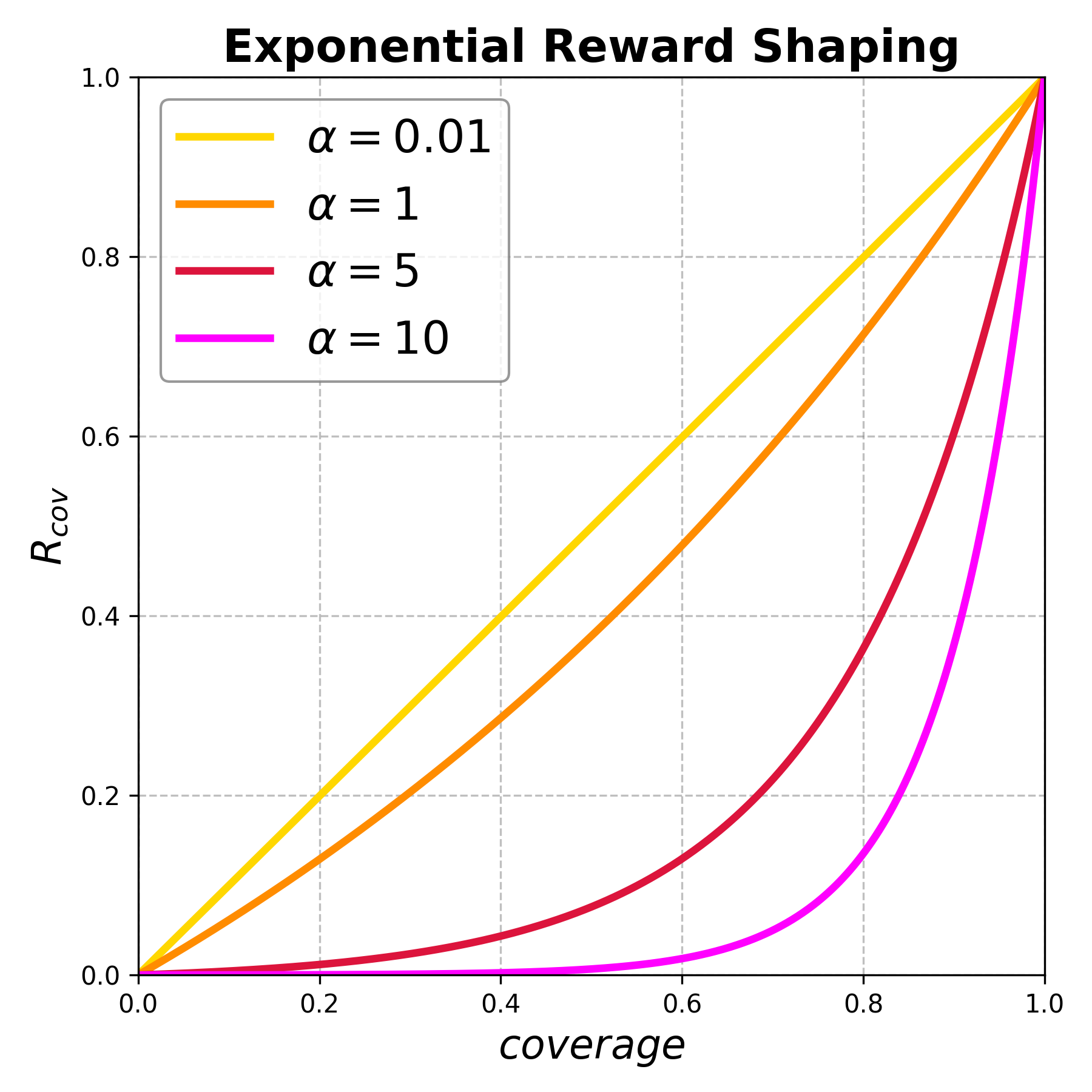
关键设计:论文使用了指数奖励塑造来平衡不同奖励信号的贡献。具体来说,对于每个奖励信号,论文都定义了一个指数函数,用于将奖励值映射到[0, 1]区间。此外,论文还使用了静态分析指标,如循环复杂度、嵌套深度等,来估计分支和样本的难度。在网络结构方面,论文采用了Transformer模型作为强化学习Agent,并使用策略梯度算法进行训练。
🖼️ 关键图片


📊 实验亮点
CVeDRL在代码验证任务上取得了显著的性能提升。实验结果表明,与GPT-3.5相比,CVeDRL的通过率提高了28.97%,分支覆盖率提高了15.08%。此外,CVeDRL的推理速度比竞争基线快20倍以上,具有很高的实用价值。这些结果表明,难度感知的强化学习方法在代码验证任务上具有很大的潜力。
🎯 应用场景
CVeDRL可应用于各种软件开发场景,例如自动化测试、代码审查和程序调试。通过自动生成高质量的单元测试,CVeDRL可以帮助开发人员更有效地发现和修复代码中的错误,提高软件的质量和可靠性。此外,CVeDRL还可以用于评估代码生成模型的性能,并指导模型的改进。
📄 摘要(原文)
Code verifiers play a critical role in post-verification for LLM-based code generation, yet existing supervised fine-tuning methods suffer from data scarcity, high failure rates, and poor inference efficiency. While reinforcement learning (RL) offers a promising alternative by optimizing models through execution-driven rewards without labeled supervision, our preliminary results show that naive RL with only functionality rewards fails to generate effective unit tests for difficult branches and samples. We first theoretically analyze showing that branch coverage, sample difficulty, syntactic and functional correctness can be jointly modeled as RL rewards, where optimizing these signals can improve the reliability of unit-test-based verification. Guided by this analysis, we design syntax- and functionality-aware rewards and further propose branch- and sample-difficulty--aware RL using exponential reward shaping and static analysis metrics. With this formulation, CVeDRL achieves state-of-the-art performance with only 0.6B parameters, yielding up to 28.97% higher pass rate and 15.08% higher branch coverage than GPT-3.5, while delivering over $20\times$ faster inference than competitive baselines. Code is available at https://github.com/LIGHTCHASER1/CVeDRL.git