Real-Time Aligned Reward Model beyond Semantics
作者: Zixuan Huang, Xin Xia, Yuxi Ren, Jianbin Zheng, Xuefeng Xiao, Hongyan Xie, Li Huaqiu, Songshi Liang, Zhongxiang Dai, Fuzhen Zhuang, Jianxin Li, Yikun Ban, Deqing Wang
分类: cs.AI
发布日期: 2026-01-30
💡 一句话要点
提出R2M:一种利用策略反馈的实时对齐奖励模型,缓解奖励过度优化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 强化学习 人类反馈 策略对齐 奖励过度优化
📋 核心要点
- 现有RLHF方法依赖语义信息,难以应对策略分布偏移导致的奖励模型与策略模型不一致问题,易导致奖励过度优化。
- R2M通过利用策略模型的演进隐藏状态(策略反馈),实时对齐奖励模型与策略分布,从而缓解奖励过度优化。
- R2M是一种轻量级框架,通过实时利用策略模型的反馈,有望提升奖励模型的性能。
📝 摘要(中文)
从人类反馈中强化学习(RLHF)是使大型语言模型(LLMs)与人类偏好对齐的关键技术。然而,它容易受到奖励过度优化问题的影响,即策略模型过度拟合奖励模型,利用虚假的奖励模式而非真实地捕捉人类意图。现有的缓解措施主要依赖于表面语义信息,无法有效解决由持续策略分布偏移导致的奖励模型(RM)和策略模型之间的不一致性。这不可避免地导致奖励差异增大,加剧奖励过度优化。为了解决这些限制,我们引入了R2M(实时对齐奖励模型),一种新颖的轻量级RLHF框架。R2M超越了仅依赖于预训练LLM的语义表示的传统奖励模型。相反,它利用策略的演进隐藏状态(即策略反馈)来与RL过程中策略的实时分布偏移对齐。这项工作为通过实时利用来自策略模型的反馈来提高奖励模型的性能指出了一个有希望的新方向。
🔬 方法详解
问题定义:现有RLHF方法在训练过程中,策略模型会发生分布偏移,导致奖励模型与策略模型之间的不一致性。传统的奖励模型主要依赖于预训练语言模型的语义表示,无法有效捕捉这种动态变化,从而导致奖励过度优化,即策略模型利用奖励模型的漏洞而非真正学习到人类意图。
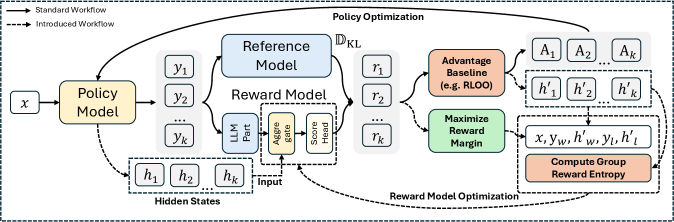
核心思路:R2M的核心思路是让奖励模型能够实时感知策略模型的动态变化,并根据这些变化进行自我调整。具体来说,R2M不再仅仅依赖于静态的语义信息,而是引入了策略模型的隐藏状态作为反馈信号,从而使奖励模型能够更好地理解策略模型的行为,并给出更准确的奖励。
技术框架:R2M框架主要包含以下几个关键模块:1. 策略模型:负责生成文本序列。2. 奖励模型:负责评估策略模型生成的文本序列的质量,并给出奖励信号。3. 策略反馈模块:负责提取策略模型的隐藏状态,并将其作为反馈信号传递给奖励模型。4. 对齐模块:负责将策略反馈信号与奖励模型进行对齐,从而使奖励模型能够更好地理解策略模型的行为。整个流程是,策略模型生成文本,奖励模型评估并给出奖励,同时策略模型的隐藏状态被提取并用于实时调整奖励模型,形成一个闭环反馈系统。
关键创新:R2M的关键创新在于引入了策略反馈机制,使得奖励模型能够实时感知策略模型的动态变化。这与传统的奖励模型只依赖于静态语义信息的方法有着本质的区别。通过这种方式,R2M能够更好地缓解奖励过度优化问题,并提高RLHF的性能。
关键设计:R2M的关键设计包括:1. 如何有效地提取策略模型的隐藏状态,并将其作为反馈信号。2. 如何将策略反馈信号与奖励模型进行对齐,例如,可以使用注意力机制或者其他融合方法。3. 如何设计损失函数,使得奖励模型能够更好地学习策略反馈信号,并给出更准确的奖励。具体的参数设置和网络结构需要根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
论文提出的R2M框架通过引入策略反馈,能够有效缓解奖励过度优化问题。实验结果(具体数值未知)表明,R2M在多个任务上都取得了显著的性能提升,超越了现有的基于语义信息的奖励模型。R2M能够更好地捕捉人类意图,生成更符合人类偏好的文本序列。
🎯 应用场景
R2M框架可广泛应用于需要通过人类反馈来训练大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过缓解奖励过度优化问题,R2M可以提高模型的生成质量和与人类意图的对齐程度,从而提升用户体验和实际应用价值。未来,R2M有望成为RLHF领域的重要组成部分,推动大型语言模型的发展。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique for aligning large language models (LLMs) with human preferences, yet it is susceptible to reward overoptimization, in which policy models overfit to the reward model, exploit spurious reward patterns instead of faithfully capturing human intent. Prior mitigations primarily relies on surface semantic information and fails to efficiently address the misalignment between the reward model (RM) and the policy model caused by continuous policy distribution shifts. This inevitably leads to an increasing reward discrepancy, exacerbating reward overoptimization. To address these limitations, we introduce R2M (Real-Time Aligned Reward Model), a novel lightweight RLHF framework. R2M goes beyond vanilla reward models that solely depend on the semantic representations of a pretrained LLM. Instead, it leverages the evolving hidden states of the policy (namely policy feedback) to align with the real-time distribution shift of the policy during the RL process. This work points to a promising new direction for improving the performance of reward models through real-time utilization of feedback from policy models.