UCPO: Uncertainty-Aware Policy Optimization
作者: Xianzhou Zeng, Jing Huang, Chunmei Xie, Gongrui Nan, Siye Chen, Mengyu Lu, Weiqi Xiong, Qixuan Zhou, Junhao Zhang, Qiang Zhu, Yadong Li, Xingzhong Xu
分类: cs.AI, cs.LG
发布日期: 2026-01-30
💡 一句话要点
提出UCPO框架,解决LLM中基于不确定性的强化学习策略优化中的偏差问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性感知 强化学习 策略优化 优势偏差
📋 核心要点
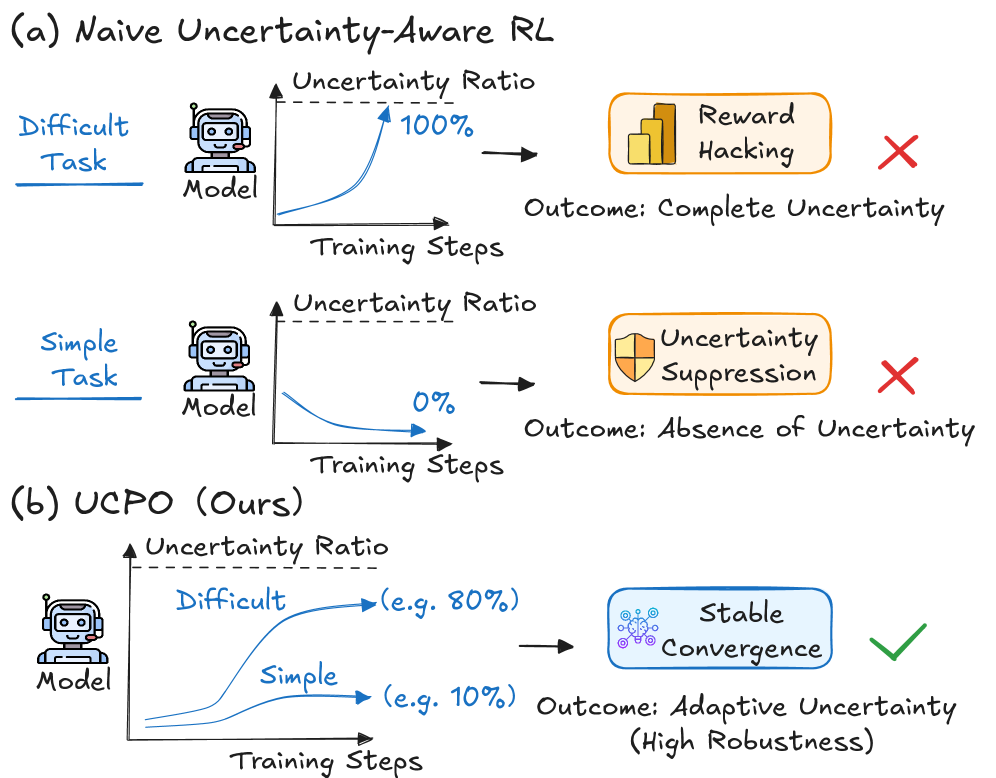
- 现有基于不确定性奖励的强化学习方法存在优势偏差,导致LLM过度保守或过度自信。
- UCPO框架通过三元优势解耦和动态不确定性奖励调整来消除优势偏差,提升模型校准。
- 实验表明,UCPO能有效解决奖励不平衡问题,显著提高LLM在知识边界外的可靠性。
📝 摘要(中文)
构建可信赖的大型语言模型(LLM)的关键在于赋予它们内在的不确定性表达能力,以减轻限制其在高风险应用中幻觉问题。然而,现有的强化学习范式,如GRPO,常常由于二元决策空间和静态不确定性奖励而遭受优势偏差,导致过度保守或过度自信。为了应对这一挑战,本文揭示了当前结合基于不确定性奖励的强化学习范式中奖励利用和过度自信的根本原因,并在此基础上提出了不确定性感知策略优化(UCPO)框架。UCPO采用三元优势解耦来分离和独立地归一化确定性和不确定性rollout,从而消除优势偏差。此外,引入了一种动态不确定性奖励调整机制,以根据模型演化和实例难度实时校准不确定性权重。在数学推理和通用任务中的实验结果表明,UCPO有效地解决了奖励不平衡问题,显著提高了模型在知识边界之外的可靠性和校准。
🔬 方法详解
问题定义:现有基于不确定性的强化学习方法,例如GRPO,在训练LLM时,由于二元决策空间和静态的不确定性奖励,容易产生优势偏差(Advantage Bias)。这种偏差会导致模型在不确定性较高的情况下过度保守,或者在应该不确定的情况下过度自信,从而影响LLM的可靠性和校准能力。
核心思路:UCPO的核心思路是通过解耦确定性和不确定性的rollout,并动态调整不确定性奖励,来消除优势偏差。具体来说,UCPO将rollout分为确定性、不确定性两部分,分别进行归一化,避免了二元决策空间带来的偏差。同时,根据模型训练的进展和实例的难度,动态调整不确定性奖励的权重,使得模型能够更好地学习不确定性表达。
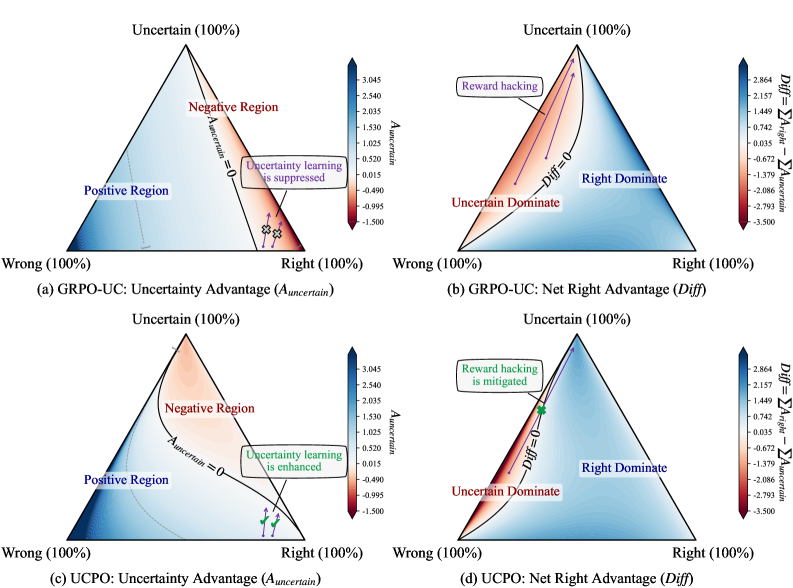
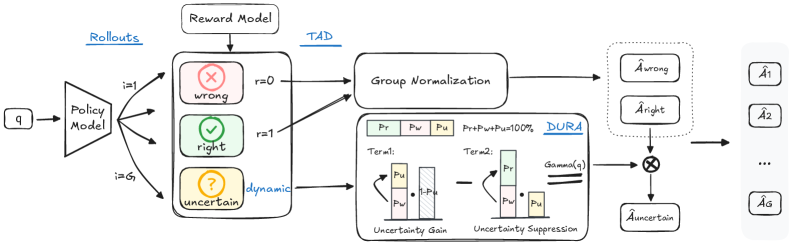
技术框架:UCPO框架主要包含两个核心模块:三元优势解耦(Ternary Advantage Decoupling)和动态不确定性奖励调整(Dynamic Uncertainty Reward Adjustment)。三元优势解耦负责将rollout数据分为确定性、不确定性两部分,并分别计算优势函数。动态不确定性奖励调整模块则根据模型训练状态和实例难度,动态调整不确定性奖励的权重。整体流程是:首先,模型进行rollout,生成训练数据;然后,三元优势解耦模块对数据进行处理,计算优势函数;接着,动态不确定性奖励调整模块调整不确定性奖励的权重;最后,使用调整后的奖励和优势函数来更新模型。
关键创新:UCPO的关键创新在于:1)提出了三元优势解耦,有效地分离了确定性和不确定性的rollout,避免了二元决策空间带来的优势偏差;2)引入了动态不确定性奖励调整机制,能够根据模型训练状态和实例难度,动态调整不确定性奖励的权重,使得模型能够更好地学习不确定性表达。与现有方法相比,UCPO能够更有效地消除优势偏差,提高LLM的可靠性和校准能力。
关键设计:三元优势解耦的关键在于如何区分确定性和不确定性的rollout。论文中可能使用了某种阈值或者概率分布来区分。动态不确定性奖励调整的关键在于如何设计调整策略。论文中可能使用了某种函数或者神经网络来根据模型训练状态和实例难度来计算调整权重。具体的损失函数和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
实验结果表明,UCPO在数学推理和通用任务中均取得了显著的性能提升。具体来说,UCPO能够有效地解决奖励不平衡问题,显著提高了模型在知识边界之外的可靠性和校准能力。相较于现有方法,UCPO在各项指标上均有明显优势,证明了其有效性和优越性。
🎯 应用场景
UCPO框架可应用于各种需要高可靠性和准确性的LLM应用场景,例如医疗诊断、金融分析、法律咨询等。通过提高LLM在知识边界之外的可靠性和校准能力,UCPO可以帮助LLM更好地处理不确定性信息,从而做出更明智的决策,降低出错风险,提升用户信任度。
📄 摘要(原文)
The key to building trustworthy Large Language Models (LLMs) lies in endowing them with inherent uncertainty expression capabilities to mitigate the hallucinations that restrict their high-stakes applications. However, existing RL paradigms such as GRPO often suffer from Advantage Bias due to binary decision spaces and static uncertainty rewards, inducing either excessive conservatism or overconfidence. To tackle this challenge, this paper unveils the root causes of reward hacking and overconfidence in current RL paradigms incorporating uncertainty-based rewards, based on which we propose the UnCertainty-Aware Policy Optimization (UCPO) framework. UCPO employs Ternary Advantage Decoupling to separate and independently normalize deterministic and uncertain rollouts, thereby eliminating advantage bias. Furthermore, a Dynamic Uncertainty Reward Adjustment mechanism is introduced to calibrate uncertainty weights in real-time according to model evolution and instance difficulty. Experimental results in mathematical reasoning and general tasks demonstrate that UCPO effectively resolves the reward imbalance, significantly improving the reliability and calibration of the model beyond their knowledge boundaries.