Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling
作者: Mingqian Feng, Xiaodong Liu, Weiwei Yang, Chenliang Xu, Christopher White, Jianfeng Gao
分类: cs.AI
发布日期: 2026-01-30
💡 一句话要点
提出SABER方法,通过小样本量预测大规模语言模型在Best-of-N采样下的对抗风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗风险 安全评估 Best-of-N采样 统计估计
📋 核心要点
- 现有LLM安全评估方法主要依赖于单次或低成本对抗提示,无法准确反映实际攻击场景下大规模采样带来的风险。
- SABER方法利用Beta分布建模样本成功概率,推导解析缩放律,从小样本量测量中预测大规模采样下的攻击成功率。
- 实验表明,SABER仅用100个样本即可有效预测ASR@1000,误差相比基线降低86.2%,揭示了模型在并行对抗压力下的非线性风险放大现象。
📝 摘要(中文)
大型语言模型(LLM)的安全评估通常采用单次或低成本的对抗性提示,这低估了实际风险。在实践中,攻击者可以通过大规模并行采样来重复探测模型,直到产生有害响应。虽然最近的研究表明,攻击成功率随着重复采样而增加,但预测大规模对抗风险的有效方法仍然有限。我们提出了一种可感知规模的Best-of-N风险估计方法,即SABER,用于建模Best-of-N采样下的越狱漏洞。我们使用Beta分布(伯努利分布的共轭先验)来建模样本级别的成功概率,并推导出一种解析缩放律,该定律能够从小预算测量中可靠地推断出大规模N的攻击成功率。仅使用n=100个样本,我们的锚定估计器预测ASR@1000的平均绝对误差为1.66,而基线的平均绝对误差为12.04,估计误差降低了86.2%。我们的结果揭示了异构的风险缩放曲线,并表明在标准评估下看似稳健的模型在并行对抗压力下可能会经历快速的非线性风险放大。这项工作提供了一种低成本、可扩展的方法,用于现实的LLM安全评估。我们将在发布后发布我们的代码和评估脚本,以供未来研究使用。
🔬 方法详解
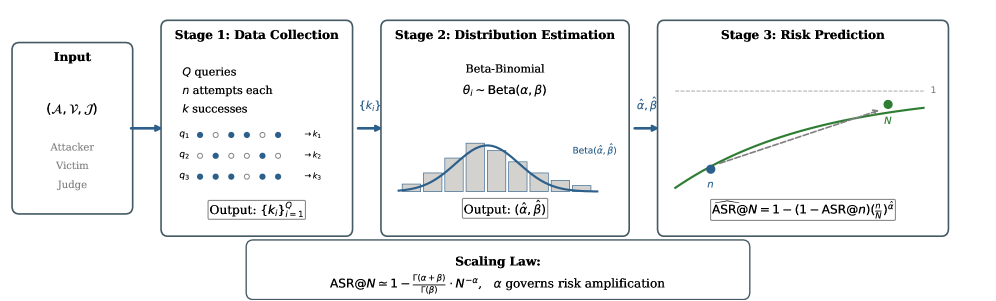
问题定义:论文旨在解决LLM安全评估中,现有方法无法准确预测大规模采样攻击下的对抗风险的问题。现有方法通常采用单次或低成本的对抗性提示,这无法反映攻击者通过重复采样来寻找漏洞的实际情况。这种低估可能导致对LLM安全性的误判。
核心思路:论文的核心思路是利用统计模型从小样本量测量中推断出大规模采样下的攻击成功率。具体来说,论文假设每个样本的攻击成功概率服从Beta分布,并利用Beta分布的性质推导出攻击成功率随采样规模变化的解析缩放律。通过这种方式,可以使用较少的样本来预测大规模采样下的风险,从而降低评估成本。
技术框架:SABER方法的整体框架包括以下几个步骤:1)使用小规模采样(例如n=100)对LLM进行对抗性测试,记录每个样本的攻击成功情况;2)利用这些样本数据估计Beta分布的参数,即成功概率的先验分布;3)根据推导出的解析缩放律,利用估计的Beta分布参数预测大规模采样下的攻击成功率。
关键创新:SABER方法的关键创新在于提出了基于Beta分布的样本成功概率建模方法,并推导出了相应的解析缩放律。这种方法能够有效地利用小样本信息来预测大规模采样下的风险,从而降低了评估成本。与现有方法相比,SABER方法更加高效和准确。
关键设计:SABER方法中,Beta分布的选择是关键设计之一,因为它与伯努利分布共轭,便于进行参数估计和推导解析解。此外,解析缩放律的推导也依赖于Beta分布的性质。论文中没有明确提及具体的参数设置或损失函数,因为该方法主要依赖于统计推断而非模型训练。
🖼️ 关键图片

📊 实验亮点
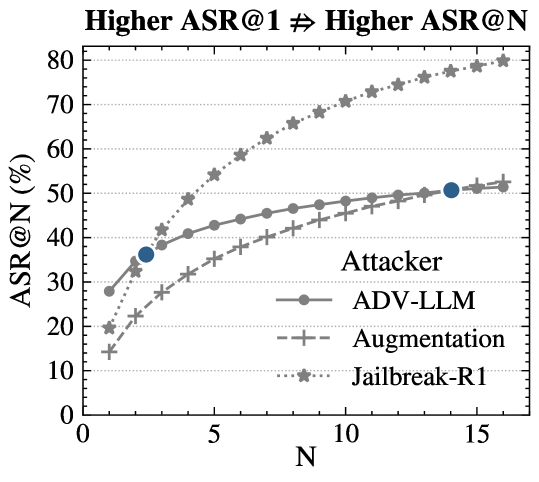
SABER方法在预测大规模采样攻击成功率方面表现出色。实验结果表明,仅使用100个样本,SABER方法预测ASR@1000的平均绝对误差为1.66,而基线的平均绝对误差为12.04,误差降低了86.2%。这表明SABER方法能够以较低的成本实现准确的风险评估,并揭示了模型在并行对抗压力下的非线性风险放大现象。
🎯 应用场景
SABER方法可用于LLM的安全评估和风险管理,帮助开发者和用户更好地了解模型在实际攻击场景下的脆弱性。该方法能够以较低的成本预测大规模采样攻击下的风险,从而为模型安全加固提供指导,并降低潜在的安全风险。此外,该方法还可以用于比较不同LLM的安全性能,为用户选择合适的模型提供参考。
📄 摘要(原文)
Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research.