EntroCut: Entropy-Guided Adaptive Truncation for Efficient Chain-of-Thought Reasoning in Small-scale Large Reasoning Models
作者: Hongxi Yan, Qingjie Liu, Yunhong Wang
分类: cs.AI
发布日期: 2026-01-30
备注: Accepted by ICASSP26
💡 一句话要点
提出EntroCut,通过熵引导自适应截断提升小规模LRM的CoT推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 思维链 动态截断 熵值 效率优化
📋 核心要点
- 大型推理模型计算成本高昂,冗长的中间步骤导致效率低下。
- EntroCut利用早期推理步骤的输出熵来动态截断推理过程。
- 实验表明,EntroCut在保证精度的情况下,显著降低了token使用量。
📝 摘要(中文)
大型推理模型(LRM)通过扩展的思维链生成在复杂推理任务中表现出色,但它们对冗长的中间步骤的依赖导致了巨大的计算成本。我们发现,模型在早期推理步骤中输出分布的熵能够可靠地区分正确和不正确的推理。受此观察的启发,我们提出EntroCut,一种无需训练的方法,通过识别可以安全终止推理的高置信度状态来动态截断推理。为了全面评估效率和准确性之间的权衡,我们引入了效率-性能比(EPR),这是一个统一的指标,用于量化每个单位精度损失的相对token节省。在四个基准测试上的实验表明,EntroCut在精度损失最小的情况下,最多可减少40%的token使用量,与现有的无训练方法相比,实现了卓越的效率-性能权衡。这些结果表明,熵引导的动态截断为缓解LRM的低效率提供了一种实用的方法。
🔬 方法详解
问题定义:大型推理模型(LRM)在复杂推理任务中表现出色,但其思维链(Chain-of-Thought, CoT)推理过程需要生成大量的中间步骤,导致计算成本非常高昂。现有的方法要么需要额外的训练,要么截断策略不够灵活,无法在效率和准确性之间取得良好的平衡。
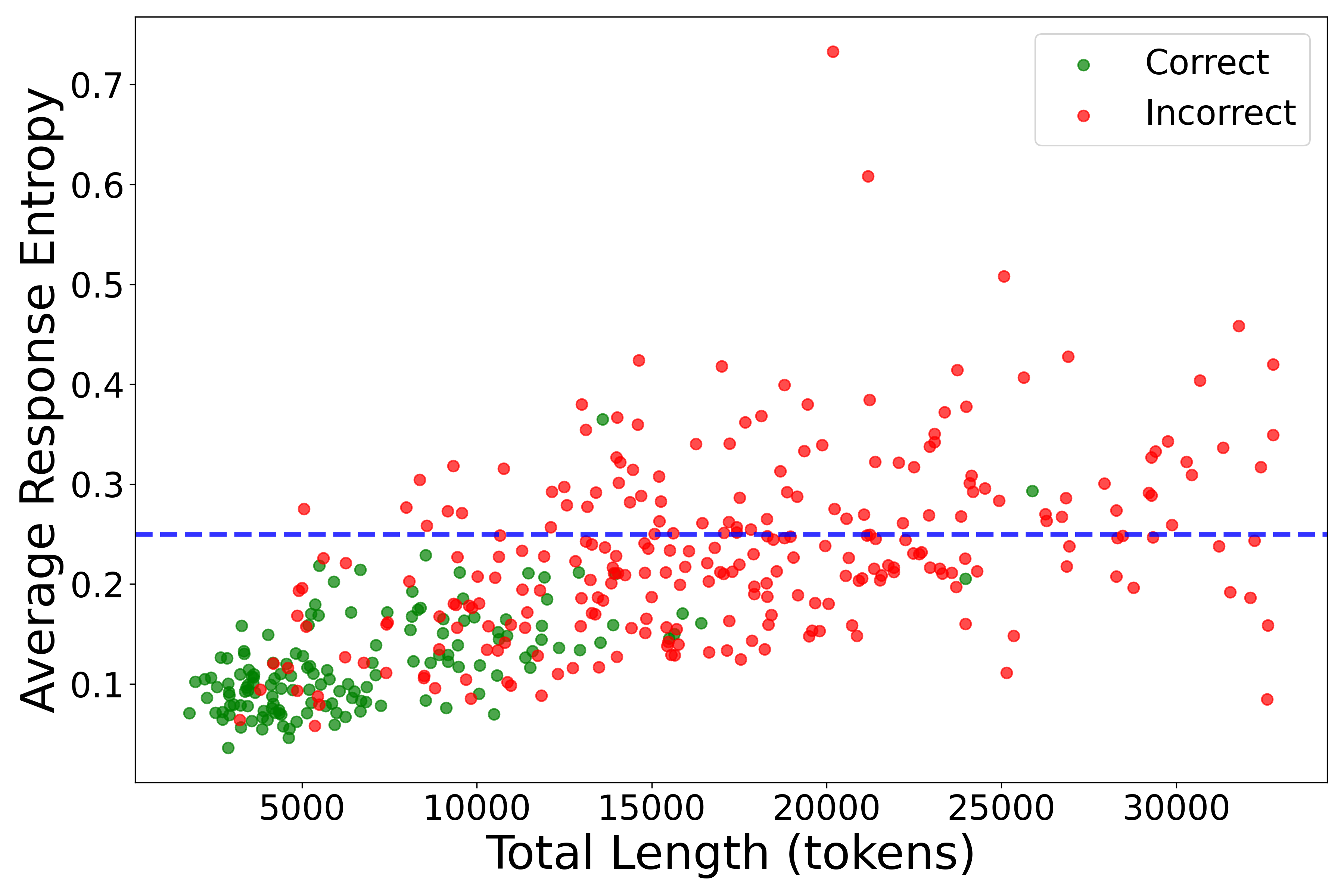
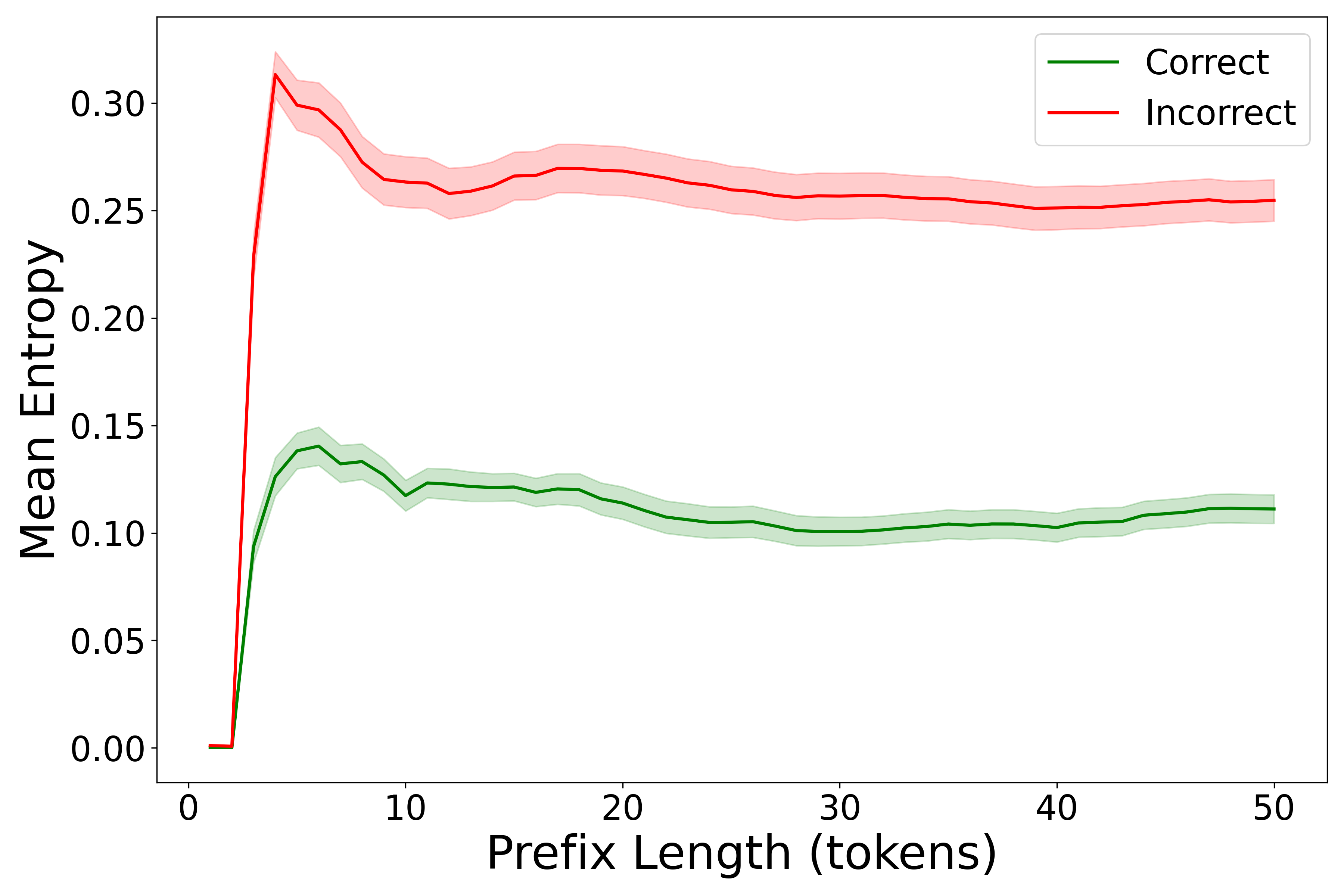
核心思路:论文的核心思路是观察到LRM在CoT推理的早期阶段,如果推理正确,其输出分布的熵值通常较低,反之则较高。因此,可以通过监控模型输出分布的熵值,来判断当前推理状态的置信度,并据此动态地决定是否可以提前终止推理。
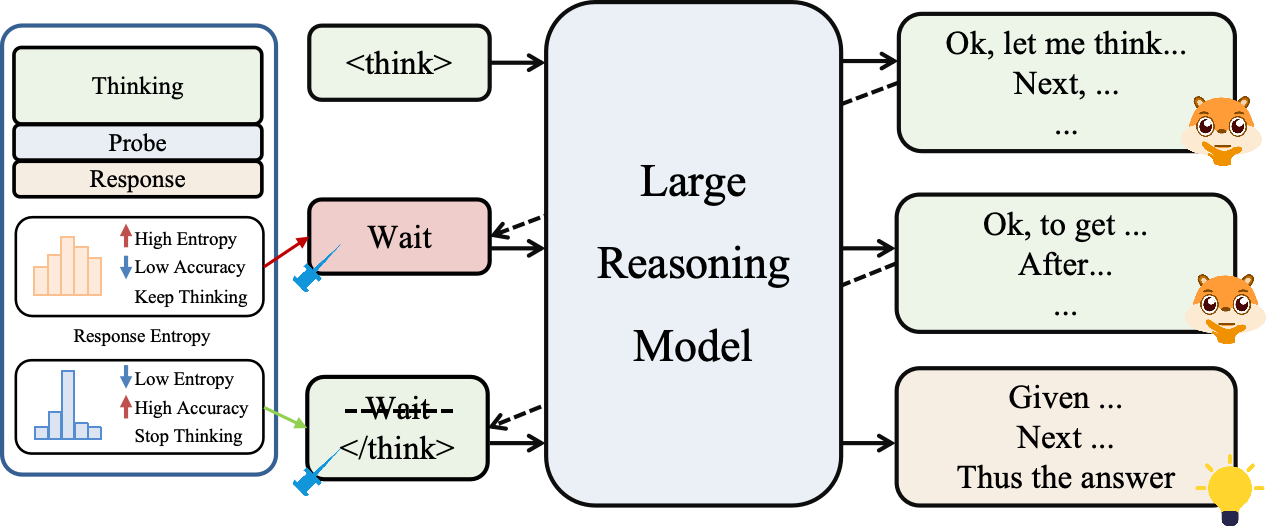
技术框架:EntroCut方法主要包含以下几个阶段:1) LRM执行CoT推理,生成中间步骤;2) 在每个推理步骤,计算模型输出分布的熵值;3) 将计算得到的熵值与预设的阈值进行比较;4) 如果熵值低于阈值,则认为当前推理状态置信度高,可以安全终止推理,否则继续执行推理;5) 输出最终结果。
关键创新:EntroCut的关键创新在于提出了一种基于熵值的动态截断策略,无需额外的训练数据或模型微调。它利用了模型自身在推理过程中产生的置信度信息,实现了一种自适应的推理过程控制。与固定长度截断或需要训练的方法相比,EntroCut更加灵活高效。
关键设计:EntroCut的关键设计在于熵阈值的选择。论文中可能采用了固定的阈值,或者根据不同的任务和模型,通过实验确定最佳阈值。此外,论文还提出了效率-性能比(EPR)作为评估指标,用于综合衡量效率提升和精度损失之间的权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EntroCut在四个基准测试上,能够在精度损失最小的情况下,最多减少40%的token使用量。与现有的无训练方法相比,EntroCut在效率-性能比(EPR)上取得了显著的提升,证明了其在降低计算成本和保持推理准确性方面的有效性。
🎯 应用场景
EntroCut可应用于各种需要使用大型推理模型的场景,例如问答系统、对话系统、代码生成等。通过降低计算成本,EntroCut使得在资源受限的环境中部署和使用LRM成为可能,加速了LRM在实际应用中的普及。该方法还可以用于提升推理速度,改善用户体验。
📄 摘要(原文)
Large Reasoning Models (LRMs) excel at complex reasoning tasks through extended chain-of-thought generation, but their reliance on lengthy intermediate steps incurs substantial computational cost. We find that the entropy of the model's output distribution in early reasoning steps reliably distinguishes correct from incorrect reasoning. Motivated by this observation, we propose EntroCut, a training-free method that dynamically truncates reasoning by identifying high-confidence states where reasoning can be safely terminated. To comprehensively evaluate the trade-off between efficiency and accuracy, we introduce the Efficiency-Performance Ratio (EPR), a unified metric that quantifies relative token savings per unit accuracy loss. Experiments on four benchmarks show that EntroCut reduces token usage by up to 40\% with minimal accuracy sacrifice, achieving superior efficiency-performance trade-offs compared with existing training-free methods. These results demonstrate that entropy-guided dynamic truncation provides a practical approach to mitigate the inefficiency of LRMs.